自去年推出 以来,“英语通用句子编码器 (USE) ”已成为Tensorflow Hub中下载次数最多的预训练文本模块之一,它提供了多功能的句子嵌入模型,可将句子转换为向量表示。这些向量捕获了丰富的语义信息,可用于训练分类器以执行广泛的下游任务。例如,强情绪分类器可以从少至一百个标记示例中进行训练,并且仍然可用于测量语义相似性和基于含义的聚类。
今天,我们很高兴地宣布发布三个新的 USE 多语言模块,它们具有附加功能和潜在应用。前两个模块提供了用于检索语义相似文本的多语言模型,一个针对检索性能进行了优化,另一个针对速度和更少的内存使用进行了优化。第三个模型专门用于十六种语言的问答检索(USE-QA),代表了 USE 的全新应用。所有三个多语言模块均使用多任务双编码器框架进行训练,类似于原始的英语 USE 模型,同时使用我们开发的用于改进双编码器和附加边际 softmax 方法的技术。它们不仅可以保持良好的迁移学习性能,而且可以在语义检索任务上表现出色。
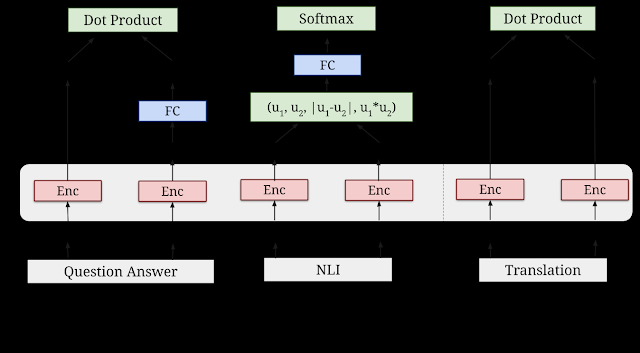
通用句子编码器的多任务训练结构。各种任务和任务结构通过共享的编码器层/参数(粉色框)连接起来。
语义检索应用
这三个新模块均建立在语义检索架构上,这种架构通常将问题和答案的编码分成单独的神经网络,从而可以在几毫秒内搜索数十亿个潜在答案。使用双编码器进行高效语义检索的关键是预先编码所有候选答案以匹配预期的输入查询,并将其存储在针对解决最近邻问题进行优化的向量数据库中,这样就可以快速搜索大量候选结果并具有良好的准确率和召回率。对于所有三个模块,输入查询随后被编码为一个向量,我们可以在该向量上执行近似最近邻搜索。这样就可以快速找到好的结果,而无需对每个候选结果进行直接查询/候选比较。原型流程如下所示:
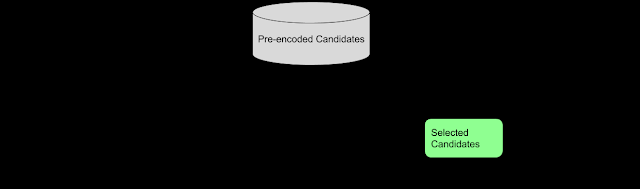
原型语义检索管道,用于文本相似性。
语义相似性模块
对于语义相似性任务,查询和候选使用相同的神经网络进行编码。新模块实现了两种常见的语义检索任务,包括多语言语义文本相似性检索和多语言翻译对检索。
多语言语义文本相似性检索 目前
,大多数查找语义相似文本的方法都需要给定一对文本进行比较。但是,使用通用句子编码器,可以直接从非常大的数据库中提取语义相似的文本。例如,在 FAQ 搜索之类的应用程序中,系统可以首先索引所有可能的问题及其相关答案。然后,给出用户的问题,系统可以搜索语义上足够相似以提供答案的已知问题。类似的方法曾被用于从 wikipedia 中的 5000 万个句子中查找可比较的句子。借助新的多语言 USE 模型,可以使用任何受支持的非英语语言完成此操作。
多语言翻译对检索
新发布的模块还可用于挖掘翻译对,以训练神经机器翻译系统。给定一种语言的源句子(“我怎么去洗手间?”),它们可以找到任何其他受支持语言的潜在翻译目标(“¿Cómo llego al baño?”)。
这两个新的语义相似性模块都是跨语言的。例如,给定一个中文输入,无论使用哪种语言表达,模块都可以找到最佳候选。这种多功能性对于互联网上代表性不足的语言特别有用。例如,Chidambaram 等人 (2018)使用了这些模块的早期版本,在训练数据仅提供一种语言(例如英语),但最终系统必须以多种其他语言运行的情况下提供分类。
用于问答检索的 USE
USE-QA 模块将 USE 架构扩展到问答检索应用程序,该应用程序通常接受输入查询并从可能在文档、段落甚至句子级别建立索引的大量文档中查找相关答案。输入查询使用问题编码网络进行编码,而候选词使用答案编码网络进行编码。
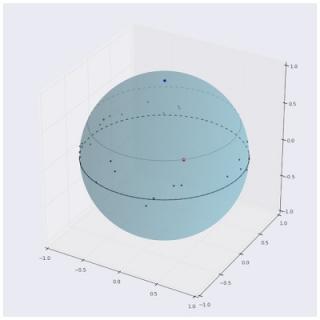
可视化神经答案检索系统的操作。北极的蓝点表示问题向量。其他点表示各种答案的嵌入。正确答案(此处以红色突出显示)与问题“最接近”,因为它最小化了角度距离。此图中的点由实际的 USE-QA 模型生成,但是,它们已从ℝ500 向下投影到ℝ3,以协助读者进行可视化。
问答检索系统也依赖于理解语义的能力。例如,考虑对这样一个系统Google Talk to Books 的可能查询,该系统于 2018 年初推出,由超过 100,000 本书的句子级索引支持。查询“什么香味会勾起回忆? ”,得到的结果是“对我来说,茉莉花的味道和潘巴格纳特的味道,让我回想起了整个无忧无虑的童年。 ”无需指定任何明确的规则或替换,向量编码即可捕获术语“香味”和“气味”之间的语义相似性。USE-QA 模块提供的优势是它可以将此类问答检索任务扩展到多语言应用程序。
对于研究人员和开发人员
我们很高兴与研究界分享通用句子编码器系列的最新成员,并很高兴看到将会发现哪些其他应用程序。这些模块可以按原样使用,也可以使用特定于领域的数据进行微调。最后,我们还将在 Cloud AI Workshop 上托管自然语言语义相似性页面,以进一步鼓励该领域的研究。
致谢
Mandy Guo、Daniel Cer、Noah Constant、Jax Law、Muthuraman Chidambaram 提供核心建模,Gustavo Hernandez Abrego、Chen Chen、Mario Guajardo-Cespedes 提供基础设施和合作实验室,Steve Yuan、Chris Tar、Yunhsuan Sung、Brian Strope、Ray Kurzweil 提供模型架构讨论。
评论