最近,深度学习在一系列具有挑战性的问题上取得了令人瞩目的表现,但它的成功往往依赖于大量手动注释的训练数据。这一限制引发了人们对从更少的示例中学习的兴趣。这个问题的一个研究得很好的例子是少样本图像分类:仅从少数代表性图像中学习新的类别。
从科学角度来看,少样本分类是一个有趣的问题,因为人类从有限信息中学习的能力与深度学习算法的能力明显存在差距;此外,从实践角度来看,少样本分类也是一个非常重要的问题。由于感兴趣的任务通常无法获得大型标记数据集,因此解决这个问题将使我们能够根据个人用户的需求快速定制模型,使机器学习的使用更加民主化。事实上,最近出现了大量解决少样本分类的研究,但之前的基准测试无法可靠地评估不同提议模型的相对优点,从而阻碍了研究进展。
在“元数据集:用于学习从少量示例中学习的数据集的数据集”(在ICLR 2020上发表)中,我们提出了一个大规模且多样化的基准,用于在现实且具有挑战性的少样本设置中衡量不同图像分类模型的能力,提供了一个可以研究少样本分类的几个重要方面的框架。它由 10 个公开的自然图像数据集(包括ImageNet、CUB-200-2011、Fungi等)、手写字符和涂鸦组成。代码是公开的,并包括一个笔记本,演示了如何在TensorFlow和PyTorch中使用元数据集。在这篇博文中,我们概述了对元数据集的初步研究调查的一些结果,并强调了重要的研究方向。
背景:少样本分类
在标准图像分类中,模型在来自特定类别的一组图像上进行训练,然后在相同类别的一组保留图像上进行测试。小样本分类更进一步,研究在测试时对全新类别的概括,这些类别在训练中没有出现过图像。
具体来说,在少样本分类中,训练集包含与测试时出现的类别完全不相交的类别。因此,训练的目的是学习一个灵活的模型,该模型可以轻松地重新用于仅使用几个示例对新类别进行分类。最终目标是在对一系列测试任务进行的测试时评估中表现良好,每个测试任务都提出了一个从保留的测试类集中对以前未见过的类别进行分类的问题。每个测试任务都包含一个由一些标记图像组成的支持集,模型可以从中了解新类别,以及一个不相交的查询示例集,然后要求模型对其进行分类。
在 Meta-Dataset 中,除了上述少样本学习设置中固有的对新类别的艰巨泛化挑战之外,我们还研究了对全新数据集的泛化,在训练中未看到任何类别的图像。Meta
-Dataset 与以前基准的比较
用于研究少样本分类的流行数据集是mini-ImageNet ,它是ImageNet中类别子集的下采样版本。该数据集总共包含 100 个类,分为训练、验证和测试类。虽然在 mini-ImageNet 等基准测试中在测试时遇到的类在训练期间没有见过,但它们在视觉上仍然与训练类基本相似。最近的 研究表明,这使得模型只需重新使用在训练时学习到的特征,就可以在测试时表现出色,而不一定展示从支持集中提供给模型的少数示例中学习的能力。相比之下,要在元数据集上表现良好,则需要在训练时吸收不同的信息,并快速调整它以在测试时解决可能来自完全看不见的数据集的截然不同的任务。

来自 mini-ImageNet 的测试任务。每个任务都是之前未见过的(测试)类别之间的分类问题。该模型可以使用新类别的一些带标签示例的支持集来适应手头的任务,然后预测这些新类别的查询示例的标签。评估指标是查询集准确率,在每个任务内和跨任务的示例上取平均值。
虽然其他近期 论文研究了在 mini-ImageNet 上进行训练并在不同数据集上进行评估,但 Meta-Dataset 代表了迄今为止跨数据集、少量样本图像分类的最大规模组织基准。它还引入了一种采样算法,用于生成具有不同特征和难度的任务,通过改变每个任务中的类别数量、每个类别的可用示例数量、引入类别不平衡以及对于某些数据集,改变每个任务的类别之间的相似度。下面显示了 Meta-Dataset 中的一些示例测试任务。

来自 Meta-Dataset 的测试任务。与上面显示的 mini-ImageNet 任务相反,此处的不同任务源自不同数据集(的测试类)。此外,不同任务的类数和支持集大小不同,并且支持集可能存在类不平衡。
对元数据集的初步调查和发现
我们在元数据集上对两种主要的少样本学习模型进行了基准测试:预训练和元学习。
预训练只是使用监督学习在训练集上训练一个分类器(一个神经网络特征提取器,后面跟着一个线性分类器)。然后,可以通过微调预训练的特征提取器和训练新的特定于任务的线性分类器对测试任务的示例进行分类,或者通过最近邻比较来分类,其中每个查询示例的预测是其最近支持示例的标签。尽管在少样本分类文献中这种方法处于“基线”地位,但最近引起了人们的广泛 关注和颇具竞争力的结果。 另一方面,元学习者构建了许多“训练任务”,它们的训练目标明确反映了在使用相关支持集适应每个任务的查询集之后在该任务的查询集上表现良好的目标,捕捉了测试时解决每个测试任务所需的能力。每个训练任务都是通过随机抽取训练类子集和这些类的一些示例来创建的,以充当支持和查询集的角色。 下面,我们总结了在 Meta Dataset 上评估预训练和元学习模型的一些发现:1) 现有方法难以利用异构训练数据源。 我们比较了仅使用 ImageNet 训练类的训练模型(来自预训练和元学习方法)和使用 Meta-Dataset 中数据集的所有训练类的训练模型,以衡量使用更广泛的训练数据集合的泛化增益。我们为此目的挑选了 ImageNet,因为在 ImageNet 上学习到的特征很容易转移到其他数据集。应用于所有模型的评估任务都来自训练中使用的数据集的保留类集,其中至少有两个额外的数据集完全保留用于评估(即,这些数据集中的任何类都没有用于训练)。 人们可能认为,使用更多数据(尽管是异构的)进行训练会在测试集上更好地泛化。然而,情况并非总是如此。具体来说,下图展示了不同模型在 Meta-Dataset 的十个数据集的测试任务上的准确率。我们观察到,在来自手写字符/涂鸦( Omniglot和Quickdraw)的测试任务上的表现
) 在所有数据集上训练时比仅在 ImageNet 上训练时有显著提高。这是合理的,因为这些数据集在视觉上与 ImageNet 有显著差异。然而,对于自然图像数据集的测试任务,仅在 ImageNet 上训练就可以获得类似的准确率,这表明当前的模型无法有效利用异构数据来提高这方面的准确性。
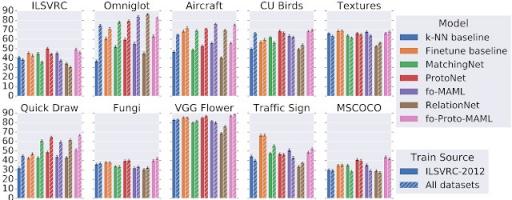
仅在 ImageNet(ILSVRC-2012)或所有数据集上进行训练后,比较每个数据集上的测试性能。
2)某些模型比其他模型更善于在测试时利用额外数据。
我们分析了不同模型的性能与每个测试任务中可用示例数量之间的关系,发现了一个有趣的权衡:不同的模型在特定数量的训练(支持)样本下表现最佳。我们观察到,当可用示例(“样本”)很少时,某些模型的表现优于其他模型(例如ProtoNet和我们提出的fo-Proto-MAML),但在提供更多样本时并没有表现出很大的改进;而其他模型并不适用于示例很少的任务,但随着提供更多样本,改进速度会更快(例如 Finetune 基线)。但是,由于在实践中我们可能无法提前知道测试时可用示例的数量,因此我们希望确定一个能够最好地利用任意数量示例的模型,而不会在特定情况下遭受过度损失。
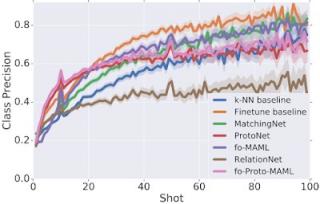
将不同数据集的平均测试性能与测试任务中每个类别可用的示例数量(“镜头”)进行比较。性能以类别精度来衡量:类别中正确标记的示例比例,在各个类别中取平均值。
3) 元学习器的自适应算法对其性能的影响比端到端训练(即元训练)更重要。
我们开发了一套新的基线来衡量元学习的好处。具体来说,对于几个元学习器,我们考虑一个非元学习的对应物,它预先训练一个特征提取器,然后仅在评估时对这些特征应用与相应元学习器相同的自适应算法。当仅在 ImageNet 上进行训练时,元训练通常会有所帮助,或者至少不会造成太大的伤害,但在所有数据集上进行训练时,结果好坏参半。这表明需要进一步研究以理解和改进元学习,尤其是跨数据集的元学习。
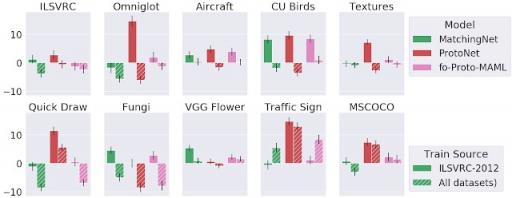
仅在 ImageNet (ILSVRC-1012) 或所有数据集上进行训练时,将三种不同的元学习器变体与其相应的仅推理基线进行比较。每个条形代表元训练和仅推理之间的差异,因此正值表示元训练的性能有所提高。
结论
Meta-Dataset 为小样本分类带来了新的挑战。我们最初的探索揭示了现有方法的局限性,需要进一步研究。最近的研究已经报告了有关 Meta-Dataset 的令人兴奋的结果,例如使用巧妙设计的任务 条件、更复杂的超参数调整、结合预训练和元学习优点的“元基线”,以及最后使用特征选择为每个任务专门化一个通用表示。我们希望 Meta-Dataset 将有助于推动这一重要机器学习子领域的研究。
致谢
Meta-Dataset 由 Eleni Triantafillou、Tyler Zhu、Vincent Dumoulin、Pascal Lamblin、Utku Evci、Kelvin Xu、Ross Goroshin、Carles Gelada、Kevin Swersky、Pierre-Antoine Manzagol 和 Hugo Larochelle 开发。我们要感谢 Pablo Castro 对这篇博文的宝贵指导、Chelsea Finn 富有成效的讨论并确保 fo-MAML 实施的正确性,以及 Zack Nado 和 Dan Moldovan 改编的初始数据集代码、Cristina Vasconcelos 发现模型排名中的问题,以及 John Bronskill 建议我们尝试使用更大的 MAML 内循环学习率,这确实显着改善了我们的 fo-MAML 结果。
评论