理解泛化是深度学习中尚未解决的基本问题之一。为什么在有限的训练数据 集上优化模型会在保留的测试集上取得良好的表现?这个问题在机器学习中得到了广泛的研究,其历史可以追溯到 50 多年前。现在有许多数学 工具可以帮助研究人员理解某些模型中的泛化。不幸的是,大多数现有理论在应用于现代深度网络时都失败了——它们在现实环境中既空洞又不具有预测性。理论与实践之间的这种差距在过度参数化的模型中最大,这些模型在理论上有能力过度拟合其训练集,但在实践中往往不会。
在ICLR 2021接受的论文 “深度 Bootstrap 框架:优秀的在线学习者就是优秀的离线泛化者”中,我们提出了一个解决这个问题的新框架,将泛化与在线优化领域联系起来。在典型设置中,模型在有限的样本集上进行训练,这些样本集会在多个时期内重复使用。但在在线优化中,模型可以访问无限的样本流,并且可以在处理该样本流时进行迭代更新。在这项工作中,我们发现,在无限数据上快速训练的模型与在有限数据上训练的模型具有相同的泛化能力。这种联系为实践中的设计选择带来了新的视角,并为从理论角度理解泛化奠定了路线图。
Deep Bootstrap 框架
Deep Bootstrap 框架的主要思想是将现实世界(其中训练数据有限)与“理想世界”(其中数据无限)进行比较。我们将其定义为:
真实世界 (N, T): 使用来自分布的N 个训练样本训练模型,进行T个小批量随机梯度下降 (SGD) 步骤,像往常一样在多个时期重复使用相同的N 个样本。这相当于在经验损失(训练数据损失)上运行 SGD,并且是监督学习中的标准训练程序。
理想世界 (T):训练同一个模型T步,但在每个 SGD 步中使用分布中的新样本。也就是说,我们运行完全相同的训练代码(相同的优化器、学习率、批大小等),但在每个时期都抽取一个新的训练集,而不是重复使用样本。在这个理想世界设置中,由于“训练集”实际上是无限的,因此训练误差和测试误差之间没有区别。
在 ResNet-18 架构的 SGD 迭代过程中测试理想世界和现实世界的软错误。我们发现这两个错误是相似的。
先验地,人们可能认为现实世界和理想世界可能毫无关联,因为在现实世界中,模型看到的是分布中有限数量的示例,而在理想世界中,模型看到的是整个分布。但在实践中,我们发现现实和理想模型实际上具有相似的测试误差。
为了量化这一观察结果,我们通过创建一个新的数据集(我们称之为CIFAR-5m)模拟了一个理想世界设置。我们在CIFAR-10上训练了一个生成模型,然后使用它生成了约 600 万张图像。数据集的规模经过精心选择,以确保从模型的角度来看它是“几乎无限的”,这样模型就不会对相同的数据进行重新采样。也就是说,在理想世界中,模型看到的是一组全新的样本。

来自 CIFAR-5m 的样本
下图显示了几种模型的测试误差,比较了它们在现实世界(即重复使用的数据)和理想世界(“新鲜”数据)中对 CIFAR-5m 数据进行训练时的性能。实线蓝线显示了现实世界中的ResNet模型,使用标准 CIFAR-10 超参数对 50K 个样本进行了 100 次训练。虚线蓝线显示了理想世界中的相应模型,一次训练了 500 万个样本。令人惊讶的是,这些世界的测试误差非常相似——从某种意义上说,模型“并不关心”它看到的是重复使用的样本还是新鲜样本。
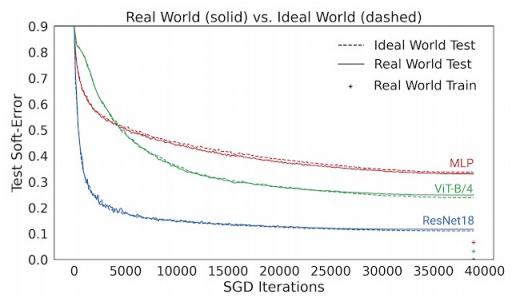
真实世界模型在 50K 样本上训练了 100 个周期,理想世界模型在 5M 样本上训练了一个周期。线条显示了测试误差与 SGD 步数的关系。
这也适用于其他架构,例如多层感知器(红色)、视觉变换器(绿色),以及架构、优化器、数据分布和样本大小的许多其他设置。这些实验提出了一个关于泛化的新视角:快速优化(在无限数据上)的模型,泛化效果好(在有限数据上)。例如,ResNet 模型在有限数据上的泛化效果比 MLP 模型更好,但这是“因为”它即使在无限数据上也能更快地优化。
从优化行为理解泛化
关键观察是,现实世界和理想世界模型在所有时间步的测试误差中保持接近,直到现实世界收敛(<1%训练误差)。因此,人们可以通过研究理想世界中的相应行为来研究现实世界中的模型。
这意味着,可以从两个框架下的优化性能来理解模型的泛化:
在线优化:理想情况下测试误差下降的速度有多快
离线优化:现实世界中的训练误差收敛速度有多快
因此,为了研究泛化,我们可以等效地研究上述两个术语,这在概念上可能更简单,因为它们只涉及优化问题。基于这一观察,好的模型和训练程序是:(1) 在理想世界中快速优化,(2) 在现实世界中优化速度不会太快。
深度学习中的所有设计选择都可以通过它们对这两个术语的影响来查看。例如,卷积、跳过连接和预训练等一些进步主要通过加速理想世界优化来提供帮助,而正则化和数据增强等其他进步主要通过减缓真实世界优化来提供帮助。
应用 Deep Bootstrap 框架
研究人员可以使用 Deep Bootstrap 框架来研究和指导深度学习的设计选择。其原则是:每当做出影响现实世界泛化的改变(架构、学习率等)时,都应考虑其对 (1) 测试误差的理想世界优化(越快越好)和 (2) 训练误差的真实世界优化(越慢越好)的影响。
例如,在实践中,预训练通常用于帮助模型在小数据范围内泛化。然而,预训练之所以有帮助的原因仍然不太清楚。我们可以使用 Deep Bootstrap 框架通过查看预训练对上述术语 (1) 和 (2) 的影响来研究这一点。我们发现预训练的主要作用是改善理想世界优化 (1) — 预训练将网络变成在线优化的“快速学习者”。因此,预训练模型的泛化能力的提高几乎完全可以通过其在理想世界中的优化提高来体现。下图显示了在CIFAR-10上训练的Vision-Transformers (ViT)的情况,比较了从头开始训练与在ImageNet上进行预训练的情况。
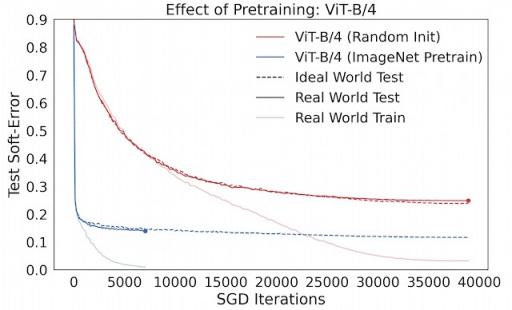
预训练的效果——预训练的ViT在理想世界中优化得更快。
还可以使用此框架研究数据增强。理想世界中的数据增强相当于对每个新样本进行一次增强,而不是对同一样本进行多次增强。此框架意味着良好的数据增强是那些 (1) 不会显著损害理想世界优化(即增强样本看起来不会太“偏离分布”)或 (2) 抑制现实世界优化速度(因此现实世界需要更长的时间来适应其训练集)的数据增强。
数据增强的主要好处是通过第二项,延长现实世界的优化时间。至于第一项,一些激进的数据增强(mixup / cutout)实际上可能会损害理想世界,但这种影响与第二项相比微不足道。
结论
Deep Bootstrap 框架为深度学习中的泛化和经验现象提供了一个新的视角。我们很高兴看到它在未来应用于理解深度学习的其他方面。特别有趣的是,泛化可以通过纯粹的优化考虑来表征,这与许多流行的理论方法形成鲜明对比。至关重要的是,我们同时考虑了在线和离线优化,它们单独来看是不够的,但它们共同决定了泛化。
Deep Bootstrap 框架还可以解释为什么深度学习对许多设计选择都相当稳健:许多类型的架构、损失函数、优化器、规范化和激活 函数都可以很好地推广。该框架提出了一个统一的原则:基本上任何在在线优化设置中运行良好的选择也将在离线设置中很好地推广。
最后,现代神经网络既可以过度参数化(例如,在小 数据 任务上训练的大型网络),也可以参数化不足(例如,OpenAI 的 GPT-3、Google 的 T5或Facebook 的 ResNeXt WSL)。Deep Bootstrap 框架意味着在线优化是两种方案成功的关键因素。
致谢
我们感谢我们的合著者 Behnam Neyshabur 对本文做出的巨大贡献以及在博客上提出的宝贵反馈。我们感谢 Boaz Barak、Chenyang Yuan 和 Chiyuan Zhang 对博客和本文提出的有益评论。
评论