印度拥有全球第二大互联网用户群,近 75% 的人口主要使用印度语言而非英语上网。未来五年,这一数字预计将上升至 90%。为了让下一个十亿用户尽可能方便地使用 Google 地图,它必须允许人们以自己喜欢的语言使用它,使他们能够探索世界任何地方。
然而,Google 地图上大多数印度景点 (POI) 的名称通常不提供印度语言的母语文字。这些名称通常为英文,可能与基于拉丁文字的首字母缩略词以及印度语言单词和名称相结合。解决此类混合语言表示需要音译系统,该系统根据源语言和目标语言将字符从一种文字映射到另一种文字,同时考虑单词的语音属性。
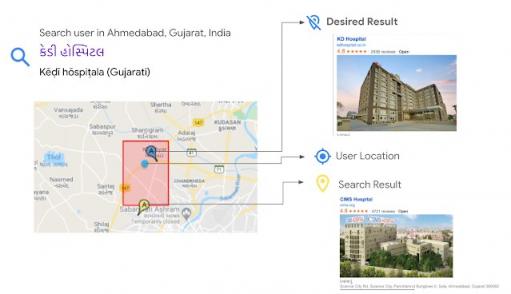
例如,假设一位来自古吉拉特邦艾哈迈达巴德的用户正在寻找附近的医院 KD 医院。他们使用印度第六大语言古吉拉特语的母语发出搜索查询 કેડી હોસ્પિટલ。其中,કેડી(“ kay-dee ”)是首字母缩略词 KD 的发音,હોસ્પિટલ 是“医院”。在此搜索中,Google 地图知道要查找医院,但它不明白 કેડી 是 KD,因此它找到了另一家医院 CIMS。由于印度古吉拉特语中可用的名胜古迹 (POI) 名称相对稀少,因此向用户展示的结果并不是他们想要的,而是较远的。
为了应对这一挑战,我们构建了一套学习模型,将拉丁字母 POI 的名称音译成印度流行的 10 种语言:印地语、孟加拉语、马拉地语、泰卢固语、泰米尔语、古吉拉特语、卡纳达语、马拉雅拉姆语、旁遮普语和奥迪亚语。利用这套模型,我们已将这些语言的名称添加到印度数百万个 POI 中,将某些语言的覆盖范围扩大了近 20 倍。这将立即惠及数百万不说英语的现有印度用户,使他们能够用自己的语言找到医生、医院、杂货店、银行、公交车站、火车站和其他基本服务。
音译、转录和翻译
我们的目标是设计一个系统,将参考拉丁文字名称音译为上述语言的本土文字和正字法。例如,梵文是印地语和马拉地语(马哈拉施特拉邦纳格浦尔的本土语言)的本土文字。将NIT Garden和Chandramani Garden的拉丁文字名称音译为纳格浦尔的两个兴趣点,结果分别为 एनआईटी गार्डन 和 चंद्रमणी गार्डन,具体取决于该文字中特定语言的正字法。
值得注意的是,音译的 POI 名称不是翻译。音译只涉及用不同的文字书写相同的单词,就像英语报纸可能会选择将西里尔文字中的 Горбачёв 写成“Gorbachev”,以便让不懂西里尔文字的读者阅读。例如,上述两个音译的 POI 名称中的第二个单词仍发音为“garden”,而之前古吉拉特语示例中的第二个单词仍为“hospital”——它们仍然是英语单词“garden”和“hospital”,只是用另一种文字书写。事实上,在印度,即使以本土文字书写,POI 名称中也经常使用常见的英语单词。这些文字中名称的书写方式很大程度上取决于其发音;因此,首字母缩略词NIT中的 एनआईटी发音为“ en-aye-tee ”,而不是英语单词“ nit ”。了解 NIT 是该地区的常用缩写词是可以用来推导正确音译的证据之一。
还请注意,虽然我们使用“音译” 一词,遵循 NLP 社区的惯例,直接在书写系统之间进行映射,但南亚语言中的罗马化(无论使用哪种文字)通常都是由发音驱动的,因此人们可以将这些方法称为转录而不是音译。然而,任务仍然是在文字之间进行映射,因为对于这些语言,拉丁文字只能相对粗略地捕捉发音,并且仍有许多文字特定的对应关系需要考虑。再加上拉丁文字缺乏标准拼写以及由此产生的多变性,使得这项任务具有挑战性。
音译合奏团
我们使用一组模型将参考拉丁文字名称(例如NIT Garden或Chandramani Garden)自动转写为上述语言的本土文字和正字法。候选音译来自一对序列到序列 (seq2seq) 模型。一个是用于一般文本音译的有限状态模型,其训练方式与Gboard 设备上用于音译键盘的模型类似。另一个是神经 长短期记忆(LSTM) 模型,部分模型基于公开发布的Dakshina 数据集进行训练。该数据集包含从维基百科中提取的 12 种南亚语言的拉丁文和本土文字数据,包括上述除一种语言以外的所有语言,并允许训练和评估各种音译方法。由于这两个模型具有如此不同的特点,因此它们结合在一起可以产生更多种类的音译候选项。
为了处理首字母缩略词的棘手现象(例如上面的“NIT”和“KD”的例子),我们开发了一个专门的音译模块,可以为这些情况生成额外的候选音译。
对于每种母语文字,该集合都使用不同来源的专门罗马化词典,这些词典针对地名、专有名词或常用词量身定制。此类罗马化词典的示例可在达克希纳语数据集中找到。
合奏中的得分
该集成将可能的音译的得分组合成加权混合,其参数专门针对 POI 名称的准确性进行调整,使用针对此类名称的小型目标开发集。
对于候选音译中的每个母语文字标记,该集成还会根据其在大量在线文本样本中出现的频率对结果进行加权。额外的候选评分基于源自ISO 15919罗马化标准的确定性罗马化方法,该方法将每个母语文字标记映射到一个唯一的拉丁文字字符串。该字符串允许集成在与被音译的原始拉丁文字标记进行比较时跟踪某些关键对应关系,即使 ISO 衍生的映射本身并不总是完全符合给定母语文字单词在拉丁文字中的通常书写方式。
总体而言,这些众多活动部件提供的音译质量远远高于任何单独方法所能提供的音译质量。
覆盖范围
下表列出了由于集成了 POI 名称的现有自动音译而导致的每种语言的质量和覆盖率改进。覆盖率改进衡量了已提供自动音译的项目的增加。 质量改进衡量了被判定为改进的更新音译与被判定为不如现有自动音译的更新音译的比例。
覆盖范围 质量
语言 改进 改进
印地语 3.2x 1.8x
孟加拉 19x 3.3x
马拉地语 19x 2.9x
泰卢固语 3.9x 2.6倍
泰米尔语 19x 3.6倍
古吉拉特语 19x 2.5 倍
卡纳达语 24倍 2.3x
马拉雅拉姆语 24倍 1.7倍
奥迪亚语 960x — *
旁遮普语 24倍 — *
* 未知/无基线。
结论
与任何机器学习系统一样,自动音译结果可能包含一些错误或不当之处,但这些广泛使用的语言覆盖范围的大幅增加标志着 Google 地图在印度的信息可访问性大幅提升。未来的工作将包括使用该集成音译地图中其他类别的实体,并将其扩展到其他语言和文字,包括波斯-阿拉伯文字,这些文字在该地区也很常用。
致谢
这项工作是作者与 Jacob Farner、Jonathan Herbert、Anna Katanova、Andre Lebedev、Chris Miles、Brian Roark、Anurag Sharma、Kevin Wang、Andy Wildenberg 等人合作的成果。
评论