机器学习 (ML) 模型的训练数据的质量会对其性能产生重大影响。数据质量的一个衡量标准是影响力,即给定训练示例对模型及其预测性能的影响程度。虽然影响力是 ML 研究人员所熟知的概念,但深度学习模型背后的复杂性,加上其不断增长的规模、特征和数据集,使得影响力的量化变得困难。
最近提出了几种量化影响的方法。有些方法依赖于在删除一个或多个数据点的情况下进行重新训练时准确度的变化,有些方法使用已建立的统计方法,例如,影响函数估计扰动输入点的影响,或表示方法将预测分解为训练示例的重要性加权组合。还有一些方法需要使用额外的估计器,例如使用强化学习进行数据评估。虽然这些方法在理论上是合理的,但它们在产品中的使用受到大规模运行所需资源或它们对训练造成的额外负担的限制。
在NeurIPS 2020上作为焦点论文发表的 “通过追踪梯度下降估计训练数据影响”中,我们提出了TracIn,这是一种解决这一挑战的简单可扩展方法。TracIn 背后的想法很简单——跟踪训练过程以捕捉在访问单个训练示例时预测的变化。TracIn 可以有效地从各种数据集中查找错误标记的示例和异常值,并且通过为每个训练示例分配影响分数,有助于根据训练示例(而不是特征)解释预测。
TracIn 背后的理念
深度学习算法通常使用一种称为随机梯度下降(SGD) 的算法或其变体进行训练。SGD 通过对数据进行多次传递并修改模型参数来运行,从而在每次传递时局部减少损失(即模型的目标)。下图中的图像分类任务演示了此示例,其中模型的任务是预测左侧测试图像的主题(“西葫芦”)。随着模型的训练进展,它会接触到影响测试图像损失的各种训练示例,其中损失是预测分数和实际标签的函数——西葫芦的预测分数越高,损失越低。
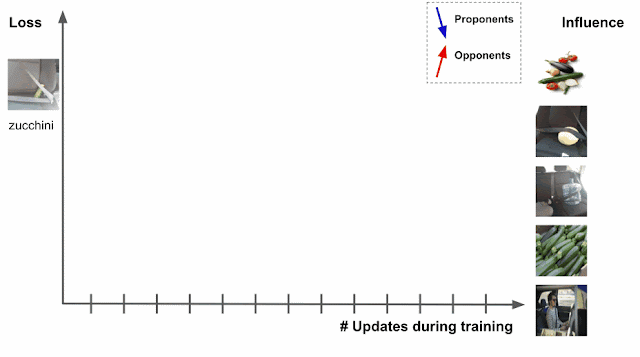
通过追踪训练期间安全带图像中西葫芦的损失变化来估计右侧图像对训练数据的影响。
假设在训练时已知测试示例,并且训练过程一次访问每个训练示例。在训练期间,访问特定训练示例将改变模型的参数,然后该变化将修改测试示例的预测/损失。如果可以通过该过程跟踪训练示例,那么测试示例的损失或预测的变化可以归因于所讨论的训练示例,其中训练示例的影响将是访问训练示例的累积归因。
相关训练示例有两种类型。那些减少损失的示例,如上图的西葫芦图像,被称为支持者,而那些增加损失的示例,如安全带图像,被称为反对者。在上面的例子中,标记为“太阳镜”的图像也是支持者,因为图像中有安全带,但被标记为“太阳镜”,这促使模型更好地区分西葫芦和安全带。
实际上,测试示例在训练时是未知的,可以通过使用学习算法输出的检查点作为训练过程的概述来克服这一限制。另一个挑战是学习算法通常一次访问多个点,而不是单独访问,这需要一种方法来解开每个训练示例的相对贡献。这可以通过应用逐点损失梯度来实现。这两种策略结合起来,就捕获了 TracIn 方法,它可以简化为测试和训练示例的损失梯度的点积的简单形式,由学习率加权,并在检查点之间求和。
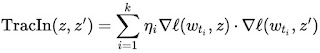
TracIn 影响的简单表达式。训练示例(z)和测试示例(z')的损失梯度的点积由不同检查点的学习率(η i)加权并相加。
或者,也可以检查对预测分数的影响,如果测试示例没有标签,这将很有用。此形式仅要求用预测梯度替换测试示例的损失梯度。
计算顶级影响力示例
我们首先计算一些训练数据和特定分类(变色龙图像)的测试示例的损失梯度向量,然后利用标准k 近邻库检索顶级支持者和反对者,以说明 TracIn 的实用性。顶级反对者表明变色龙融入的能力!为了进行比较,我们还显示了来自倒数第二层的嵌入的k 个最近邻居。支持者是不仅相似而且属于同一类的图像,而反对者是相似但属于不同类的图像。请注意,没有明确规定支持者或反对者是否属于同一类。

上行:影响向量的主要支持者和反对者。下行:倒数第二层的嵌入向量最相似和最不相似的示例。
聚类
TracIn 将测试示例的损失简化为训练示例的影响,这也表明任何基于梯度下降的神经模型的损失(或预测)都可以表示为梯度空间中相似性的总和。最近的研究表明,这种函数形式类似于核的形式,这意味着这里描述的梯度相似性可以应用于其他相似性任务,例如聚类。
在这种情况下,TracIn 可用作聚类算法中的相似度函数。为了限制相似度度量,以便将其转换为距离度量(1 - 相似度),我们将梯度向量标准化为单位范数。下面,我们将 TracIn 聚类应用于西葫芦图像以获得更精细的聚类。

使用 TracIn 相似性对西葫芦图像进行更精细的聚类。每行都是一个聚类,其中的西葫芦形状相似:横切的西葫芦(顶部)、成堆的西葫芦(中间)和披萨上的西葫芦(底部)。
利用自我影响力识别异常值
最后,我们还可以使用 TracIn 来识别表现出高自影响力的异常值,即训练点对其自身预测的影响。当示例被错误标记或罕见时,就会发生这种情况,这两种情况都会使模型难以对示例进行概括。以下是一些具有高自影响力的示例。

标记错误的示例。指定的标签被划掉,正确的标签位于底部。

左图:一个罕见的示波器示例,只有振荡,图像中没有仪器受到高自影响。右图:其他常见的示波器图像中示波器带有旋钮和电线。这些示波器的自影响较低。
应用
TracIn 除了使用 SGD(或相关变体)进行训练外,没有其他要求,它独立于任务,适用于各种模型。例如,我们使用 TracIn 研究深度学习模型的训练数据,该模型用于解析对 Google Assistant 的查询,查询类型为“将我的闹钟设置为早上 7 点”。我们很惊讶地发现,在设备上激活闹钟的情况下,查询“禁用我的闹钟”的最大对手是“禁用我的计时器”,设备上也激活了闹钟。这表明 Assistant 用户经常互换使用“计时器”和“闹钟”这两个词。TracIn 帮助我们解释了 Assistant 数据。
论文 中可以找到更多示例,包括结构化数据的回归任务和一些文本分类任务。
结论
TracIn 是一种简单、易于实现且可扩展的方法,用于计算训练数据示例对单个预测的影响,或查找罕见和错误标记的训练示例。有关该方法的实现参考,您可以在本文链接的 github 中找到图像代码示例的链接。
致谢
NeurIPS 论文由 Satyen Kale 和 Mukund Sundararajan(通讯作者)共同撰写 。特别感谢 Binbin Xiong 提供各种概念和实施见解。我们还要感谢 Qiqi Yan 和 Salem Haykal 的多次讨论。本文中的图片均来自Getty Images。
评论