无模型强化学习已在一系列领域得到成功展示,包括机器人技术、控制、玩游戏和自动驾驶汽车。这些系统通过简单的反复试验进行学习,因此在解决给定任务之前需要进行大量尝试。相比之下,基于模型的强化学习(MBRL) 学习环境模型(通常称为世界模型或动态模型),使代理能够预测潜在动作的结果,从而减少解决任务所需的环境交互量。
原则上,规划所严格需要做的就是预测未来的奖励,然后可以使用该奖励选择接近最优的未来行动。尽管如此,许多最近的方法,例如Dreamer、PlaNet和SimPLe ,还利用了预测未来图像的训练信号。但预测未来图像真的有必要吗?或者有帮助吗?视觉 MBRL 算法实际上从预测未来图像中获得什么好处?预测整个图像的计算和表示成本相当大,因此了解这是否真的有用对于 MBRL 研究至关重要。
在“模型、像素和奖励:评估基于视觉模型的强化学习中的设计权衡”中,我们证明了预测未来图像具有显著优势,并且实际上是训练成功的视觉 MBRL 代理的关键因素。我们开发了一个新的开源库,称为世界模型库,它使我们能够严格评估各种世界模型设计,以确定图像预测对每个模型返回奖励的相对影响。
世界模型库
世界模型库专为视觉 MBRL 训练和评估而设计,可以对每个设计决策对代理在大规模多个任务中的最终表现的影响进行实证研究。该库引入了与平台无关的视觉 MBRL 模拟循环和 API,可以无缝定义新的世界模型、规划器和任务,也可以从现有目录中进行选择,其中包括代理(例如PlaNet)、视频模型(例如SV2P)以及各种DeepMind 控制任务和规划器,例如CEM和MPPI。
使用该库,开发人员可以研究 MBRL 中各种因素(例如模型设计或表示空间)对代理在一系列任务上的表现的影响。该库支持从头开始训练代理,或基于预先收集的一组轨迹训练代理,以及对给定任务上预先训练的代理进行评估。模型、规划算法和任务可以轻松混合和匹配成任何所需的组合。
为了给用户提供最大的灵活性,该库使用NumPy接口 构建,这使得不同的组件可以在TensorFlow、Pytorch或JAX中实现。请查看此 colab以快速了解。
图像预测的影响
使用 World Models Library,我们训练了多个具有不同图像预测级别的 World Models。所有这些模型都使用相同的输入(之前观察到的图像)来预测图像和奖励,但它们在预测图像的百分比上有所不同。随着代理预测的图像像素数量的增加,以真实奖励衡量的代理性能通常会提高。
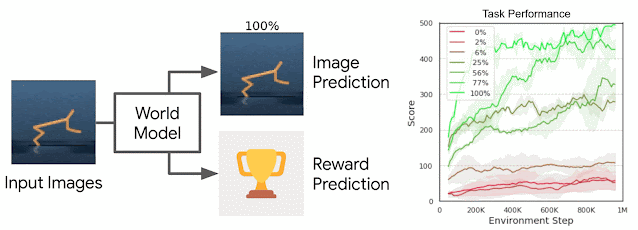
模型的输入是固定的(之前观察到的图像),但预测的图像比例会发生变化。如右图所示,增加预测像素的数量可显著提高模型的性能。
有趣的是,奖励预测准确率和代理表现之间的相关性并不那么强,在某些情况下,更准确的奖励预测甚至会导致代理表现更差。同时,图像重建误差和代理的表现之间存在很强的相关性。
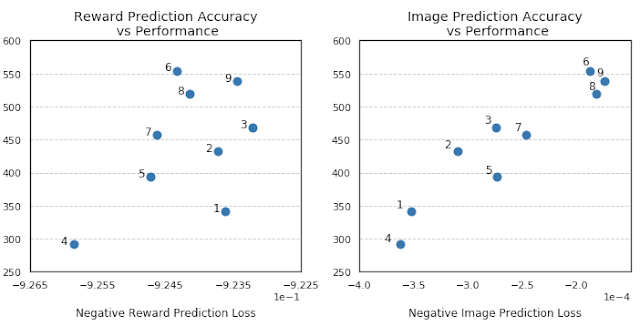
图像/奖励预测准确度(x 轴)与任务表现(y 轴)之间的相关性。该图清楚地表明了图像预测准确度与任务表现之间的更强相关性。
这种现象与探索直接相关, 即当代理尝试更具风险且可能回报更少的操作以收集有关环境中未知选项的更多信息时。这可以通过在离线设置中测试和比较模型来证明(即从预先收集的数据集中学习策略,而不是通过与环境交互来学习策略的在线RL)。离线设置可确保没有探索,并且所有模型都在相同的数据上进行训练。我们观察到,更适合数据的模型通常在离线设置下表现更好,令人惊讶的是,这些模型可能与从头开始学习和探索时表现最好的模型不同。
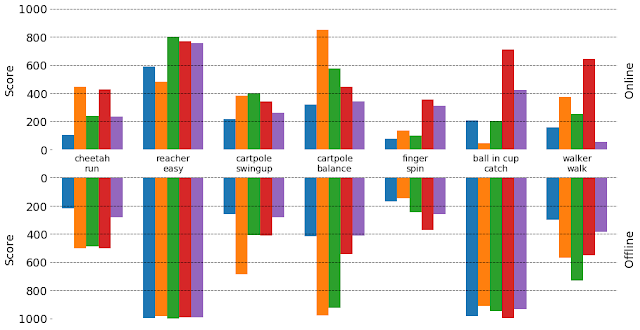
不同可视化 MBRL 模型在不同任务中获得的分数。图表的上半部分和下半部分分别显示了在每项任务的在线和离线设置下训练时获得的分数。每种颜色代表不同的模型。在线设置下表现不佳的模型在对预先收集的数据(离线设置)进行训练时获得高分是很常见的,反之亦然。
结论
我们通过实证研究证明,与仅预测预期奖励的模型相比,预测图像可以显著提高任务绩效。我们还表明,图像预测的准确性与这些模型的最终任务绩效密切相关。这些发现可用于更好的模型设计,并且对于输入空间为高维且收集数据成本高昂的任何未来设置都特别有用。
如果您想开发自己的模型和实验,请前往我们的存储库和合作实验室,在那里您可以找到有关如何重现这项工作以及使用或扩展世界模型库的说明。
致谢:
我们要特别感谢 Google Brain 团队的多位研究人员和论文的合著者:Mohammad Taghi Saffar、Danijar Hafner、Harini Kannan、Chelsea Finn 和 Sergey Levine。
评论