识别文本蕴涵 的任务,也称为自然语言推理,包括确定一段文本(前提)是否可以被另一段文本(假设)暗示或反驳(或两者都不暗示或反驳)。虽然这个问题通常被认为是机器学习 (ML) 系统推理能力的重要测试,并且已经针对纯文本输入进行了深入研究,但在将此类模型应用于结构化数据(如网站、表格、数据库等)方面投入的努力却少得多。然而,当需要准确地总结表格内容并呈现给用户时,识别文本蕴涵尤其重要,并且对于高保真问答系统和虚拟助手至关重要。
在《EMNLP 2020 发现》中发表的 “通过中级预训练理解表格”中,我们介绍了第一个为表格解析定制的预训练任务,使模型能够从更少的数据中更好、更快地学习。我们在早期的TAPAS模型的基础上进行构建,该模型是BERT双向Transformer模型的扩展,具有特殊的嵌入以在表格中查找答案。将我们的新预训练目标应用于 TAPAS 可在涉及表格的多个数据集上产生新的最先进水平。例如,在TabFact上,它将模型与人类表现之间的差距缩小了约 50%。我们还系统地对选择相关输入的方法进行了基准测试,以提高效率,在速度和内存方面实现了 4 倍的提升,同时保留了 92% 的结果。所有针对不同任务和大小的模型都发布在GitHub repo上,您可以在colab Notebook中亲自试用它们。
文本蕴涵
文本蕴涵的任务在应用于表格数据时比应用于纯文本更具挑战性。例如,考虑来自维基百科的一张表格,其中有一些句子来自其相关的表格内容。评估表格的内容是否蕴涵或与句子相矛盾可能需要查看多列和多行,并可能执行简单的数值计算,如平均、求和、求差等。
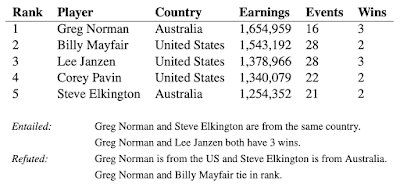
一个表格,其中包含来自TabFact的一些语句。表格的内容可用于支持或反驳这些语句。
按照 TAPAS 使用的方法,我们将语句和表格的内容一起编码,将它们传递给 Transformer 模型,并得到一个数字,该数字表示该语句被表格所蕴含或反驳的概率。
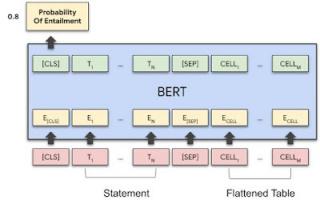
TAPAS模型架构使用 BERT 模型对语句和扁平表进行编码,逐行读取。使用特殊嵌入对表结构进行编码。第一个 token 的向量输出用于预测蕴涵概率。
由于训练示例中的唯一信息是二进制值(即“正确”或“不正确”),训练模型以了解某个语句是否蕴涵是一项挑战,并且凸显了深度学习中实现泛化的难度,尤其是在提供的训练信号稀少的情况下。看到孤立的蕴涵或反驳示例,模型可以轻松拾取数据中的虚假模式来做出预测,例如在“Greg Norman 和 Billy Mayfair 排名并列”中存在单词“tie”,而不是真正比较他们的排名,而这正是成功将模型应用于原始训练数据之外所必需的。
预训练任务
预训练任务可用于“热身”模型,方法是向模型提供大量随时可用的未标记数据。但是,预训练通常主要包括纯文本而不是表格数据。事实上,TAPAS 最初是使用简单的掩码语言建模目标进行预训练的,该目标并非为表格数据应用而设计。为了提高模型在表格数据上的性能,我们引入了两个新的预训练二元分类任务,称为反事实和合成,它们可以作为预训练的第二阶段(通常称为中级预训练)。
在反事实任务中,我们从维基百科中获取提及实体(人、地点或事物)的句子,这些实体也出现在给定的表中。然后,50% 的时间里,我们通过将实体替换为另一个替代方案来修改陈述。为了确保陈述是现实的,我们在表中同一列的实体中选择一个替换。该模型经过训练可以识别陈述是否被修改。这个预训练任务包括数百万个这样的示例,尽管对它们的推理并不复杂,但它们通常听起来仍然很自然。
对于合成任务,我们采用类似于语义解析的方法,使用一组简单的语法规则生成语句,这些规则要求模型理解基本的数学运算,例如求和和求平均值(例如,“收入总和”),或者理解如何使用某些条件过滤表中的元素(例如,“国家是澳大利亚”)。虽然这些语句是人为的,但它们有助于提高模型的数字和逻辑推理能力。

两个新颖的预训练任务的示例实例。反事实示例将输入表附带的句子中提到的实体交换为合理的替代方案。合成语句使用语法规则来创建新的句子,这些新句子需要以复杂的方式组合表格中的信息。
结果
我们通过与基线 TAPAS 模型以及在文本蕴涵领域取得成功的两个先前模型LogicalFactChecker (LFC) 和Structure Aware Transformer (SAT) 进行比较,评估了 TabFact 数据集上反事实和合成预训练目标的成功程度。基线 TAPAS 模型相对于 LFC 和 SAT 表现出了改进的性能,但预训练模型 (TAPAS+CS) 的性能明显更好,达到了新的最佳水平。
我们还将 TAPAS+CS 应用于SQA 数据 集上的问答任务,这要求模型在对话设置中从表格内容中寻找答案。CS 目标的加入将之前的最佳性能提高了 4 分以上,表明这种方法还可以将性能推广到文本蕴涵之外。
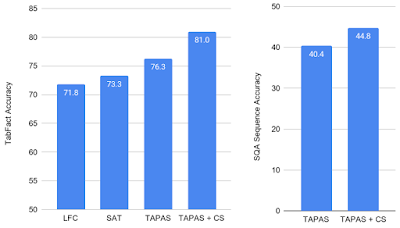
TabFact(左)和 SQA(右)的结果。使用合成和反事实数据集,我们在两个任务中都取得了巨大的新成果。
数据和计算效率
反事实和合成预训练任务的另一个方面是,由于模型已经针对二元分类进行了调整,因此无需对 TabFact 进行任何微调即可应用它们。我们探索了当仅在数据子集(甚至没有)上进行训练时每个模型会发生什么。无需查看任何示例,TAPAS+CS 模型就可以与强大的基线 Table-Bert 相媲美,并且当仅包含 10% 的数据时,结果与之前的最新成果相当。
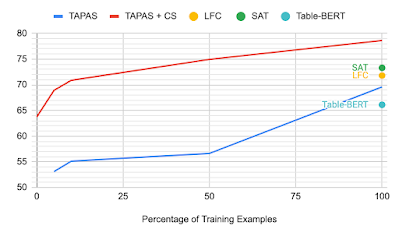
TabFact 上的 Dev 准确度相对于所使用的训练数据的比例。
当尝试使用诸如此类的大型模型来处理表格时,一个普遍的担忧是,它们的高计算要求使得它们很难解析非常大的表格。为了解决这个问题,我们研究是否可以启发式地选择输入的子集来通过模型,以优化其计算效率。
我们对过滤输入的不同方法进行了系统研究,发现选择整列和主题语句之间单词重叠的简单方法可以产生最佳结果。通过动态选择要包含的输入标记,我们可以以相同的成本使用更少的资源或处理更大的输入。挑战在于这样做而不丢失重要信息并损害准确性。
例如,上面讨论的模型都使用 512 个 token 的序列,这大约是 Transformer 模型的正常极限(尽管最近的效率方法,如Reformer或Performer,在扩展输入大小方面被证明是有效的)。我们在此提出的列选择方法可以加快训练速度,同时仍在 TabFact 上实现高精度。对于 256 个输入 token,我们的精度会略有下降,但现在可以对模型进行预训练、微调,并将预测速度提高两倍。使用 128 个 token,该模型仍然优于之前最先进的模型,速度提升更为显著——全面提升了 4 倍。
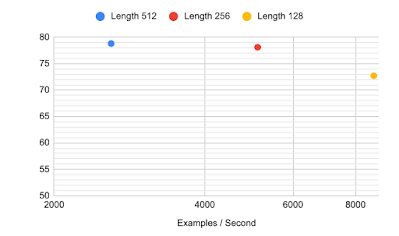
通过使用我们的列选择方法缩短输入,使用不同序列长度的 TabFact 的准确性。
利用我们提出的列选择方法和新颖的预训练任务,我们可以创建需要更少数据和更少计算能力来获得更好结果的表解析模型。
我们在GitHub 存储库 中提供了新模型和预训练技术,您可以在colab中亲自尝试。为了使这种方法更容易使用,我们还分享了不同大小的模型,最小到“微型”。我们希望这些结果将有助于促进更广泛的研究社区对表格推理的开发。
致谢
这项工作由我们苏黎世语言团队的 Julian Martin Eisenschlos、Syrine Krichene 和 Thomas Müller 完成。我们感谢 Jordan Boyd-Graber、Yasemin Altun、Emily Pitler、Benjamin Boerschinger、Srini Narayanan、Slav Petrov、William Cohen 和 Jonathan Herzig 提供的有益评论和建议。
评论