深度强化学习 (RL) 使人工智能代理能够随着时间的推移改进其决策。传统的无模型方法通过大量反复试验与环境交互来了解哪些动作在不同情况下是成功的。相比之下,深度强化学习的最新进展使基于模型的方法能够从图像输入中学习准确的世界模型并将其用于规划。世界模型可以从更少的交互中学习,促进从离线数据中进行泛化,实现前瞻性探索,并允许在多个任务中重复使用知识。
尽管现有的世界模型(如SimPLe)有着吸引人的优势,但它还不够精确,无法在最具竞争力的强化学习基准上与顶尖的无模型方法相媲美——迄今为止,完善的Atari 基准需要无模型算法(如DQN、IQN和Rainbow)才能达到人类水平的表现。 因此,许多研究人员转而专注于开发特定于任务的规划方法,如VPN和MuZero,它们通过预测预期任务奖励的总和来学习。 然而,这些方法特定于单个任务,目前尚不清楚它们能多好地推广到新任务或从无监督数据集中学习。 与计算机视觉领域无监督表示学习的最新突破 [ 1、2] 类似,世界模型旨在学习环境中比任何特定任务更通用的模式,以便以后更有效地解决任务 。
今天,我们与DeepMind 和多伦多大学 合作推出了DreamerV2,这是第一个基于世界模型的 RL 代理,在 Atari 基准上实现了人类级别的性能。它是Dreamer 代理的第二代,它完全在从像素训练的世界模型的潜在空间内学习行为。DreamerV2 完全依赖于图像中的一般信息,即使其表示不受这些奖励的影响,也能准确预测未来的任务奖励。使用单个 GPU,DreamerV2 的表现优于具有相同计算和样本预算的顶级无模型算法。
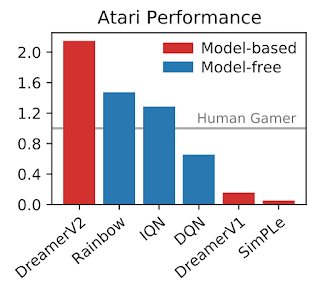
玩家在 55 款 Atari 游戏中经过 2 亿步后标准化的中位得分。DreamerV2 的表现大大优于以前的世界模型。此外,在相同的计算和样本预算内,它超过了顶级无模型代理。
[更新 – 2021 年 5 月 4 日:该图的早期版本显示 DreamerV2 的性能比实际实现的要弱。]
DreamerV2 针对 55 款 Atari 游戏中的部分游戏学习到的行为。这些视频展示了来自环境的图像。视频预测显示在博客文章下方。
世界的抽象模型
与其前身一样,DreamerV2 会学习世界模型,并利用该模型纯粹根据预测轨迹来训练演员-评论家行为。世界模型会自动学习计算其图像的紧凑表示,从而发现有用的概念(例如物体位置),并学习这些概念如何响应不同的动作而变化。这让代理可以生成其图像的抽象,忽略不相关的细节,并在单个 GPU 上实现大规模并行预测。在 2 亿个环境步骤中,DreamerV2 预测了 4680 亿个紧凑状态以学习其行为。
DreamerV2 以我们为PlaNet 引入的循环状态空间模型 (RSSM) 为基础,该模型也用于DreamerV1。在训练期间,编码器将每张图像转换为随机表示,并将其纳入世界模型的循环状态中。由于表示是随机的,因此它们无法访问有关图像的完整信息,而只能提取进行预测所需的信息,从而使代理对未见过的图像具有鲁棒性。从每个状态,解码器都会重建相应的图像以学习一般表示。此外,还会训练一个小型奖励网络来在规划期间对结果进行排名。为了在不生成图像的情况下进行规划,预测器会学习猜测随机表示,而无需访问计算它们的图像。
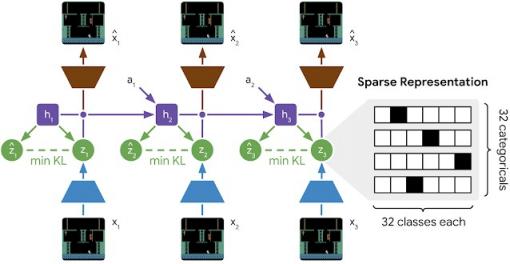
DreamerV2 使用的世界模型的学习过程。世界模型维持循环状态 (h 1 –h 3 ),接收动作 (a 1 –a 2 ),并通过随机表示 (z 1 –z 3 )整合有关图像 (x 1 –x 3 ) 的信息。预测器猜测表示为 (ẑ 1 –ẑ 3 ),而无需访问生成这些表示的图像。
重要的是,DreamerV2 为 RSSM 引入了两项新技术,从而为学习成功的策略提供了更准确的世界模型。第一种技术是用多个分类变量来表示每幅图像,而不是 PlaNet、DreamerV1 和文献中的许多其他世界模型 [ 1、2、3、4、5 ] 中使用的高斯变量。这使得世界模型能够以离散概念的形式推理世界,并能够更准确地预测未来的表示。
编码器将每幅图像转换为 32 个分布,每个分布有 32 个类别,其含义在世界模型学习时自动确定。从这些分布中采样的独热向量被连接到一个稀疏表示,并传递给循环状态。为了反向传播样本,我们使用直通梯度,这很容易通过自动微分实现。用分类变量表示图像允许预测器准确地学习可能的下一张图像的独热向量的分布。相比之下,早期使用高斯预测器的世界模型无法准确匹配可能的下一张图像的多个高斯表示的分布。
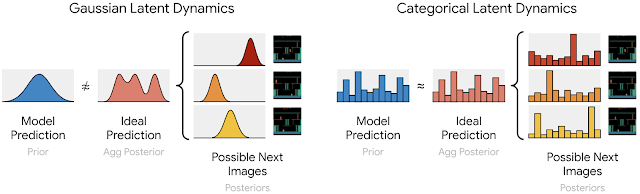
分类预测器可以准确预测表示可能的下一张图像的多个分类,而高斯预测器不够灵活,无法准确预测多个可能的高斯表示。
DreamerV2 的第二项新技术是KL 平衡。许多先前的世界模型使用ELBO 目标,该目标鼓励准确的重建,同时保持随机表示(后验)接近其预测(先验),以规范从每个图像中提取的信息量并促进泛化。由于目标是端到端优化的,因此可以通过将两者中的任何一个向另一个靠拢,使随机表示及其预测更加相似。但是,当预测器尚不准确时,将表示向其预测靠拢可能会有问题。KL 平衡使预测向表示靠拢的速度比反之更快。这可以产生更准确的预测,这是成功规划的关键。
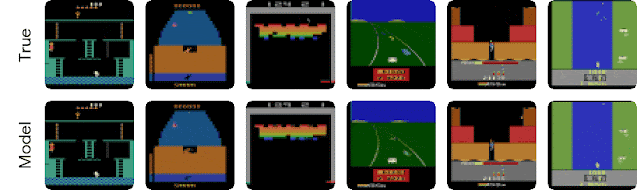
对保留序列的世界模型进行长期视频预测。每个模型接收 5 帧作为输入(未显示),然后仅根据动作预测 45 步。视频预测仅用于深入了解世界模型的质量。在规划期间,仅预测紧凑表示,而不是图像。
测量 Atari 性能
DreamerV2 是第一个能够在成熟且竞争激烈的 Atari 基准上以人类水平的表现学习成功行为的世界模型。我们选择了 55 款许多先前研究共同拥有的游戏,并推荐这组游戏用于未来的工作。按照标准评估协议,允许代理使用 4 次重复动作和粘性动作(25% 的概率忽略某个动作并重复上一个动作)进行 2 亿次环境交互。我们将其与顶级无模型代理 IQN 和 Rainbow 以及在Dopamine 框架中实现的知名C51和DQN代理进行了比较。
55 场比赛的得分汇总标准各不相同。理想情况下,新算法在所有条件下的表现都会更好。对于所有四种汇总方法,在使用相同计算预算的情况下,DreamerV2 确实优于所有无模型算法。

根据 55 款 Atari 游戏中的四种得分汇总方法,DreamerV2 的表现优于顶级无模型代理。我们引入并推荐 剪辑记录平均值 (最右侧的图)作为信息丰富且可靠的性能指标。
[更新 – 2021 年 5 月 4 日:该图的早期版本显示 DreamerV2 的性能低于实际水平。]
前三种聚合方法都是文献中提出的。我们发现每种方法都存在重大缺陷,并推荐一种新的聚合方法,即截断记录平均值,以克服这些缺陷。
玩家中位数。最常见的情况是,每款游戏的得分都根据DQN 论文中评估的人类玩家的表现进行归一化,并报告所有游戏归一化得分的中位数。不幸的是,中位数忽略了许多简单和困难游戏的得分。
玩家平均值。平均值考虑了所有游戏的得分,但主要受少数人类玩家表现不佳的游戏的影响。这使得算法很容易在某些游戏(例如 James Bond、Video Pinball)上获得较大的标准化分数,然后主导平均值。
记录平均值。先前的研究建议根据人类世界纪录进行标准化,但这种指标仍然受到少数比赛的影响,在这些比赛中,人工智能很容易超越人类记录。
截断记录平均值。我们引入了一个新的指标,该指标根据世界纪录对得分进行归一化,并对其进行截断以不超过记录。这产生了一个信息丰富且可靠的指标,该指标将所有比赛的表现考虑在内,使其大致相等。
虽然目前许多算法都超过了人类玩家的基准,但它们仍远远落后于人类的世界纪录。如上图最右侧所示,DreamerV2 在所有游戏中平均达到人类纪录的 25%,处于领先地位。将分数限制在纪录线让我们可以集中精力开发更接近人类世界纪录的方法,而不是仅在少数游戏中超越它。
什么重要,什么不重要
为了深入了解 DreamerV2 的重要组成部分,我们进行了广泛的消融研究。重要的是,我们发现分类表示比高斯表示具有明显的优势,尽管高斯在先前的工作中已被广泛使用。与大多数生成模型使用的 KL 正则化器相比,KL 平衡提供了更大的优势。
通过防止图像重建或奖励预测梯度影响模型状态,我们研究了它们对于学习成功表征的重要性。我们发现 DreamerV2 完全依赖于高维输入图像中的通用信息,即使没有使用有关奖励的信息进行训练,其表征也能实现准确的奖励预测。这反映了计算机视觉社区中无监督表征学习的成功。
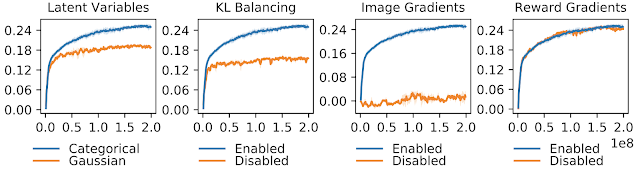
DreamerV2 各种消融的 Atari 性能(剪辑记录均值)。分类表示、KL 平衡和图像学习对于 DreamerV2 的成功至关重要。使用特定于狭窄任务的奖励信息不会为学习世界模型带来额外的好处。
结论
我们展示了如何学习强大的世界模型,以在竞争激烈的 Atari 基准上实现人类水平的表现,并超越顶级无模型代理。这一结果表明,世界模型是在强化学习问题上实现高性能的强大方法,可供从业者和研究人员使用。我们认为这表明计算机视觉中无监督表示学习的成功 [ 1 , 2 ] 现在开始以世界模型的形式在强化学习中实现。DreamerV2 的非官方实现可在 Github 上找到,它为未来的研究项目提供了一个富有成效的起点。我们认为利用大型离线数据集、长期记忆、分层规划和定向探索的世界模型是未来研究令人兴奋的途径。
致谢
该项目是与 Timothy Lillicrap、Mohammad Norouzi 和 Jimmy Ba 合作完成的。我们还要感谢 Brain Team 团队以及其他团队的所有人,他们对我们的论文草稿发表了评论,并在整个项目过程中提供了反馈。
评论