近几年,3D 传感器(例如激光雷达、深度感应摄像头和雷达) 的普及程度日益提高,因此需要能够处理这些设备捕获的数据的场景理解技术。此类技术可以使使用这些传感器的机器学习 (ML) 系统(如自动驾驶汽车和机器人)在现实世界中导航和操作,并可以在移动设备上创建更好的增强现实体验。计算机视觉领域最近在 3D 场景理解方面开始取得良好进展,包括用于移动 3D 物体检测、透明物体检测等的模型,但由于可应用于 3D 数据的可用工具和资源有限,进入该领域可能具有挑战性。
为了进一步改善 3D 场景理解并降低感兴趣的研究人员的入门门槛,我们发布了TensorFlow 3D (TF 3D),这是一个高度模块化且高效的库,旨在将 3D 深度学习功能引入 TensorFlow。TF 3D 提供了一组流行的操作、损失函数、数据处理工具、模型和指标,使更广泛的研究社区能够开发、训练和部署最先进的 3D 场景理解模型。
TF 3D 包含用于最先进的 3D语义分割、3D对象检测和 3D实例分割的训练和评估管道,并支持分布式训练。它还支持其他潜在应用,如 3D 对象形状预测、点云配准和点云致密化。此外,它还提供了统一的数据集规范和配置,用于训练和评估标准 3D 场景理解数据集。它目前支持Waymo Open、ScanNet和Rio数据集。但是,用户可以自由地将其他流行数据集(如NuScenes和Kitti)转换为类似格式,并将它们用于现有或自定义创建的管道中,并且可以利用 TF 3D 进行各种 3D 深度学习研究和应用,从快速原型设计和尝试新想法到部署实时推理系统。

左侧显示了 TF 3D 中的 3D 对象检测模型在Waymo Open Dataset的帧上的示例输出 。 右侧显示了3D 实例分割模型在ScanNet 数据集的场景上的示例输出。
在这里,我们将介绍 TF 3D 中提供的高效且可配置的稀疏卷积主干,这是在各种 3D 场景理解任务中取得最佳结果的关键。此外,我们将介绍 TF 3D 目前支持的三个管道:3D 语义分割、3D 对象检测和 3D 实例分割。
3D稀疏卷积网络
传感器捕获的 3D 数据通常由一个场景组成,该场景包含一组感兴趣的对象(例如汽车、行人等),这些对象大多被开放空间包围,而开放空间的兴趣有限(或毫无兴趣)。因此,3D 数据本质上是稀疏的。在这样的环境中,卷积的标准实现将需要大量计算并消耗大量内存。因此,在 TF 3D 中,我们使用子流形稀疏卷积和池化操作,这些操作旨在更有效地处理 3D 稀疏数据。稀疏卷积模型是大多数户外自动驾驶(例如 Waymo、NuScenes)和室内基准(例如 ScanNet)中应用的先进方法的核心。
我们还使用各种CUDA技术来加速计算(例如,散列、在共享内存中分区/缓存过滤器以及使用位操作)。在 Waymo Open 数据集上进行的实验表明,此实现比使用预先存在的 TensorFlow 操作的精心设计的实现快 20 倍左右。
然后,TF 3D 使用 3D 子流形稀疏U-Net 架构为每个体素提取一个特征。事实证明,U-Net 架构非常有效,因为它可以让网络提取粗略和精细特征,并将它们组合起来进行预测。U-Net 网络由三个模块组成:编码器、瓶颈和解码器,每个模块由多个稀疏卷积块组成,可能具有池化或非池化操作。
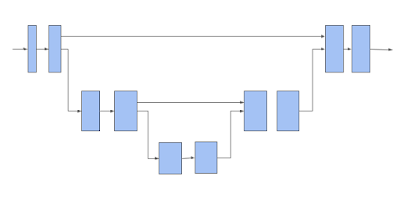
3D 稀疏体素 U-Net 架构。请注意,水平箭头接收体素特征并对其应用子流形稀疏卷积。向下移动的箭头执行子流形稀疏池化。向上移动的箭头将收集池化特征,将它们与来自水平箭头的特征连接起来,并对连接的特征执行子流形稀疏卷积。
上面描述的稀疏卷积网络是 TF 3D 中提供的 3D 场景理解管道的主干。下面描述的每个模型都使用此主干网络提取稀疏体素的特征,然后添加一个或多个额外的预测头来推断感兴趣的任务。用户可以通过更改编码器/解码器层的数量和每层中的卷积数量以及修改卷积滤波器大小来配置 U-Net 网络,从而可以通过不同的主干配置探索各种速度/准确性权衡
3D语义分割
3D 语义分割模型 只有一个输出头,用于预测每个体素的语义分数,这些分数被映射回点以预测每个点的语义标签。
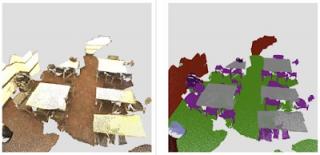
来自ScanNet 数据集的室内场景的 3D 语义分割 。
3D 实例分割
在 3D 实例分割中,除了预测语义之外,目标还是将属于同一对象的体素分组在一起。TF 3D 中使用的 3D 实例分割算法基于我们之前使用深度度量学习进行 2D 图像分割的工作。该模型预测每个体素的实例嵌入向量以及每个体素的语义分数。实例嵌入向量将体素映射到嵌入空间,其中对应于同一对象实例的体素靠得很近,而对应于不同对象的体素则相距很远。在这种情况下,输入是点云而不是图像,它使用 3D 稀疏网络而不是 2D 图像网络。在推理时,贪婪算法一次选择一个实例种子,并使用体素嵌入之间的距离将它们分组为片段。
3D 物体检测
3D 物体检测模型预测每个体素的大小、中心和旋转矩阵以及物体语义分数。在推理时,使用框提议机制将数十万个每个体素的框预测减少为几个准确的框提议,然后在训练时,将框预测和分类损失应用于每个体素的预测。我们对预测框角和真实框角之间的距离应用Huber 损失。由于根据其大小、中心和旋转矩阵估计框角的函数是可微的,因此损失将自动传播回那些预测的物体属性。我们使用动态框分类损失,将与真实框强烈重叠的框分类为正,将不重叠的框分类为负。

我们在 ScanNet 数据集上的 3D 对象检测结果。
在我们最近的论文《DOPS:学习检测 3D 物体并预测其 3D 形状》中,我们详细描述了用于 TF 3D 中物体检测的单阶段弱监督学习算法。此外,在后续工作中,我们通过提出基于稀疏 LSTM 的多帧模型扩展了 3D 物体检测模型以利用时间信息。我们继续证明,在Waymo Open 数据集中,该时间模型的表现比逐帧方法高出 7.5% 。
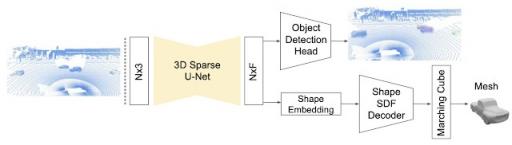
DOPS 论文中介绍的 3D 物体检测和形状预测模型 。使用 3D 稀疏 U-Net 为每个体素提取特征向量。物体检测模块使用这些特征来提出 3D 框和语义分数。同时,网络的另一个分支预测形状嵌入,用于为每个物体输出网格。
准备好开始了吗?
我们确实发现这个代码库对我们的 3D 计算机视觉项目很有用,我们希望您也一样。欢迎对代码库做出贡献,请继续关注我们对框架的进一步更新。要开始使用,请访问我们的 github 存储库。
致谢
TensorFlow 3D 代码库和模型的发布是 Google 研究人员广泛合作以及产品组反馈和测试的结果。我们特别要强调 Alireza Fathi 和 Rui Huang 的核心贡献(他们在 Google 工作期间完成的工作),并特别感谢 Guangda Lai、Abhijit Kundu、Pei Sun、Thomas Funkhouser、David Ross、Caroline Pantofaru、Johanna Wald、Angela Dai 和 Matthias Niessner。
评论