神经网络(NN) 的成功通常取决于它对各种任务的泛化能力。然而,设计具有良好泛化的 NN 具有挑战性,因为研究界对神经网络泛化的理解目前有些有限:对于给定的问题,合适的神经网络是什么样的?它应该有多深?应该使用哪种类型的层?LSTM是否足够,还是Transformer层更好?或者两者结合?集成或提炼是否会提高性能?当考虑到机器学习 (ML) 领域可能存在比其他领域更好的直觉和更深入的理解时,这些棘手的问题变得更具挑战性。
近年来,AutoML算法应运而生 [如1、2、3 ],帮助研究人员自动找到合适的神经网络,无需手动实验。神经架构搜索(NAS) 等技术使用强化学习(RL)、进化算法和组合搜索等算法,在给定的搜索空间中构建神经网络。通过适当的设置,这些技术已证明它们能够提供比手动设计的算法更好的结果。但通常这些算法计算量很大,需要训练数千个模型才能收敛。此外,它们探索特定领域的搜索空间,并结合大量无法跨领域很好地迁移的人类先验知识。例如,在图像分类中,传统的 NAS 会搜索两个好的构建块(卷积块和下采样块),并按照传统惯例排列它们以创建完整的网络。
为了克服这些缺点,并将 AutoML 解决方案的访问权限扩展到更广泛的研究社区,我们很高兴地宣布开源模型搜索,该平台可帮助研究人员高效、自动地开发最佳 ML 模型。模型搜索不专注于特定领域,而是与领域无关,灵活,能够找到最适合给定数据集和问题的适当架构,同时最大限度地减少编码时间、工作量和计算资源。它基于 Tensorflow 构建,可以在单台机器或分布式环境中运行。
概述
模型搜索系统由多个训练器、一个搜索算法、一个迁移学习算法和一个用于存储各种评估模型的数据库组成。该系统以自适应但异步的方式对各种 ML 模型(不同的架构和训练技术)进行训练和评估实验。虽然每个训练器都独立进行实验,但所有训练器都会共享从实验中获得的知识。在每个周期开始时,搜索算法都会查找所有已完成的试验并使用集束搜索来决定下一步要尝试什么。然后,它会对迄今为止发现的最佳架构之一调用变异,并将生成的模型分配回训练器。
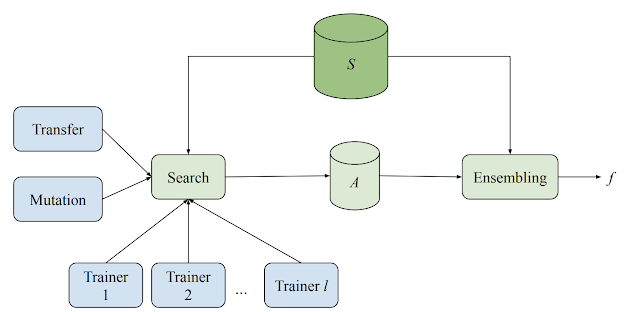
模型搜索示意图,展示了分布式搜索和集成。每个训练器独立运行以训练和评估给定模型。结果与搜索算法共享并存储。然后,搜索算法对最佳架构之一调用变异,然后将新模型发送回训练器进行下一次迭代。S 是训练和验证示例集,A 是训练和搜索期间使用的所有候选集。
该系统从一组预定义块构建神经网络模型,每个块代表一个已知的微架构,如 LSTM、ResNet或 Transformer 层。通过使用预先存在的架构组件块,模型搜索能够利用跨领域 NAS 研究的现有最佳知识。这种方法也更有效,因为它探索的是结构,而不是更基本、更详细的组件,从而缩小了搜索空间的规模。
运行良好的神经网络微架构块,例如 ResNet 块。
由于模型搜索框架是基于Tensorflow构建的,因此模块可以实现任何以张量为输入的函数。例如,假设有人想要引入一个由一系列微架构构建的新搜索空间。该框架将采用新定义的模块并将其合并到搜索过程中,以便算法可以从提供的组件中构建最佳的神经网络。提供的模块甚至可以是已知可以解决相关问题的完全定义的神经网络。在这种情况下,模型搜索可以配置为简单地充当强大的集成机器。
模型搜索中实现的搜索算法具有自适应性、贪婪性和增量性,这使得它们比 RL 算法收敛得更快。但它们确实模仿了 RL 算法的“探索和利用”性质,将寻找良好候选者(探索步骤)分开,并通过整合发现的良好候选者(利用步骤)来提高准确性。主搜索算法在对架构或训练技术应用随机更改(例如,使架构更深)后,自适应地修改表现最好的k个实验之一(其中k可以由用户指定)。
这是经过多次实验后网络演化的示例。每种颜色代表不同类型的架构块。最终网络是通过高性能候选网络的突变形成的,在本例中增加了深度。
为了进一步提高效率和准确性,在各种内部实验之间启用了迁移学习。模型搜索通过两种方式实现这一点 - 通过知识蒸馏或权重共享。知识蒸馏允许人们通过添加与高性能模型的预测以及基本事实相匹配的损失项来提高候选者的准确性。另一方面,权重共享通过从先前训练的候选者中复制合适的权重并随机初始化剩余的参数,从网络中引导一些参数(应用突变后)。这可以加快训练速度,从而有机会发现更多(更好)的架构。
实验结果
模型搜索以最少的迭代次数改进了生产模型。在最近的一篇论文中,我们通过发现一个用于关键字识别和语言识别的模型展示了模型搜索在语音领域的能力。在不到 200 次迭代中,生成的模型在准确度上略微优于专家设计的内部最先进的生产模型,可训练参数减少了约 130K(184K 对比 315K 参数)。
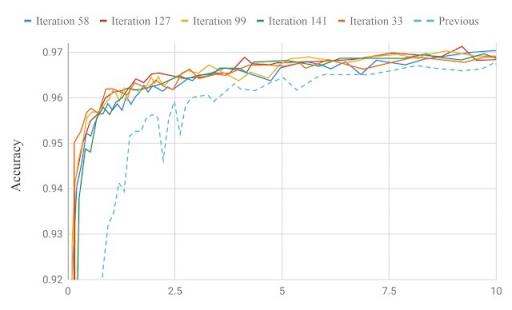
与之前的关键词识别生产模型相比,我们系统中的模型准确率进行了迭代,在链接的论文中可以找到语言识别的类似图表。
我们还应用了模型搜索,以在大量探索的CIFAR-10成像数据 集上找到适合图像分类的架构。使用一组已知的卷积块,包括卷积、resnet 块(即两个卷积和一个跳过连接)、NAS-A 单元、全连接层等,我们观察到我们能够在 209 次试验中(即仅探索 209 个模型)快速达到 91.83 的基准准确率。相比之下,之前的顶级表现者在 5807 次试验中达到了 NasNet 算法(RL)的相同阈值准确率,在 1160 次试验中达到了PNAS(RL + Progressive)的相同阈值准确率。
结论
我们希望模型搜索代码能为研究人员提供一个灵活、与领域无关的 ML 模型发现框架。通过基于给定领域的先前知识,我们相信,当提供由标准构建块组成的搜索空间时,该框架足够强大,可以在经过充分研究的问题上构建具有最先进性能的模型。
致谢
特别感谢所有对开源和论文的代码贡献者:Eugen Ehotaj、Scotty Yak、Malaika Handa、James Preiss、Pai Zhu、Aleks Kracun、Prashant Sridhar、Niranjan Subrahmanya、Ignacio Lopez Moreno、Hyun Jin Park 和 Patrick Violette。
评论