语法错误纠正 (GEC) 尝试对语法和其他类型的写作错误进行建模,以提供语法和拼写建议,从而提高文档、电子邮件、博客文章甚至非正式聊天中书面输出的质量。在过去 15 年中,GEC 质量有了显著提高,这在很大程度上归功于将问题重新定义为“翻译”任务。例如,在 Google Docs 中引入此方法后,接受的语法纠正建议数量 显著增加。
然而,GEC 模型面临的最大挑战之一是数据稀疏性。与其他自然语言处理(NLP) 任务(例如语音识别和机器翻译)不同,GEC 可用的训练数据非常有限,即使是英语等资源丰富的语言也是如此。解决此问题的常见方法是使用一系列技术生成合成数据,从基于启发式的随机单词或字符级损坏到基于模型的方法。然而,这些方法往往过于简单,不能反映实际用户错误类型的真实分布。
在EACL 第 16 届创新使用 NLP 构建教育应用研讨会上,我们介绍了 “使用标记损坏模型生成合成数据进行语法错误纠正”,其中介绍了标记损坏模型。受流行的机器翻译反向翻译数据合成技术的启发,这种方法能够精确控制合成数据的生成,确保多样化的输出与实践中看到的错误分布更加一致。我们使用标记损坏模型生成了一个新的2 亿句子数据集,并发布了该数据集,以便为研究人员提供 GEC 的真实预训练数据。通过将这个新数据集集成到我们的训练管道中,我们能够显著改进 GEC 基线。
标记腐败模型
将传统损坏模型应用于 GEC 背后的理念是从一个语法正确的句子开始,然后通过添加错误来“损坏”它。通过在现有 GEC 数据集中切换源句子和目标句子,可以轻松训练损坏模型,以前的研究表明,这种方法对于生成改进的 GEC 数据集非常有效。

传统的损坏模型会在给定一个干净的输入句子(绿色)的情况下生成一个不合语法的句子(红色)。
我们提出的标记损坏模型基于此想法,将干净的句子以及描述希望重现的错误类型的错误类型标签作为输入。然后,它会生成包含给定错误类型的输入句子的非语法版本。与传统损坏模型相比,为不同的句子选择不同的错误类型会增加损坏的多样性。
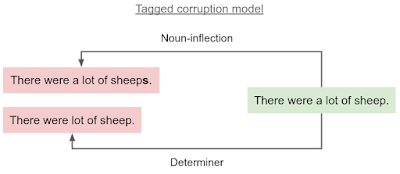
标记错误模型会根据错误类型标记,为干净的输入句子(绿色)生成错误(红色)。限定词错误可能会导致“a”被删除,而名词词形变化错误则可能导致错误的复数“sheeps”。
为了使用此模型生成数据,我们首先从C4 语料库中随机选择了 2 亿个干净的句子,并为每个句子分配一个错误类型标签,以使它们的相对频率与小型开发集BEA-dev的错误类型标签分布相匹配。由于BEA-dev是一个精心策划的集合,涵盖了广泛的不同英语水平,我们预计其标签分布能够代表在野外发现的书写错误。然后,我们使用带标签的损坏模型来合成源句子。
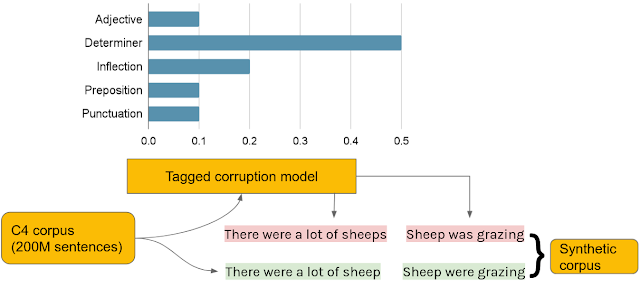
使用标记损坏模型生成合成数据。在合成 GEC 训练语料库中,干净的 C4 句子(绿色)与损坏的句子(红色)配对。损坏的句子是使用标记损坏模型根据开发集中的错误类型频率生成的(条形图)。
结果
在我们的实验中,标记腐败模型在两个标准开发集(CoNLL-13和BEA-dev)上的表现比未标记腐败模型高出 3 个以上 F0.5 点(GEC 研究中结合精确度和召回率且更重视精确度的标准指标),从而推动了两个广泛使用的学术测试集CoNLL-14和BEA-test上的最新表现。
此外,使用标记损坏模型不仅可以在标准 GEC 测试集上获得收益,还可以使 GEC 系统适应用户的熟练程度。例如,这可能很有用,因为英语母语作者的错误标记分布通常与非英语母语作者的分布有很大不同。例如,英语母语作者往往会犯更多的标点符号和拼写错误,而非英语母语作者的文本中更常见限定词错误(例如,缺少或多余的冠词,如“a”、“an”或“the”)。
结论
众所周知,神经序列模型需要大量数据,但用于语法错误纠正的带注释训练数据却很少。我们的新C4_200M 语料库是一个包含各种语法错误的合成数据集,用于预训练 GEC 系统时可产生最先进的性能。通过发布该数据集,我们希望为 GEC 研究人员提供宝贵的资源来训练强大的基线系统。
评论