自然语言处理(NLP) 的一个关键挑战是构建能够理解和推理现实语音所特有的不同语言现象的对话代理。例如,由于人们并不总是预先考虑他们要说什么,自然对话中经常会出现打断语音的情况,称为不流畅。这种不流畅可能很简单(如感叹词、重复、重新开始或更正),只是破坏了句子的连续性,也可能是更复杂的语义不流畅,其中短语的基本含义会发生变化。此外,理解对话通常还需要了解时间关系,例如一个事件是先于另一个事件还是继另一个事件之后。然而,基于当今 NLP 模型构建的对话代理在面对时间关系或不流畅时往往会遇到困难,而且在改进其性能方面进展缓慢。这在一定程度上是由于缺乏涉及此类有趣的对话和语音现象的数据集。
为了激发研究界对这一方向的兴趣,我们很高兴推出TimeDial,用于对话中的时间常识推理,以及Disfl-QA,专注于上下文不流畅。TimeDial 提出了一种新的多项选择跨度填充任务,旨在理解时间,其带注释的测试集超过约 1.1k 个对话。Disfl-QA 是第一个包含信息搜索环境中上下文不流畅的数据集,即对维基百科段落进行问答,其中包含约 12k 个人工注释的不流畅问题。这些基准数据集是同类中的第一个,显示了人类表现与当前最先进的 NLP 模型之间的巨大差距。
时间拨盘
虽然人们可以毫不费力地推理日常的时间概念,例如持续时间、频率或对话中事件的相对顺序,但这些任务对于对话代理来说却具有挑战性。例如,当前的 NLP 模型在填空(如下所示)时通常会做出错误的选择,因为这种填空假设推理需要基本的世界知识水平,或者需要理解对话轮次中时间概念之间的显式和隐式相互依赖关系。
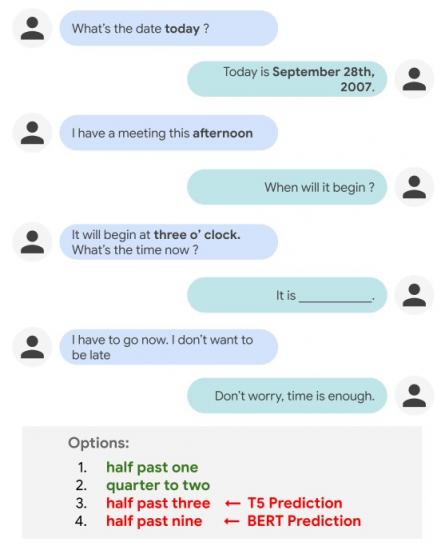
人们很容易判断“一点半”和“两点差一刻”是比“三点半”和“九点半”更合理的填空选项。然而,在对话背景下进行这样的时间推理对于 NLP 模型来说并不是一件容易的事,因为它需要借助世界知识(即知道参与者还没有迟到)并理解事件之间的时间关系(“一点半”在“三点”之前,而“三点半”在“三点”之后)。事实上,目前最先进的模型如T5和BERT最终选出了错误的答案——“三点半”(T5)和“九点半”(BERT)。
TimeDial 基准数据集(源自DailyDialog多轮对话语料库)用于衡量模型在对话语境中的时间常识推理能力。数据集中约 1.5k 个对话均以多项选择设置呈现,其中一个时间跨度被屏蔽,模型需要从四个选项列表中找出所有正确答案来填空。
我们在实验中发现,虽然人们可以轻松回答这些多项选择题(准确率为 97.8%),但最先进的预训练语言模型仍然难以应对这一挑战集。我们尝试了三种不同的建模范式:(i) 使用 BERT 对提供的 4 个选项进行分类,(ii) 使用 BERT-MLM 对对话中的掩码跨度进行掩码填充,(iii) 使用 T5 的生成方法。我们观察到所有模型都难以应对这一挑战集,最佳变体仅得分 73%。
模型 2-最佳准确率
人类 97.8%
BERT-分类 50.0%
BERT - 掩码填充 68.5%
T5——代 73.0%
定性错误分析表明,预训练语言模型通常依赖于浅显的、虚假的特征(尤其是文本匹配),而不是真正根据上下文进行推理。构建能够执行 TimeDial 所需的时间常识推理的 NLP 模型可能需要重新思考时间对象在一般文本表示中的表示方式。
问答
由于不流畅本质上是一种语音现象,因此它最常见于语音识别系统的文本输出中。理解这种不流畅的文本是构建理解人类语音的对话代理的关键。不幸的是,NLP 和语音社区的研究因缺乏包含此类不流畅的精选数据集而受到阻碍,而可用的数据集(如Switchboard)在规模和复杂性方面受到限制。因此,在存在不流畅的情况下很难对 NLP 模型进行压力测试。
不流畅 例子
欹 “呃,今年的复活节是什么时候? ”
重复 “今年的复活节是什么时候? ”
更正 “今年的大斋期,也就是复活节是什么时候 ? ”
重启 “多少钱,不,等一下,今年的复活节是什么时候? ”
不同类型的不流畅。reparandum(需要纠正或忽略的单词;红色)、interregnum(可选的话语提示;灰色)和 repair(已纠正的单词;蓝色)。
Disfl-QA 是第一个包含信息搜索环境中上下文不流畅性的数据集,即 来自SQuAD的针对维基百科段落的问答。Disfl-QA 是一个针对不流畅性的数据集,其中所有问题(约 12k)都包含不流畅性,因此不流畅性测试集比之前的数据集大得多。Disfl-QA 中超过 90% 的不流畅性都是更正或重新开始,这使其成为一个更难的不流畅性更正测试集。此外,与早期的不流畅性数据集相比,它包含更多种类的语义干扰项,即带有语义含义的干扰项,而不是简单的语音不流畅性。
段落: ……诺曼人(诺曼语:Nourmands;法语:Normands;拉丁语:Normanni)是 10 世纪和 11 世纪将自己的名字赋予法国诺曼底地区的民族。他们是挪威人(“Norman”来自“Norseman”)的后裔,他们是丹麦、冰岛和挪威的劫掠者和海盗,在领袖罗洛的率领下……
问题1: 诺曼底位于哪个国家? 法国 ✓
问题1: 哪个国家有挪威人?不,等等, 诺曼底,不是挪威人吗? 丹麦 X
问题2: 诺曼人何时在诺曼底? 10 至 11 世纪 ✓
问题2: 诺曼人来自哪些国家? 请告诉我 诺曼人何时来到诺曼底? 丹麦、冰岛和挪威 X
SQuAD数据集中的一段文章和一些问题(Q i),以及它们的不流畅版本(DQ i),由语义干扰项(如“挪威人”和“来自哪些国家”)和来自 T5 模型的预测组成。
这里,第一个问题(Q 1 )是寻求有关诺曼底位置的答案。在不流畅的版本(DQ 1)中,在问题被纠正之前提到了诺尔斯语。这种纠正性不流畅的存在使 QA 模型感到困惑,因为该模型倾向于依赖问题中的浅显文本线索来进行预测。
Disfl-QA 还包括较新的现象,例如 reparandum 和 repair之间的共指 (指代同一实体的表达) 。
队 问答
BSkyB 从谁那里获得了经营许可证? 谁吊销了 BSkyB 的运营执照,没错,他们的运营执照是从谁那里获得的?
实验表明,现有的基于语言模型的先进问答系统在零样本设置下对 Disfl-QA 和启发式不流畅性(本文中提出)进行测试时,性能会显著下降。
数据集 F1
队 89.59
启发式 65.27(-24.32)
问答 61.64(-27.95)
我们表明,数据增强方法可以部分恢复性能损失,并证明使用人工注释的训练数据进行微调的有效性。我们认为,研究人员需要大规模不流畅性数据集,以使 NLP 模型能够对不流畅性保持稳健。
结论
理解人类语言所特有的语言现象,例如不流畅和时间推理等,是实现更自然的人机通信的关键因素。借助 TimeDial 和 Disfl-QA,我们旨在通过提供这些数据集作为 NLP 模型的测试平台来填补一项重大研究空白,以评估它们在不同任务中对普遍现象的鲁棒性。我们希望更广泛的 NLP 社区能够设计出通用的少样本或零样本方法来有效处理这些现象,而无需专门为这些挑战构建的针对特定任务的人工注释训练数据集。
致谢
TimeDial 的工作是 Lianhui Qi、Luheng He、Yenjin Choi、Manaal Faruqui 和作者们共同努力的结果。Disfl-QA 的工作是 Jiacheng Xu、Diyi Yang 和 Manaal Faruqui 合作的结果。
评论