过去十年,自动图像字幕技术取得了显著进展。自动图像字幕技术是一项利用计算机算法为图像创建书面描述的任务。大部分进展都来自于为计算机视觉和自然语言处理开发的现代深度学习方法,以及将图像与人类创建的描述配对的大规模数据集。除了支持重要的实际应用(例如为视障人士提供图像描述)之外,这些数据集还可用于研究有关将语言植根于视觉输入的重要而令人兴奋的研究问题。例如,学习“汽车”等单词的深度表示意味着同时使用语言和视觉背景。
包含文本描述及其对应图像对的图像字幕数据集(例如MS-COCO和Flickr30k)已广泛用于学习对齐的图像和文本表示以及构建字幕模型。不幸的是,这些数据集的跨模态关联有限:图像不与其他图像配对,字幕仅与同一图像的其他字幕配对(也称为共同字幕),存在匹配但未标记为匹配的图像-字幕对,并且没有标签表明图像-字幕对何时不匹配。这破坏了对模态间学习(例如,将字幕与图像连接起来)如何影响模态内任务(将字幕与字幕或图像与图像连接起来)的研究。解决这个问题很重要,尤其是因为大量关于从与文本配对的图像中学习的工作都是由关于视觉元素应如何通知和改进语言表示的争论所推动的。
为了弥补这一评估差距,我们提出了“交叉字幕:MS-COCO 的扩展模态内和模态间语义相似性判断”,该数据集最近在EACL 2021上进行了展示。交叉字幕 (CxC) 数据集扩展了 MS-COCO 的开发和测试拆分,为图像-文本、文本-文本和图像-图像对提供了语义相似性评级。评级标准基于语义文本相似性,这是短文本对之间现有的、广泛采用的语义相关性度量,我们将其扩展为包括对图像的判断。总而言之,CxC 包含 267,095 对(源自 1,335,475 个独立判断)的人工语义相似性评级,在规模和细节上大大扩展了 MS-COCO 开发和测试拆分中 50k 个原始二进制配对。我们发布了CxC 的评级,以及将 CxC 与现有 MS-COCO 数据合并的代码。因此,任何熟悉 MS-COCO 的人都可以轻松地使用 CxC 增强他们的实验。

Crisscrossed Captions 通过为现有的图像-标题对和共同标题添加人类衍生的语义相似性评级(实线)扩展了 MS-COCO 评估集,并通过为新的图像-标题、标题-标题和图像-图像对添加人类评级(虚线)来增加评级密度。*
创建 CxC 数据集
如果一张图片胜过千言万语,那很可能是因为图片中通常描绘的物体之间存在如此多的细节和关系。我们可以描述狗身上皮毛的质地,说出它追逐的飞盘上的标志,提到刚刚扔出飞盘的人脸上的表情,或者注意到人头顶上一棵树上大叶子上鲜艳的红色,等等。
CxC 数据集扩展了 MS-COCO 评估划分,在模态内和模态间具有分级相似性关联。MS-COCO 每幅图像有 5 个标题,分为410k 个训练标题、25k 个开发标题和 25k 个测试标题(分别用于 82k、5k、5k 幅图像)。理想的扩展是对数据集中的每一对(标题-标题、图像-图像和图像-标题)进行评级,但这是不可行的,因为这需要对数十亿对进行人工评级。
鉴于随机选择的图像和标题对可能不相似,我们想出了一种选择人工评分项目的方法,其中至少包括一些具有高预期相似度的新对。为了减少所选对对用于查找它们的模型的依赖,我们引入了一种间接采样方案(如下所示),其中我们使用不同的编码方法对图像和标题进行编码,并计算相同模态项目对之间的相似度,从而得到相似度矩阵。图像使用Graph-RISE嵌入进行编码,而标题使用两种方法进行编码 -通用句子编码器(USE) 和基于GloVe嵌入的平均词袋(BoW) 。由于每个 MS-COCO 示例都有五个共同标题,我们对共同标题编码进行平均以创建每个示例的单个表示,确保所有标题对都可以映射到图像对(下面详细介绍我们如何选择跨模态对)。
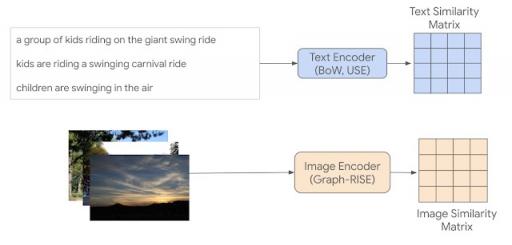
顶部:使用平均同字幕编码构建的文本相似度矩阵(每个单元格对应一个相似度分数),因此每个文本条目对应一个图像,从而产生一个 5k x 5k 矩阵。使用了两种不同的文本编码方法,但为简单起见,仅显示一个文本相似度矩阵。底部:数据集中每幅图像的图像相似度矩阵,从而产生一个 5k x 5k 矩阵。
间接采样方案的下一步是使用计算出的图像相似度对字幕对进行有偏采样,以供人工评分(反之亦然)。例如,我们从文本相似度矩阵中选择两个具有高计算相似度的字幕,然后分别拍摄它们的图像,从而产生一对新的图像,这些图像在外观上有所不同,但根据它们的描述,它们所描绘的内容相似。例如,字幕“一只害羞地向一侧看的狗”和“一只黑狗抬起头享受微风”将具有相当高的模型相似度,因此可以选择下图中两只狗的对应图像进行图像相似度评分。此步骤也可以从两个具有高计算相似度的图像开始,以产生一对新的字幕。现在,我们已经间接采样了新的模态内对(至少其中一些非常相似),我们获得了人工评分。
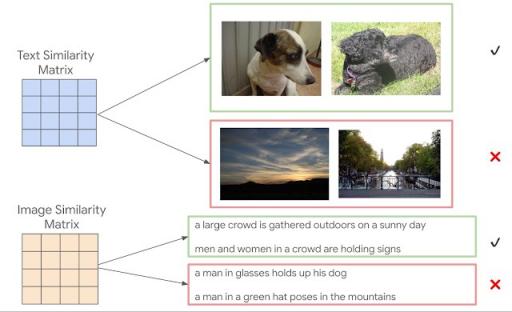
顶部:根据计算出的字幕相似度挑选图像对。底部:根据计算出的字幕相似度挑选图像对。
最后,我们使用这些新的模态内对及其人工评分来选择新的模态间对进行人工评分。我们通过使用现有的图像-字幕对来链接模态来实现此目的。例如,如果字幕对示例ij被人工评为高度相似,我们从示例i中挑选图像并从示例j中挑选字幕以获得新的模态间对进行人工评分。同样,我们使用相似度最高的模态内对进行抽样,因为这至少包含一些具有高相似度的新对。最后,我们还为所有现有的模态间对和大量共同字幕样本添加人工评分。
下表显示了与每个评级相对应的语义图像相似度 (SIS) 和语义图像-文本相似度 (SITS) 对的示例,其中 5 表示最相似,0 表示完全不相似。






基于 SIS(中间)和 SITS(右)任务的图像对的每个人为相似度得分的示例(左: 5 到 0,5 表示非常相似,0 表示完全不相似)。请注意,这些示例仅用于说明目的,本身并不包含在 CxC 数据集中。
评估
MS-COCO 支持三种检索任务:
给定一张图片,在评估集中的所有其他标题中找到与其匹配的标题。
给定一个标题,在评估集的所有其他图像中找到其对应的图像。
给定一个标题,在评估集中的所有其他标题中找到它的其他共同标题。
MS-COCO 的配对是不完整的,因为为一个图像创建的标题有时同样适用于另一个图像,但这些关联并未在数据集中捕获。CxC 使用新的正对增强了这些现有的检索任务,并且还支持新的图像-图像检索任务。凭借其分级相似性判断,CxC 还可以测量模型和人工排名之间的相关性。检索指标通常只关注正对,而 CxC 的相关性分数还考虑了相似性的相对顺序并包括低分项目(不匹配)。与不相交的标题-图像、标题-标题和图像-图像关联集相比,在一组通用的图像和标题上支持这些评估使它们对于理解跨模式学习更有价值。
我们进行了一系列实验来展示 CxC 评分的实用性。为此,我们构建了三个双编码器 (DE) 模型,使用BERT -base 作为文本编码器,使用EfficientNet-B4作为图像编码器:
双方使用共享文本编码器的文本-文本(DE_T2T)模型。
使用前面提到的文本和图像编码器的图像文本模型(DE_I2T),并在文本编码器上方包含一个层以匹配图像编码器的输出。
在文本-文本和图像-文本任务的加权组合上训练的多任务模型(DE_I2T+T2T)。
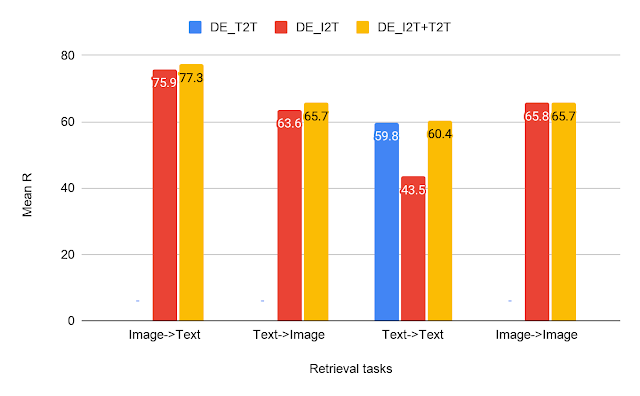
CxC 检索结果——对所有四个检索任务的文本-文本 (T2T)、图像-文本 (I2T) 和多任务 (I2T+T2T) 双编码器模型进行比较。
从检索任务的结果中,我们可以看到 DE_I2T+T2T(黄色条)在图像-文本和文本-图像检索任务上的表现优于 DE_I2T(红色条)。因此,添加模态内(文本-文本)训练任务有助于提高模态间(图像-文本、文本-图像)的性能。至于其他两个模态内任务(文本-文本和图像-图像),DE_I2T+T2T 在这两个任务上都表现出强劲、均衡的性能。
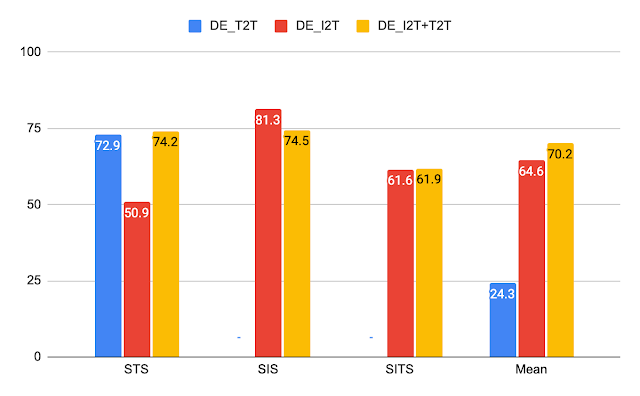
与上面显示的相同模型的 CxC 相关结果。
对于相关性任务,DE_I2T 在 SIS 上表现最佳,而 DE_I2T+T2T 总体表现最佳。相关性得分还表明 DE_I2T 仅在图像上表现良好:它具有最高的 SIS,但 STS 却差得多。将文本文本损失添加到 DE_I2T 训练(DE_I2T+T2T)可产生更均衡的整体性能。
CxC 数据集提供了比原始 MS-COCO 图像-标题对更完整的图像与标题之间的关系。新的评级已经发布,更多详细信息请参阅我们的论文。我们希望鼓励研究界推动 CxC 引入的任务的最新进展,使用更好的模型来联合学习模态间和模态内表示。
致谢
核心团队包括 Daniel Cer、Yinfei Yang 和 Austin Waters。我们感谢 Julia Hockenmaier 对 CxC 公式的贡献、Google 数据计算团队(尤其是 Ashwin Kakarla 和 Mohd Majeed)提供的工具和注释支持、Yuan Zhang 和 Eugene Ie 对论文初始版本的评论以及 Daphne Luong 对数据收集的执行支持。
评论