近几年来,用于文本摘要等任务的自然语言生成研究取得了巨大进展。然而,尽管达到了很高的流畅度,神经系统仍然容易产生幻觉(即生成可理解但不忠实于原文的文本),这可能会阻止这些系统在许多需要高精度的应用中使用。以Wikibio 数据集中的一个例子为例,其中负责总结比利时足球运动员Constant Vanden Stock的维基百科信息框条目的神经基线模型错误地总结了他是一名美国花样滑冰运动员。

虽然评估生成的文本对源内容的忠实度的过程可能具有挑战性,但当源内容结构化(例如表格格式)时,通常会更容易。此外,结构化数据还可以测试模型的推理和数字推理能力。然而,现有的大规模结构化数据集通常很嘈杂(即无法从表格数据中完全推断出参考句子),使得它们在模型开发中测量幻觉时不可靠。
在“ ToTTo:受控的表格到文本生成数据集”中,我们展示了一个开放域表格到文本生成数据集,该数据集使用新颖的注释流程(通过句子修订)以及可用于评估模型幻觉的受控文本生成任务创建。ToTTo(“Table-To-Text”的简写)包含 121,000 个训练示例,以及用于开发和测试的各 7,500 个示例。由于注释的准确性,该数据集适合作为高精度文本生成研究的具有挑战性的基准。数据集和代码在我们的 GitHub 存储库上开源。
表格到文本生成
ToTTo 引入了一项受控生成任务,其中给定的维基百科表格和一组选定的单元格被用作生成单个句子描述任务的源材料,该句子描述总结了表格上下文中的单元格内容。下面的示例展示了该任务带来的许多挑战,例如数字推理、大型开放域词汇表和多样化的表格结构。
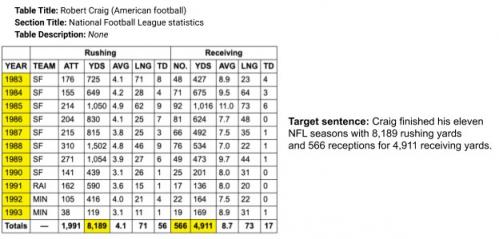
ToTTo 数据集中的示例,其中给定源表和一组突出显示的单元格(左),目标是生成一个句子描述,例如“目标句子”(右)。请注意,生成目标句子需要数值推理(11 个 NFL 赛季)和对 NFL 领域的理解。
注释过程
设计一个注释过程以从表格数据中获得自然但又干净的目标句子是一项重大挑战。许多数据集(如Wikibio和RotoWire)启发式地将自然出现的文本与表格配对,这是一个嘈杂的过程,很难分辨幻觉主要是由数据噪声还是模型缺陷引起的。另一方面,可以引导注释者从头开始编写句子目标,这些句子目标忠实于表格,但生成的目标在结构和风格方面 往往缺乏多样性。
相比之下,ToTTo 是使用一种新颖的数据注释策略构建的,其中注释者分阶段修改现有的维基百科句子。这样一来,目标句子既干净又自然,包含有趣且多样的语言属性。数据收集和注释过程从收集维基百科的表格开始,其中给定的表格与根据启发式方法从支持页面上下文收集的摘要句子配对,例如页面文本和表格之间的单词重叠以及引用表格数据的超链接。这个摘要句子可能包含表格不支持的信息,并且可能包含仅在表格中找到的先行词的代词,而不是句子本身。
然后,注释者会突出显示表格中支持该句子的单元格,并删除表格不支持的句子中的短语。他们还会将句子脱离上下文,使其独立(例如,具有正确的代词解析)并在必要时纠正语法。
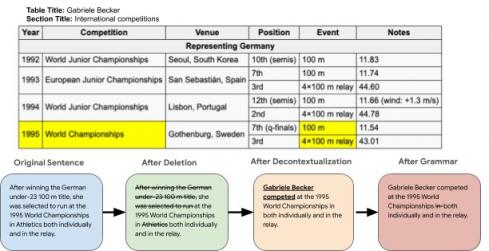
我们表明,注释者在上述任务上获得了高度的一致性:单元格突出显示的Fleiss Kappa为 0.856,最终目标句子的BLEU为 67.0。
数据集分析
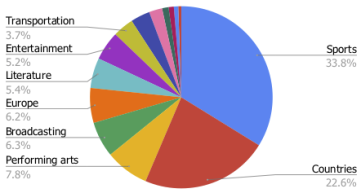
我们对 ToTTo 数据集的 44 个类别进行了主题分析,发现体育和国家主题(每个主题都包含一系列细粒度的主题,例如,体育项目的主题是足球/奥运会,国家的主题是人口/建筑)共占数据集的 56.4%。其余 44% 由更广泛的主题组成,包括表演艺术、交通和娱乐。
此外,我们对 100 个随机选择的示例中的数据集中不同类型的语言现象进行了手动分析。下表总结了需要参考页面和章节标题的示例比例,以及数据集中可能对当前系统构成新挑战的一些语言现象。
语言现象 百分比
需要引用页面标题 82%
需要引用章节标题 19%
需要参考表格描述 3%
推理(逻辑、数字、时间等) 21%
跨行/列/单元格比较 13%
需要背景信息 12%
基线结果
我们展示了文献中三个最先进模型(BERT-to-BERT、Pointer Generator和Puduppully 2019 模型)在两个评估指标BLEU和PARENT上的一些基准结果。除了报告整个测试集上的分数外,我们还在由域外示例组成的更具挑战性的子集上评估每个模型。如下表所示,BERT-to-BERT 模型在 BLEU 和 PARENT 方面表现最佳。此外,所有模型在挑战集上的表现都明显较差,这表明域外泛化存在挑战。
布鲁 父母 布鲁 父母
模型 (全面的) (全面的) (挑战) (挑战)
BERT 到 BERT 43.9 52.6 34.8 46.7
指针生成器 41.6 51.6 32.2 45.2
Puduppully 等人,2019 年 19.2 29.2 13.9 25.8
虽然自动指标可以在一定程度上指示性能,但它们目前还不足以评估文本生成系统中的幻觉。为了更好地理解幻觉,我们手动评估表现最好的基线,以确定它对源表中内容的忠实程度,假设差异表明存在幻觉。为了计算“专家”性能,对于我们的多参考测试集中的每个示例,我们保留一个参考并要求注释者将其与其他参考进行比较以确定忠实度。结果显示,表现最好的基线似乎在约 20% 的时间内产生幻觉信息。
忠诚 忠诚
模型 (全面的) (挑战)
专家 93.6 91.4
BERT 到 BERT 76.2 74.2
模型错误和挑战
在下表中,我们展示了观察到的模型误差,以突出 ToTTo 数据集中一些更具挑战性的方面。我们发现,最先进的模型在处理幻觉、数字推理和罕见主题时会遇到困难,即使使用经过清理的参考文献(红色错误)。最后一个例子表明,即使模型输出是正确的,它有时也不像包含更多关于表格的推理的原始参考文献那样具有信息量(以蓝色显示)。
参考 模型预测
1939 年的库里杯上,西部省队在开普敦以 17-6 输给了德兰士瓦队。 首届柯里杯于 1939 年在德兰士瓦的新地举行,西部省队以 17 比6获胜。
IBM 于 2000 年发布了第二代微型硬盘,容量增至 512 MB 和 1 GB。 2000 年有512 种微硬盘型号:1 GB。
1956 年摩托车大奖赛赛季包括五个级别的六场大奖赛:500cc、350cc、250cc、125cc 和 500cc 边车。 1956 年摩托车大奖赛赛季包括五个级别的八场大奖赛:500cc、350cc、250cc、125cc 和 500cc 边车。
在特拉维斯·凯尔西的最后一个大学赛季中,他创造了个人职业生涯最高的接球次数(45)、接球码数(722)、平均接球码数(16.0)和接球达阵数(8)。 特拉维斯·凯尔西在 2012 赛季共完成 45 次接球,接球码数为 722 码(平均 16.0 码),达阵 8 次。
结论
在这项研究中,我们展示了 ToTTo,这是一个大型的英语表格转文本数据集,它展示了受控生成任务和基于迭代句子修订的数据注释过程。我们还提供了几个最先进的基线,并证明了 ToTTo 可以成为建模研究以及开发能够更好地检测模型改进的评估指标的有用数据集。
除了建议的任务之外,我们希望我们的数据集也能对其他任务有所帮助,例如表格理解和句子修订。ToTTo 可在我们的GitHub repo上获取。
致谢
作者感谢 Ming-Wei Chang、Jonathan H. Clark、Kenton Lee 和 Jennimaria Palomaki 的深入讨论和支持。还要感谢 Ashwin Kakarla 及其团队对注释的帮助。
评论