越来越多的应用程序由在不同加速器上训练的大型复杂神经网络驱动。这一过程由 ML 编译器促进,它将高级计算图映射到低级、特定于设备的可执行文件。在此过程中,ML 编译器需要解决许多优化问题,包括图重写、设备操作分配、操作融合、张量布局和平铺以及调度。例如,在设备布局问题中,编译器需要确定计算图中的操作与目标物理设备之间的映射,以便可以最小化目标函数(如训练步骤时间)。布局性能由多种复杂因素决定,包括设备间网络带宽、峰值设备内存、共置约束等,这使得启发式算法或基于搜索的算法面临挑战,因为这些算法通常满足于快速但次优的解决方案。此外,启发式算法很难开发和维护,尤其是在出现新的模型架构时。
最近尝试使用基于学习的方法已经取得了不错的成果,但它们也存在一些局限性,使得它们无法在实践中部署。首先,这些方法不容易推广到看不见的图,尤其是那些来自较新的模型架构的图;其次,它们的样本效率很差,导致训练期间资源消耗很高。最后,它们只能解决单个优化任务,因此无法捕获编译堆栈中紧密耦合的优化问题之间的依赖关系。
在最近作为NeurIPS 2020口头论文发表的“ML 编译器的可转移图优化器”中,我们提出了一种端到端、可转移的深度强化学习方法,用于计算图优化 (GO),该方法克服了上述所有限制。与TensorFlow默认优化相比,我们在三个图优化任务上实现了 33%-60% 的加速。在由多达 80,000 个节点组成的多样化代表性图集上,包括Inception-v3、Transformer-XL和WaveNet,GO 比专家优化平均提高了 21%,比之前的最先进水平提高了 18%,收敛速度提高了 15 倍。
机器学习编译器中的图优化问题
机器学习编译器中经常出现三项耦合优化任务,我们将其表述为决策问题,可以使用学习策略来解决。每项任务的决策问题都可以重新定义为对计算图中的每个节点做出决策。
第一个优化任务是设备放置,其目标是确定如何最好地将图的节点分配给其运行的物理设备,以最小化端到端运行时间。
第二个优化任务是操作调度。当计算图中的操作的传入张量存在于设备内存中时,该操作即可运行。一种常用的调度策略是为每个设备维护一个就绪操作队列,并按先进先出的顺序调度操作。但是,这种调度策略没有考虑到可能被操作阻止的其他设备上的下游操作,并且经常导致调度时设备利用率不足。为了找到可以跟踪这种跨设备依赖关系的调度,我们的方法使用基于优先级的调度算法,该算法根据每个操作的优先级调度就绪队列中的操作。与设备放置类似,操作调度可以表述为学习策略的问题,该策略为图中的每个节点分配优先级,以根据运行时间最大化奖励。
第三个优化任务是操作融合。为简洁起见,我们在此省略了对该问题的详细讨论,而只是指出,与基于优先级的调度类似,操作融合也可以使用基于优先级的算法来决定融合哪些节点。在这种情况下,策略网络的目标仍然是为图中的每个节点分配一个优先级。
最后,重要的是要认识到,在这三个优化问题中做出的决策可能会影响其他问题的最佳决策。例如,将两个节点放在两个不同的设备上会有效地禁用融合并引入可能影响调度的通信延迟。
RL 策略网络架构
我们的研究提出了 GO,这是一个深度 RL 框架,可以适应解决上述每个优化问题——既可以单独解决,也可以联合解决。所提出的架构有三个关键方面:
首先,我们使用图神经网络(特别是GraphSAGE)来捕获计算图中编码的拓扑信息。GraphSAGE 的归纳网络利用节点属性信息来推广到以前从未见过的图,这使得能够针对从未见过的数据进行决策,而无需花费大量训练成本。
其次,许多模型的计算图通常包含超过 10k 个节点。要在如此大规模上有效地解决优化问题,网络需要能够捕获节点之间的长距离依赖关系。GO 的架构包括一个可扩展的注意力网络,该网络使用段级递归来捕获此类长距离节点依赖关系。
第三,ML 编译器需要解决来自不同应用领域的各种图形的优化问题。使用异构图形训练共享策略网络的简单策略不太可能捕捉特定类别图形的特性。为了克服这个问题,GO 使用了一种特征调制机制,允许网络专门针对特定图形类型,而无需增加参数数量。
为了联合解决多个依赖优化任务,GO 能够为每个任务添加额外的循环注意力层,并在不同任务之间共享参数。具有动作残差连接的循环注意力层可以跟踪任务间的依赖关系。
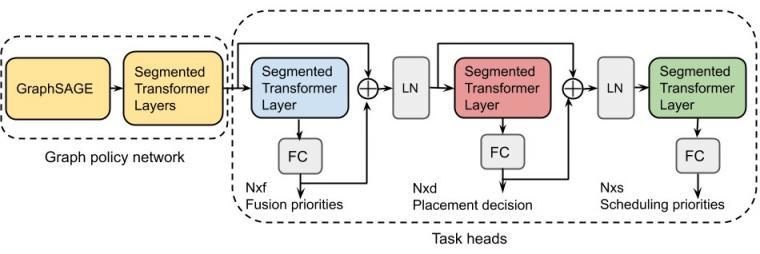
多任务策略网络,通过为每个任务和残差连接添加额外的循环注意层来扩展 GO 的策略网络。GE:图形嵌入,FC:全连接层,Nxf:融合动作维度,Fxd:放置动作维度,Nxs:调度动作维度。
结果
接下来,我们将展示基于真实硬件测量的设备放置任务的单任务加速评估结果、具有不同 GO 变体的看不见的图的推广以及联合优化操作融合、设备放置和调度的多任务性能。
加速
为了评估此架构的性能,我们将 GO 应用于基于真实硬件评估的设备放置问题,首先我们在每个工作负载上分别训练模型。这种方法称为GO-one,其表现始终优于专家手动放置 (HP)、TensorFlow METIS放置和分层设备放置(HDP)——当前最先进的基于强化学习的设备放置。重要的是,凭借高效的端到端单次放置,GO-one 的放置网络收敛时间比 HDP 快 15 倍。
我们的实证结果表明,GO-one 的表现始终优于专家布局、TensorFlow METIS 布局和分层设备布局(HDP)。由于 GO 的设计方式可以扩展到由超过 80,000 个节点组成的超大图,例如 8 层Google 神经机器翻译(GNMT) 模型,因此它的表现优于以前的方法,包括 HDP、REGAL和Placeto。GO对 GNMT 等大型图实现了优化的图运行时间,分别比 HP 和 HDP 快 21.7% 和 36.5%。总体而言,与 HP 和 HDP 相比,GO-one 在 14 个不同图集中平均缩短了 20.5% 和 18.2% 的运行时间。重要的是,凭借高效的端到端单次布局,GO-one的布局网络收敛时间比 HDP 提高了 15 倍。
概括
GO 使用离线预训练,然后对未见图进行微调,从而推广到未见图。在预训练期间,我们在训练集中的异构图子集上训练 GO。我们在每一批这样的图上训练 GO 1000 步,然后再切换到下一批。然后,在保留图上对该预训练模型进行少于 50 步的微调(GO-generalization+finetune),这通常需要不到一分钟的时间。保留图的GO-generalization+finetune在所有数据集上的表现均优于专家布局和 HDP,平均水平与GO-one相当。
我们还直接在预训练模型上运行推理,而无需对目标保留图进行任何微调,并将其命名为GO-generalization-zeroshot 。这个未经调整的模型的性能仅比GO-generalization+finetune略差,同时略优于专家放置和 HDP。这表明图嵌入和学习到的策略都可以有效迁移,从而使模型可以推广到看不见的数据。
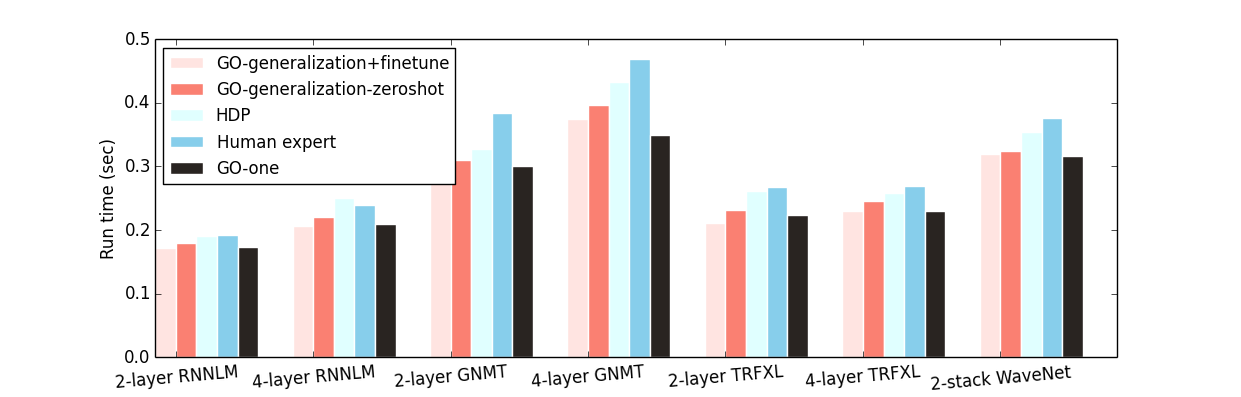
跨异构工作负载图的泛化。该图显示了使用 6 个工作负载中的 5 个(保留工作负载除外)的图表对 GO 进行训练时两种不同泛化策略的比较(Inception-v3、AmoebaNet、循环神经网络语言模型(RNNLM)、谷歌神经机器翻译(GNMT)、Transformer-XL (TRFXL)、WaveNet),并在保留工作负载(x 轴)上进行评估。
共同优化布局、调度和融合 (pl+sch+fu)
同时优化布局、调度和融合可使速度比单 GPU 未优化的情况提高 30%-73%,与 TensorFlow 默认布局、调度和融合相比可使速度提高 33%-60%。与单独优化每个任务相比,多任务 GO ( pl+sch+fu ) 比单任务 GO ( p | sch | fu )(一次优化所有任务)平均高出 7.8%。此外,对于所有工作负载,同时优化所有三个任务比优化其中任意两个任务并对第三个任务使用默认策略可提供更快的运行时间。
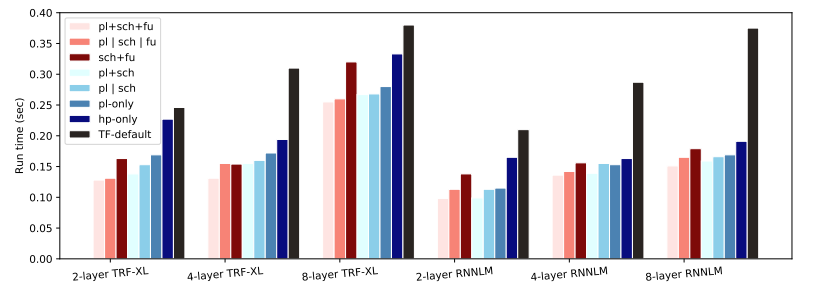
多任务优化中各种工作负载的运行时间。TF-default:TF GPU 默认放置、融合和调度。hp-only:仅使用默认调度和融合进行人工放置。pl-only:仅使用默认调度和融合进行 GO 放置。pl | sch:GO 使用默认融合单独优化放置和调度。pl+sch:多任务 GO 使用默认融合共同优化放置和调度。sch+fu:多任务 GO 与人工放置共同优化调度和融合。pl | sch | fu:GO 分别优化放置、调度和融合。pl+sch+fu:多任务 GO 共同优化放置、调度和融合。
结论
硬件加速器日益复杂且多样化,使得开发稳健且适应性强的 ML 框架变得繁重且耗时,通常需要数百名工程师多年的努力。在本文中,我们证明了此类框架中的许多优化问题都可以通过精心设计的学习方法高效且最优地解决。
致谢
这是与 Daniel Wong、Amirali Abdolrashidi、Peter Ma、Qiumin Xu、Hanxiao Liu、Mangpo Phitchaya Phothilimthana、Shen Wang、Anna Goldie、Azalia Mirhoseini 和 James Laudon 的合作作品。
评论