回顾过去的照片可以帮助人们重温一些最珍贵的时刻。去年 12 月,我们推出了电影照片,这是 Google Photos 的一项新功能,旨在重现拍照时的沉浸感,通过推断图像中的 3D 表示来模拟相机运动和视差。在这篇文章中,我们将介绍这一过程背后的技术,并展示电影照片如何将过去的一张 2D 照片变成更具沉浸感的 3D 动画。

相机 3D 模型由Rick Reitano提供。
深度估计
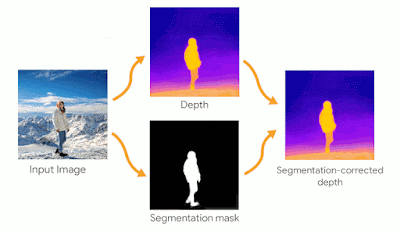
与人像模式和增强现实(AR) 等许多近期的计算摄影功能一样,电影照片需要深度图来提供有关场景 3D 结构的信息。智能手机上计算深度的典型技术依赖于多视角立体成像,这是一种几何方法,通过同时在不同视点拍摄多张照片来解决场景中物体的深度问题,其中摄像头之间的距离是已知的。在 Pixel 手机中,视图来自两个摄像头或双像素传感器。
为了在非多视角立体拍摄的现有照片上实现电影效果,我们训练了一个具有编码器-解码器架构的卷积神经网络,以便仅从单个 RGB 图像预测深度图。仅使用一个视角,该模型就学会了使用单眼线索(例如物体的相对大小、线性透视、散焦模糊等) 来估计深度。
由于单目深度估计数据集通常是为 AR、机器人和自动驾驶等领域设计的,因此它们往往强调街景或室内场景,而不是休闲摄影中更常见的特征,如人物、宠物和物体,这些特征具有不同的构图和取景。因此,我们使用在自定义 5 摄像头装置上拍摄的照片以及在 Pixel 4 上拍摄的肖像照片数据集创建了自己的数据集,用于训练单目深度模型。这两个数据集都包含来自多视角立体图像的真实深度,这对于训练模型至关重要。
以这种方式混合多个数据集可使模型接触到更多种类的场景和相机硬件,从而提高其对野外照片的预测能力。然而,这也带来了新的挑战,因为不同数据集的真实深度可能因未知的缩放因子和偏移而彼此不同。幸运的是,电影照片效果只需要场景中物体的相对深度,而不是绝对深度。因此,我们可以在训练期间使用缩放和偏移不变损失来组合数据集,然后在推理时对模型的输出进行规范化。
电影照片效果对深度图在人物边界处的准确性特别敏感。深度图中的错误可能会导致最终渲染效果出现不和谐的伪影。为了缓解这种情况,我们应用中值滤波来改善边缘,并使用在Open Images 数据集上训练的DeepLab分割模型推断照片中任何人的分割蒙版。蒙版用于将深度图中被错误预测为位于背景的像素向前拉。
相机轨迹
在 3D 场景中为摄像机制作动画时,可以有多种自由度,我们的虚拟摄像机设置灵感来自专业摄像机装置,用于创建电影动作。其中一部分是确定虚拟摄像机旋转的最佳枢轴点,以便通过将观众的视线吸引到拍摄对象上来获得最佳效果。
3D 场景重建的第一步是通过将 RGB 图像挤压到深度图上来创建网格。通过这样做,网格中的相邻点可以具有较大的深度差异。虽然从“正面”视图中看不出这一点,但虚拟相机移动得越多,就越有可能看到跨越深度大变化的多边形。在渲染的输出视频中,这看起来就像输入纹理被拉伸了一样。在为虚拟相机制作动画时,最大的挑战是找到一条引入视差的轨迹,同时尽量减少这些“拉伸”伪影。

当相机远离“正面”视图时,网格中深度差异较大的部分会变得更加明显(红色可视化)。在这些区域,照片看起来被拉伸了,我们称之为“拉伸伪影”。
由于用户照片及其对应的 3D 重建的范围很广,因此不可能在所有动画中共享一条轨迹。相反,我们定义了一个损失函数来捕捉最终动画中可以看到多少拉伸,这使我们能够针对每张照片优化相机参数。与计算被识别为伪影的像素总数不同,损失函数在具有更多连接伪影像素的区域触发得更严重,这反映了观看者更容易注意到这些连接区域中的伪影的倾向。
我们利用人体姿势网络中的填充分割蒙版将图像划分为三个不同的区域:头部、身体和背景。在将最终损失计算为归一化损失的加权和之前,在每个区域内对损失函数进行归一化。理想情况下,生成的输出视频没有伪影,但实际上这种情况很少见。对区域进行不同的加权会使优化过程产生偏差,从而选择更倾向于背景区域中的伪影而不是图像主体附近的伪影的轨迹。

在相机轨迹优化过程中,目标是为相机选择一条可察觉伪影最少的路径。在这些预览图像中,输出中的伪影被标记为红色,而绿色和蓝色叠加层则可显示不同的身体部位。
构建场景
一般来说,重新投影的 3D 场景无法整齐地放入纵向矩形中,因此还需要以正确的宽高比框定输出,同时仍保留输入图像的关键部分。为了实现这一点,我们使用深度神经网络来预测整幅图像的每像素显著性。在 3D 框定虚拟摄像头时,模型会识别并捕获尽可能多的显著区域,同时确保渲染的网格完全占据每个输出视频帧。这有时需要模型缩小摄像头的视野。

预测的每像素显著性的热图。我们希望在构图虚拟相机时,创作能够尽可能多地包含显著区域。
结论
通过电影照片,我们实施了一套算法系统,每个机器学习模型都经过公平性评估,这些算法协同工作,让用户以新的方式重温记忆,我们对未来的研究和功能改进感到兴奋。现在您知道了它们是如何创建的,请留意 Google Photos 应用中可能出现在您近期记忆中的自动创建的电影照片!

致谢
Cinematic Photos 是 Google Research 和 Google Photos 团队合作的成果。主要贡献者还包括:Andre Le、Brian Curless、Cassidy Curtis、Ce Liu、Chun-po Wang、Daniel Jenstad、David Salesin、Dominik Kaeser、Gina Reynolds、Hao Xu、Hayato Ikoma、Huiwen Chang、Huizhong Chen、Jamie Aspinall、Janne Kontkanen、Matthew DuVall、Michael Kucera、Michael Milne、Mike Krainin、Mike Liu、Navin Sarma、Orly Liba、Peter Hedman、Rocky Cai、Ruirui Jiang、Steven Hickson、Tracy Gu、Tyler Zhu、Varun Jampani、Yuan Hao 和 Zhongli Ding。
评论