网络上有数千万个数据集,内容涵盖传感器数据和政府记录,到科学实验结果和商业报告。事实上,几乎任何东西都有数据集,无论是帝王企鹅的饮食还是远程工作者的居住地。两年多前,我们致力于设计一个搜索引擎,为这些数百万个数据集和数千个存储库提供单一入口点。结果就是数据集搜索,我们于 2018 年推出测试版,并于 2020 年 1 月全面推出。除了方便访问数据之外,数据集搜索还使用直接来自数据集网页的元数据描述(采用schema.org结构)来协调和索引数据集。
截至今天,完整的数据集搜索语料库包含来自 4,600 多个互联网域的 3100 多万个数据集。这些数据集中约有一半来自 .com 域,但 .org 和政府域也占了很大比例。下图显示了过去两年语料库的增长情况,虽然我们仍然不知道网络上的数据集中目前有多少部分在数据集搜索中,但这个数字仍在稳步增长。
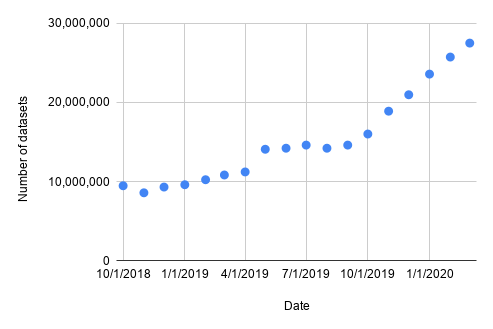
数据集搜索索引的数据集数量增长
为了更好地了解通过数据集搜索提供的数据集的广度和实用性,我们发表了“ Google 数据集搜索数据”,该报告已在2020 年国际语义网会议上被接受。我们在此概述了可用的数据集,介绍了源自其分析的指标和见解,并提出了发布未来科学数据集的最佳实践。为了让其他研究人员能够使用元数据构建分析和工具,我们还将公开一部分数据。
一系列数据集主题
为了确定数据集所涵盖主题的分布,我们根据数据集标题和描述以及数据集网页上的其他文本推断研究类别。最常见的两个主题是地球科学和社会科学,约占数据集的 45%。生物学紧随其后,约占 15%,其次是其他主题,分布大致均匀,包括计算机科学、农业和化学等。
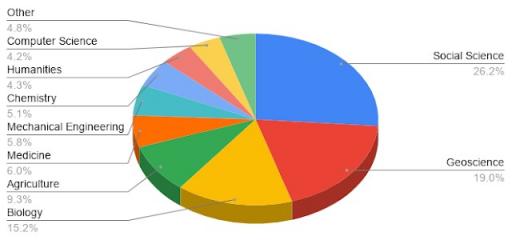
数据集主题分布
在我们最初推出数据集搜索的努力中,我们联系了特定的社区,这是引导语料库广泛使用的关键。最初,我们专注于地球科学和社会科学,但从那时起,我们让语料库有机地发展。我们惊讶地发现,与我们早期接触的社区相关的领域仍然主导着语料库。虽然他们早期的参与肯定有助于他们的流行,但可能还有其他因素,例如不同社区的文化差异。例如,地球科学在使其数据可查找、可访问、可互操作和可重用 ( FAIR ) 方面尤其成功,这是减少访问障碍的核心组成部分。
使数据易于引用和重复使用
各个科学领域的研究人员 越来越一致地认为,提供数据集、发布与数据集使用相关的细节以及在使用数据集时引用数据集非常重要。许多资助机构和学术出版商都要求对数据进行适当的发布和引用。
同行评审期刊(例如《Nature Scientific Data》 )致力于发布有价值的数据集,而DataCite等机构则为这些数据集提供数字对象标识符(DOI)。解析服务(例如identifiers.org)也提供持久的、可取消引用的标识符,以便于引用,这是使数据集在科学论述中广泛可用的关键。不幸的是,我们发现语料库中只有大约 11% 的数据集(或约 300 万个)有 DOI。我们从数据集语料库中选择了这个子集包含在我们的开源版本中。从这个集合中,大约有 230 万个数据集来自两个网站,datacite.org和figshare.com:
领域 带 DOI 的数据集
figshare.com 1,301千
数据引用站 1,070千
narcis.nl 11.8万
openaire.eu 10万
数据发现工作室 7.2万
osti.gov 6.3万
zenodo.org 5万
研究门户网 41千
达拉德 4万
发布者可以通过 schema.org 元数据属性指定数据集的访问要求,包括许可证的详细信息以及表明数据集是否可以免费访问的信息。只有 34% 的数据集指定了许可证信息,但如果没有指定许可证,用户就无法假设他们是否被允许重复使用数据。因此,添加许可信息,最好添加尽可能开放的许可证,将大大提高数据的可重用性。
在指定了许可证的数据集中,我们能够在 72% 的情况下识别出已知许可证。这些许可证包括英国和加拿大的开放政府许可证、知识共享许可证和多个公共领域许可证(例如,公共领域标志 1.0)。我们发现这些数据集中有 89.5% 可以免费访问或使用允许重新分发的许可证,或者两者兼而有之。在这些开放数据集中,有 560 万(91%)允许商业再利用。
数据可重用性的另一个关键组成部分是提供可下载的数据,但只有 44% 的数据集在其元数据中指定了下载信息。这个令人惊讶的低值的一个可能解释是,网站管理员(或数据集托管平台)担心通过 schema.org 元数据公开数据下载链接可能会导致搜索引擎或其他应用程序向其用户授予直接下载数据的权限,从而“窃取”其网站的流量。另一个担忧可能是数据需要适当的上下文才能得到恰当的使用(例如方法、脚注和许可信息),而提供商认为只有他们的网页才能提供完整的信息。在数据集搜索中,我们不会将下载链接显示为数据集元数据的一部分,因此用户必须前往发布者的网站下载数据,在那里他们才能看到数据集的完整上下文。
用户访问什么?
最后,我们研究数据集搜索的使用方式。总体而言,2020 年 5 月 14 天内,来自 2.6K 个域的 2.1M 个唯一数据集出现在前 100 个数据集搜索结果中。我们发现查询主题的分布与整个语料库的分布不同。例如,地球科学占比要小得多,相反,生物学和医学占比要大得多。这一结果可能是由我们的分析时间所致,因为它是在 COVID-19 大流行的头几周进行的。
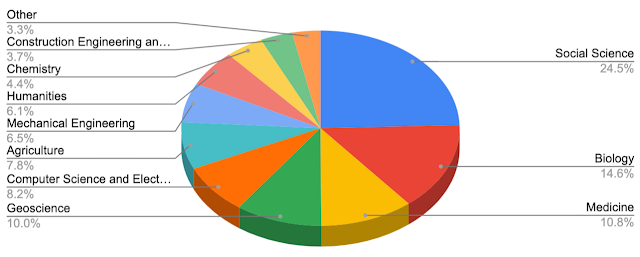
搜索结果中出现的数据集所涵盖的主题分布
发布科学数据集的最佳实践
根据我们的分析,我们确定了一组可以改善数据集的发现、重用和引用方式的最佳实践。
可发现性
数据集元数据应位于网络爬虫可访问的页面上,并以机器可读的格式提供元数据,以提高可发现性。
持久性
在可能比个人网页更持久的网站上发布元数据将有助于数据重用和引用。事实上,在我们对数据集搜索的分析中,我们注意到了非常高的周转率——许多有一天托管数据集的 URL 在几周或几个月后就没有了。数据存储库(例如Figshare、Zenodo、DataDryad、Kaggle Datasets和许多其他存储库)是确保数据集持久性的好方法。其中许多存储库与图书馆达成了永久保存数据的协议。
出处
由于数据集通常发布在多个存储库中,因此存储库在元数据中更明确地描述出处信息将大有裨益。出处信息可帮助用户了解谁收集了数据、数据集的主要来源在哪里,或者它可能发生了哪些变化。
许可
数据集应包含许可信息,最好采用机器可读的格式。我们的分析表明,当数据集提供商选择许可证时,他们倾向于选择相当开放的许可证。因此,鼓励和帮助科学家为其数据选择许可证将导致更多数据集公开可用。
分配永久标识符(例如 DOI)
DOI 对于长期跟踪和可用性至关重要。这些标识符不仅可以更轻松地引用数据集和版本跟踪,而且还可以取消引用:如果数据集移动,标识符可以指向不同的位置。
发布具有持久标识符的数据集的元数据
作为今天公告的一部分,我们还将发布我们的语料库的一个子集供其他人使用。它包含三百多万个具有 DOI 和其他类型持久标识符的数据集的元数据——这些数据集最容易被引用。研究人员可以使用这些元数据进行更深入的分析或使用这些数据构建自己的应用程序。例如,DOI 使用量的大部分增长似乎发生在过去十年内。这个时间范围与语料库中涵盖的数据集有何关系?DOI 使用分布在各个数据集之间是否均匀,还是研究社区之间存在显著差异?
我们将定期更新数据集。最后,我们希望此次数据发布将重点放在具有永久可引用标识符的数据集上,这将鼓励更多数据提供者更详细地描述他们的数据集,并使它们更容易被引用。
总之,我们希望通过 Google 数据集搜索等工具让数据更易于发现,这将鼓励科学家更广泛地分享他们的数据,并以真正公平的 方式进行。
致谢
这篇文章反映了整个数据集搜索团队的工作成果。我们感谢 Shiyu Chen、Dimitris Paparas、Katrina Sostek、Yale Cong、Marc Najork 和 Chris Gorgolewski 的贡献。我们还要感谢 Hal Varian 提出此分析建议并提供了很多有用的想法。
评论