最近的研究表明,监督 强化学习(RL) 能够超越模拟场景,合成现实世界中的复杂行为,例如抓取任意物体或学习敏捷运动。然而,使用精心设计的任务特定奖励函数来教代理执行复杂行为的局限性也变得明显。设计奖励函数可能需要大量的工程工作,这对于大量任务来说是站不住脚的。对于许多实际场景,设计奖励函数可能很复杂,例如需要为环境配备额外的仪器(例如,用于检测门方向的传感器)或手动标记“目标”状态。考虑到这种奖励工程形式限制了生成复杂行为的能力,无监督学习本身就是 RL 的一个有趣方向。
在监督强化学习中,来自环境的外在奖励函数会引导代理朝着所需的行为方向发展,强化那些为环境带来所需变化的动作。在无监督强化学习中,代理使用内在奖励函数(例如好奇心,尝试环境中的不同事物)来生成自己的训练信号,以获得广泛的与任务无关的行为。内在奖励函数可以绕过设计外在奖励函数的问题,同时具有通用性,可广泛适用于多个代理和问题,无需任何额外设计。虽然最近有很多研究 集中在无监督强化学习的不同方法上,但它仍然是一个严重受限的问题——如果没有环境奖励的指导,很难学习有用的行为。代理与环境交互中是否存在有意义的属性,可以帮助发现代理的更好行为(“技能”)? 在这篇文章中,我们介绍了两篇最近的出版物,它们开发了用于技能发现的新型无监督强化学习方法。在“动态感知无监督技能发现”(DADS)中,我们将“可预测性”的概念引入了无监督学习的优化目标。在这项研究中,我们假设技能的一个基本属性是它们会带来可预测的环境变化。我们在无监督技能发现算法中捕捉到了这个想法,并展示了它在各种模拟机器人设置中的适用性。在我们的后续工作“通过无监督的离线策略强化学习实现现实世界机器人技能”中
”,我们提高了 DADS 的采样效率,以证明无监督技能发现在现实世界中是可行的。

左侧的行为是随机且不可预测的,而右侧的行为则表现出系统性运动,环境变化可预测。我们的目标是学习右侧等可能有用的行为,而无需设计奖励函数。
DADS 概述
DADS 设计了一种内在奖励函数,鼓励发现“可预测”和“多样化”的技能。如果 (a) 环境变化对于不同的技能是不同的(鼓励多样性)和 (b) 给定技能的环境变化是可预测的(可预测性) ,则内在奖励函数很高。由于 DADS 不会从环境中获得任何奖励,因此优化技能以使其多样化可以使代理捕获尽可能多的潜在有用行为。
为了确定技能是否可预测,我们训练了另一个神经网络,称为技能动态网络,以在给定当前状态和正在执行的技能时预测环境状态的变化。技能动态网络越能预测环境状态的变化,技能就越“可预测”。可以使用任何常规强化学习算法来最大化 DADS 定义的内在奖励。
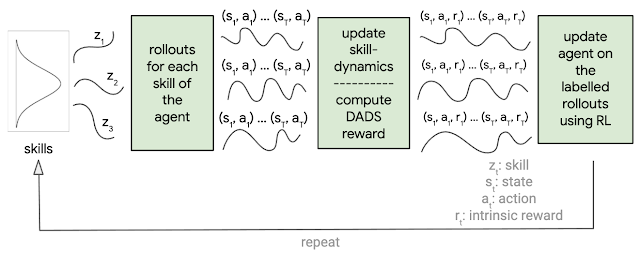
DADS 概述。
该算法使多个不同的代理能够仅从与环境的无奖励交互中发现可预测的技能。与以前的工作不同,DADS 可以扩展到高维连续控制环境,例如Humanoid(一种模拟双足机器人)。由于 DADS 与环境无关,因此它可以应用于运动和操作导向的环境。我们展示了不同连续控制代理发现的一些技能。

Ant发现了奔跑(左上)和跳跃(左下),Humanoid 发现了不同的运动步态(中间,速度加快 2 倍),ROBEL的D'Claw(右)发现了旋转物体的不同方式,所有这些都使用了 DADS。更多示例视频可在此处查看。
使用技能动态的基于模型的控制
DADS 不仅能够发现可预测且潜在有用的技能,还能提供一种有效的方法将学到的技能应用到下游任务中。我们可以利用学到的技能动态来预测每项技能的状态转换。可以将预测的状态转换链接在一起,以模拟任何学到的技能的完整状态轨迹,而无需在环境中执行它。因此,我们可以模拟不同技能的轨迹,并选择在给定任务中获得最高奖励的技能。此处描述的基于模型的规划方法可以非常节省样本,因为不需要对技能进行额外的训练。这比以前的方法有了很大的进步,以前的方法需要在环境中进行额外的训练来结合学到的技能。
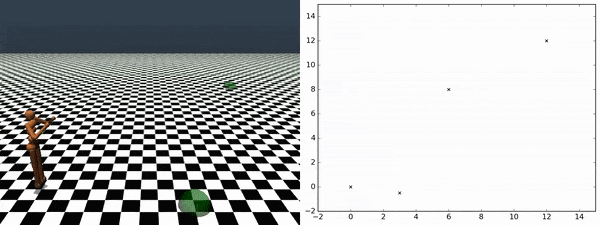
利用代理发现的技能,我们可以遍历任意检查点序列,而无需任何额外训练。右侧的图表跟踪代理从一个检查点到另一个检查点的遍历。
现实世界的结果
在现实世界的机器人技术中,无监督学习的展示相当有限,结果仅限于模拟环境。在“通过无监督离策略强化学习实现现实世界机器人技能”中,我们通过离策略学习设置中的算法和系统改进,开发了早期算法的样本高效版本,称为离 DADS。离策略学习能够使用从不同策略收集的数据来改进当前策略。特别是,重复使用以前收集的数据可以显著提高强化学习算法的样本效率。利用离策略学习的改进,我们从随机策略初始化开始在现实世界中训练D'Kitty (来自ROBEL 的四足动物),没有任何来自环境的奖励或手工制作的探索策略。通过优化 DADS 定义的内在奖励,我们观察到具有多种步态和方向的复杂行为的出现。


使用 off-DADS,我们训练ROBEL的 D'Kitty获得不同的运动行为,然后可以通过基于模型的控制用于目标导航。
未来工作
我们贡献了一种具有广泛适用性的新型无监督技能发现算法,可以在现实世界中执行。这项工作为未来的工作奠定了基础,机器人可以用最少的人力解决广泛的任务。一种可能性是研究状态表示与 DADS 发现的技能之间的关系,以学习一种鼓励发现已知下游任务分布的技能的状态表示。另一个有趣的探索方向是制定将高级规划和低级控制分开的技能动力学,并研究其对强化学习问题的普遍适用性。
致谢
我们要感谢我们的合著者 Michael Ahn、Sergey Levine、Vikash Kumar、Shixiang Gu 和 Karol Hausman。我们还要感谢 Google Brain 团队和 Google 机器人团队的各位成员提供的支持和反馈。
评论