计算机视觉研究人员的普遍看法是,现代深度神经网络总是渴望获得更多的标记数据——目前最先进的 CNN 需要在OpenImages或Places等数据集上进行训练,这些数据集包含超过 100 万张标记图像。但是,对于许多应用而言,收集如此大量的标记数据可能会让普通从业者望而却步。
缓解计算机视觉任务缺乏标记数据的一种常见方法是使用已在通用数据(例如ImageNet )上进行预训练的模型。其理念是,在通用数据上学习到的视觉特征可以重新用于感兴趣的任务。尽管这种预训练在实践中效果相当好,但它仍然缺乏快速掌握新概念和在不同语境中理解它们的能力。与BERT和T5在语言领域取得的进步类似,我们相信大规模预训练可以提高计算机视觉模型的性能。 在“大迁移 (BiT):通用视觉表征学习”中,我们设计了一种使用超出事实标准 ( ILSVRC-2012 ) 规模的图像数据集对通用特征进行有效预训练的方法。特别是,我们强调了随着预训练数据量的增加,适当选择规范化层和扩展架构容量的重要性。我们的方法展现出前所未有的性能,可适应各种新的视觉任务,包括小样本识别设置和最近推出的“真实世界” ObjectNet基准。我们很高兴与大家分享在公共数据集上预训练的最佳 BiT 模型,以及TF2、Jax 和 PyTorch 中的代码。这将使任何人都可以在他们感兴趣的任务上达到最先进的性能,即使每个类别只有少量标记图像。预训练 为了研究数据规模的影响,我们使用三个数据集重新审视了预训练设置的常见设计选择(例如激活和权重的标准化、模型宽度/深度和训练计划):ILSVRC-2012(128 万张图像,1000 个类别)、ImageNet-21k(1400 万张图像,约 21000 个类别)和JFT(3 亿张图像,约 18000 个类别)。重要的是,利用这些数据集,我们专注于以前未被充分探索的大数据领域。 我们首先研究数据集大小和模型容量之间的相互作用。为此,我们训练了经典的ResNet
架构,性能良好,同时简单且可重复。我们在上述每个数据集上训练从标准 50 层深“R50x1”到 4 倍宽和 152 层深“R152x4”的变体。一个关键的观察是,为了从更多数据中获利,还需要增加模型容量。下图左侧面板中的红色箭头说明了这一点
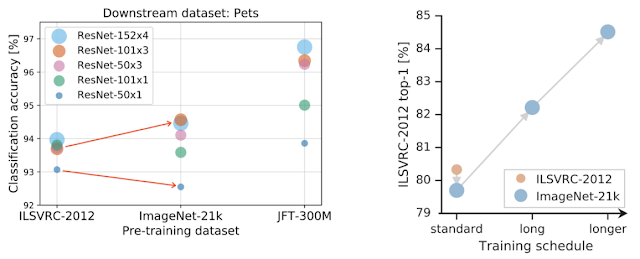
左图:为了有效利用更大的数据集进行预训练,需要增加模型容量。红色箭头说明了这一点:在更大的 ImageNet-21k 上进行预训练时,小型架构(较小的点)会变得更糟,而较大的架构(较大的点)会有所改善。右图:仅在更大的数据集上进行预训练并不一定能提高性能,例如从 ILSVRC-2012 转到相对更大的 ImageNet-21k 时。但是,通过增加计算预算和延长训练时间,性能改进会很明显。
第二个更重要的观察结果是,训练持续时间变得至关重要。如果在较大的数据集上进行预训练而不调整计算预算并延长训练时间,则性能可能会变差。但是,通过调整计划以适应新的数据集,改进效果会非常显著。
在探索阶段,我们发现了另一个对提高性能至关重要的修改。我们表明,用组规范化(GN) 替换批量规范化(BN,一种常用的层,通过规范激活来稳定训练)有利于大规模预训练。首先,BN 的状态 (神经激活的均值和方差) 需要在预训练和迁移之间进行调整,而 GN 是无状态的,因此可以避开这个困难。其次,BN 使用批量级统计数据,对于大型模型不可避免的每设备批量较小,这变得不可靠。由于 GN 不计算批量级统计数据,因此它也可以避开这个问题。有关更多技术细节,包括使用权重标准化技术来确保稳定行为,请参阅我们的论文。
迁移学习遵循BERT
在语言领域建立的方法,我们根据来自各种感兴趣的“下游”任务的数据对预训练的 BiT 模型进行微调,这些数据可能带有很少的标记数据。由于预训练模型已经对视觉世界有了很好的理解,所以这种简单的策略非常有效。 微调需要选择很多超参数,如学习率、权重衰减等。我们提出了一种选择这些超参数的启发式方法,我们称之为“BiT-HyperRule”,它仅基于高级数据集特征,如图像分辨率和标记示例的数量。我们成功地将 BiT-HyperRule 应用于 20 多个不同的任务,从自然图像到医学图像。
当将 BiT 迁移到样本很少的任务时,我们观察到,随着我们同时增加用于预训练的通用数据量和架构容量,生成的模型适应新数据的能力会大幅提高。在 1 次和 5 次 CIFAR(见下图)上,在 ILSVRC 上进行预训练时,增加模型容量的回报有限(绿色曲线)。然而,在 JFT 上进行大规模预训练时,模型容量的每次提升都会带来巨大的回报(棕色曲线),最高可达 BiT-L,1 次训练可达到 64%,5 次训练可达到 95%。
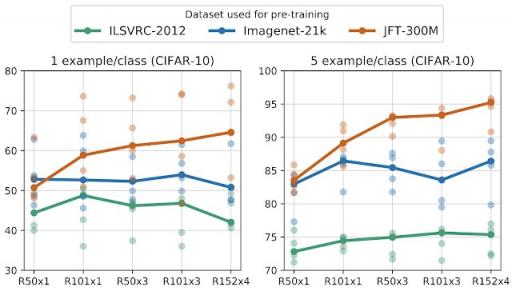
曲线描绘了在将模型转移到 CIFAR-10 时,每类仅 1 或 5 张图像(总共 10 或 50 张图像)的 5 次独立运行(亮点)的平均准确率。显然,在大型数据集上预先训练的大型架构的数据效率明显更高。
为了验证此结果的普遍性,我们还在VTAB-1k上评估了 BiT ,VTAB-1k 是一套包含 19 个不同任务的任务,每个任务只有 1000 个标记示例。我们将 BiT-L 模型迁移到所有这些任务中,总体得分达到 76.3%,比之前的最佳成绩绝对提升了 5.8% 。
通过在几个标准计算机视觉基准(如 Oxford Pets and Flowers、CIFAR等)上评估 BiT-L,我们证明了这种大规模预训练和简单迁移的策略即使在数据量适中的情况下仍然有效。在所有这些基准上,BiT-L 都达到或超过了最佳成绩。最后,我们在MSCOCO-2017检测任务上使用 BiT 作为RetinaNet的骨干,并确认即使对于这种结构化输出任务,使用大规模预训练也会有很大帮助。
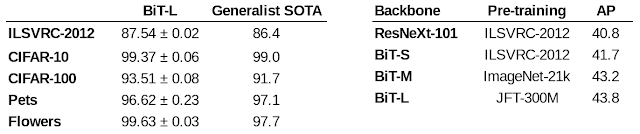
左图: BiT-L 与之前最先进的通用模型在各种标准计算机视觉基准上的准确率对比。右图:在 MSCOCO-2017 上使用 BiT 作为 RetinaNet 主干的平均准确率 (AP) 结果。
需要强调的是,在我们考虑的所有不同的下游任务中,我们不会针对每个任务执行超参数调整,而是依赖于BiT-HyperRule。正如我们在论文中所展示的,通过在足够大的验证数据上调整超参数,可以获得更好的结果。
使用 ObjectNet 进行评估为了进一步评估 BiT 在更具挑战性的场景中的稳健性,我们在最近推出的ObjectNet
数据 集上评估了在 ILSVRC-2012 上微调的 BiT 模型。该数据集与现实世界场景非常相似,其中对象可能出现在非典型的上下文、视点、旋转等中。有趣的是,数据和架构规模带来的好处更加明显,BiT-L 模型实现了前所未有的 80.0% 的 top-5 准确率,比之前的最先进水平绝对提高了近 25% 。
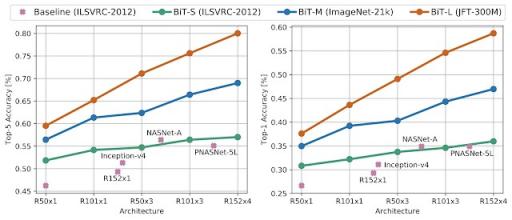
BiT 在 ObjectNet 评估数据集上的结果。左:top-5 准确率,右:top-1 准确率。
结论
我们表明,在对大量通用数据进行预训练后,简单的迁移策略可带来令人印象深刻的结果,无论是在大型数据集上,还是在数据量非常小的任务上,甚至每个类别只有一张图像。 我们发布了BiT-M 模型,即在 ImageNet-21k 上预训练的 R152x4,以及用于在 Jax、TensorFlow2 和 PyTorch 中迁移的 colab。 除了发布代码外,我们还向读者介绍了如何使用 BiT 模型的TensorFlow2 动手教程。 我们希望从业者和研究人员发现它是常用 ImageNet 预训练模型的有用替代方案。
致谢
我们要感谢共同撰写 BiT 论文并参与其各个开发环节的 Xiaohua Zhai、Joan Puigcerver、Jessica Yung、Sylvain Gelly 和 Neil Houlsby,以及苏黎世的 Brain 团队。 我们还要感谢 Andrei Giurgiu 在调试输入管道方面提供的帮助。我们感谢 Tom Small 制作了本博文中使用的动画。 最后,我们向感兴趣的读者推荐了 Google Research、 Noisy Student 的同事在这方面提出的相关方法,以及 Facebook Research 高度相关的探索弱监督预训练的极限。
评论