在过去的几年中,自然语言生成 (NLG) 的研究取得了巨大进步,现在的模型能够以越来越高的复杂程度的方法翻译文本、总结文章、参与对话和评论图片,并且准确度达到了前所未有的水平。目前,评估这些 NLG 系统的方法有两种:人工评估和自动指标。人工评估是指使用人工注释者对模型的每个新版本进行大规模质量调查,但这种方法可能非常耗费人力。相反,可以使用流行的自动指标(例如BLEU),但这些指标往往无法可靠地替代人工的解释和判断。NLG 的快速发展和现有评估方法的缺陷要求开发新方法来评估 NLG 系统的质量和成功率。 在“ BLEURT:学习用于文本生成的稳健指标”(在ACL 2020期间提出)中,我们介绍了一种新颖的自动指标,它可以提供稳健且达到前所未有的质量水平的评分,更接近人工注释。 BLEURT(基于 Transformers 表示的双语评估研究)基于迁移学习的最新进展,用于捕捉广泛的语言现象,例如释义。该指标可在Github上找到。评估 NLG 系统 在人工评估中,一段生成的文本会呈现给注释者,注释者负责评估其流畅性和含义方面的质量。文本通常与参考文献并排显示,参考文献由人工撰写或从 Web 中挖掘。
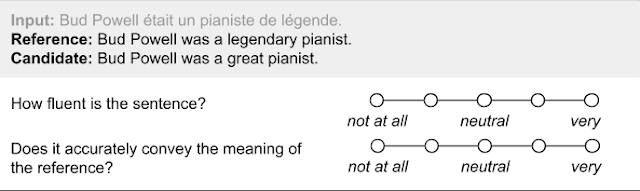
用于机器翻译中人工评估的示例问卷。
这种方法的优点是准确:在评估一段文本的质量方面,人类仍然是无与伦比的。然而,这种评估方法很容易就需要几天的时间,而且仅仅几千个示例就需要数十人参与,这会破坏模型开发工作流程。相比之下
,自动指标背后的想法是为人工质量测量提供一种廉价、低延迟的代理。自动指标通常以两个句子作为输入,一个候选句子和一个参考句子,它们返回一个分数,该分数表明前者与后者的相似程度,通常使用词汇重叠。一个流行的指标是 BLEU,它计算候选句子中也出现在参考句子中的单词序列(BLEU 分数与准确率非常相似)。
自动指标的优点和缺点与人工评估的优点和缺点相反。自动指标很方便——它们可以在整个训练过程中实时计算(例如,使用 Tensorboard 绘图)。然而,由于它们关注的是表面层次的相似性,它们往往不准确,无法捕捉人类语言的多样性。通常,有许多完全有效的句子可以传达相同的含义。完全依赖词汇匹配的重叠度量标准不公平地奖励那些在表面形式上与参考相似的句子,即使它们不能准确捕捉含义,并惩罚其他释义。

三个候选句子的 BLEU 得分。候选 2 在语义上接近参考句子,但其得分低于候选 3。
理想情况下,NLG 的评估方法应兼具人工评估和自动指标的优势——计算成本应相对较低,但又应足够灵活以应对语言多样性。BLEURT
简介 BLEURT是一种基于机器学习的新型自动指标,可以捕捉句子之间非平凡的语义相似性。它基于一组公开的评分( WMT Metrics Shared Task数据集)以及用户提供的其他评分
进行训练。

BLEURT 评分的三个候选句子。BLEURT 发现候选句子 2 与参考句子相似,尽管它包含的非参考单词比候选句子 3 多。
创建基于机器学习的指标提出了一个根本挑战:该指标应该在广泛的任务和领域中始终表现良好,并且随着时间的推移。然而,训练数据量有限。事实上,公开数据非常稀疏——WMT Metrics Task 数据集是本文撰写时最大的人工评分集合,仅包含约 26 万个仅涵盖新闻领域的人工评分。这太有限了,无法训练出适合未来 NLG 系统评估的指标。为了解决这个问题,我们采用了迁移学习。首先,我们使用BERT
的上下文词表示,BERT 是一种用于语言理解的最先进的无监督表示学习方法,已经成功纳入 NLG 指标(例如 YiSi 或 BERTscore)。 其次,我们引入了一种新颖的预训练方案来提高 BLEURT 的稳健性。我们的实验表明,直接在公开的人工评分上训练回归模型是一种脆弱的方法,因为我们无法控制将在哪个领域和在什么时间跨度内使用该指标。如果出现领域漂移,即所用文本与训练句对来自不同的领域,准确率可能会下降。如果出现质量漂移,即预测评分高于训练期间使用的评分,准确率也可能会下降 — — 这通常是个好消息,因为它表明机器学习研究正在取得进展。BLEURT 的成功依赖于使用数百万个合成句对“热身”模型,然后再根据人工评分进行微调。我们通过对来自 Wikipedia 的句子施加随机扰动来生成训练数据。我们没有收集人工评分,而是使用来自文献(包括 BLEU)的一系列指标和模型,这可以以非常低的成本增加训练示例的数量。

BLEURT 的数据生成过程将随机扰动和评分与预先存在的指标和模型相结合。
实验表明,预训练可显著提高 BLEURT 的准确率,尤其是在测试数据分布不均的情况下。
我们对 BLEURT 进行了两次预训练,第一次使用语言建模目标(如原始 BERT 论文中所述),第二次使用一组 NLG 评估目标。然后,我们在 WMT Metrics 数据集、用户提供的一组评分或两者结合的基础上对模型进行微调。下图从端到端说明了 BLEURT 的训练过程。
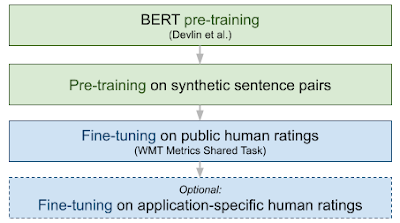
结果
我们对 BLEURT 与其他竞争方法进行了对比,结果表明 BLEURT 性能卓越,与 WMT Metrics Shared Task(机器翻译)和 WebNLG Challenge(数据转文本)上的人工评分高度相关。例如,在 2019 年的 WMT Metrics Shared Task 上,BLEURT 的准确率比 BLEU 高出约 48%。我们还证明了预训练有助于 BLEURT 应对质量漂移。

WMT'19 指标共享任务中不同指标与人工评分之间的相关性。
结论
随着 NLG 模型的不断改进,评估指标已成为该领域研究的重要瓶颈。基于重叠的指标如此受欢迎是有充分理由的:它们简单、一致,并且不需要任何训练数据。在每个候选词都有多个参考句子的用例中,它们可以非常准确。虽然它们在我们的基础设施中起着关键作用,但它们也非常保守,只能提供 NLG 系统性能的不完整图景。我们的观点是,机器学习工程师应该用更灵活的语义级指标来丰富他们的评估工具包。BLEURT
是我们试图捕捉表面重叠之外的 NLG 质量的尝试。得益于 BERT 的表示和新颖的预训练方案,我们的指标在两个学术基准上产生了 SOTA 性能,我们目前正在研究如何改进 Google 产品。未来的研究包括研究多语言性和多模态性。
致谢
该项目由 Dipanjan Das 共同指导。我们感谢 Slav Petrov、Eunsol Choi、Nicholas FitzGerald、Jacob Devlin、Madhavan Kidambi、Ming-Wei Chang 以及 Google 研究语言团队的所有成员。
评论