深度强化学习 (deep RL) 的最新进展使腿式机器人能够通过自动化环境交互学习许多敏捷技能。在过去的几年中,研究人员通过使用离策略数据、模仿动物行为或进行元学习,大大提高了样本效率。然而,样本效率仍然是大多数深度强化学习算法的瓶颈,尤其是在腿式运动领域。此外,现有大多数研究仅关注简单的低级技能,例如前进、后退和转弯。为了在现实世界中自主运行,机器人仍然需要结合这些技能来产生更高级的行为。
今天,我们介绍两个旨在解决上述问题并帮助关闭腿式机器人的感知-驱动回路的项目。在“腿式机器人的数据高效强化学习”中,我们提出了一种学习低级运动控制策略的有效方法。通过为机器人拟合动力学模型并实时规划动作,机器人使用不到 5 分钟的数据即可学习多种运动技能。除了简单的行为之外,我们在“四足机器人运动的分层强化学习”中探索了自动路径导航。借助专为端到端训练而设计的策略架构,机器人可以学习将高级规划策略与低级运动控制器相结合,以便自主导航通过弯曲路径。
腿式机器人的数据高效强化学习 强化学习的一个主要障碍是缺乏样本效率。即使使用像Soft Actor-Critic
(SAC) 这样的最先进的样本高效学习算法,也需要一个多小时的数据来学习合理的步行策略,这在现实世界中很难收集。 为了继续努力通过与现实世界环境的最少交互来学习步行技能,我们提出了另一种基于模型的、样本效率更高的基本步行技能学习方法,该方法大大减少了所需的训练数据。我们不是直接学习从环境状态映射到机器人动作的策略,而是学习机器人的动力学模型,该模型可以根据机器人的当前状态和动作来估计未来状态。由于整个学习过程需要的数据不到 5 分钟,因此可以直接在真实机器人上进行。 我们首先在机器人上执行随机动作,并将模型与收集的数据进行拟合。拟合模型后,我们使用模型预测控制来控制机器人
(MPC)规划器。我们在使用 MPC 收集更多数据和重新训练模型之间进行迭代,以更好地适应环境的动态。
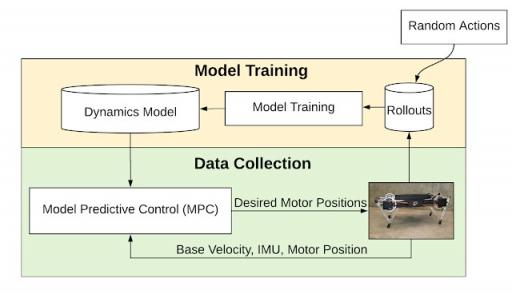
基于模型的学习流程概述。系统交替使用模型预测控制 (MPC) 拟合动态模型和收集轨迹。
在标准 MPC 中,控制器会在每个时间步骤规划一系列动作,并且只执行规划动作中的第一个。虽然在线重新规划以及机器人向控制器的定期反馈使控制器能够应对模型不准确性,但它也给动作规划器带来了挑战,因为规划必须在控制回路的下一步之前完成(对于有腿机器人,通常少于 10 毫秒)。为了满足如此严格的时间限制,我们引入了 MPC 的多线程异步版本,动作规划和执行在不同的线程上进行。由于执行线程以高频率应用动作,因此规划线程会在后台不间断地优化动作。此外,由于动作规划可能需要多个时间步骤,因此在规划完成时机器人状态会发生变化。为了解决规划延迟问题,我们设计了一种新颖的补偿技术,它首先预测规划器预计完成计算时的未来状态,然后使用该未来状态来为规划算法提供种子。
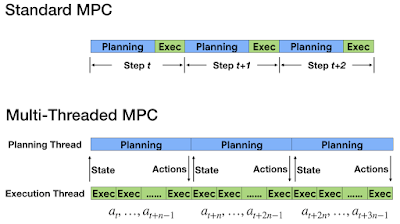
我们将动作的规划和执行放在不同的线程上。
尽管 MPC 会频繁刷新行动计划,但规划器仍需要在长期行动范围内工作,以跟踪长期目标并避免短视行为。为此,我们使用多步骤损失函数,这是模型损失函数的重新表述,通过预测未来步骤范围内的损失,有助于减少随时间的误差累积。
安全性是真实机器人学习的另一个考虑因素。对于有腿的机器人,一个小错误(例如脚步未迈)都可能导致灾难性的故障,从机器人摔倒到电机过热。为了确保安全探索,我们嵌入了一个稳定的、原地踏步步态先验,由轨迹生成器进行调制。有了稳定的行走先验,MPC 便可以安全地探索动作空间。
将精确的动力学模型与在线异步 MPC 控制器相结合,机器人仅使用 4.5 分钟的数据(36 个情节)就成功学会了行走。学习到的动力学模型也是可推广的:只需改变 MPC 的奖励函数,控制器就能针对不同的行为进行优化,例如向后行走或转弯,而无需重新训练。作为扩展,我们使用类似的框架来实现更敏捷的行为。例如,在模拟中,机器人学会了后空翻和用后腿行走,尽管这些行为尚未被真正的机器人学会。

机器人仅使用 4.5 分钟的数据即可学会行走。

机器人使用相同的框架学习后空翻和用后腿行走。
将低级控制器与高级规划相结合
虽然基于模型的 RL 使机器人能够有效地学习简单的运动技能,但这些技能不足以处理复杂的现实世界任务。 例如,为了在办公空间中导航,机器人可能需要多次调整其速度、方向和高度,而不是遵循预定义的速度曲线。 传统上,人们通过将此类复杂任务分解为多个分层子问题来解决它们,例如高级轨迹规划器和低级轨迹跟随控制器。 然而,手动定义合适的层次结构通常是一项繁琐的任务,因为它需要对每个子问题进行仔细的工程设计。
在我们的第二篇论文中,我们介绍了一个分层强化学习 (HRL) 框架,该框架可以训练为自动分解复杂的强化学习任务。 我们将策略结构分解为高级和低级策略。 我们不是手动设计每个策略,而是只在策略级别之间定义一个简单的通信协议。在这个框架中,高级策略(例如轨迹规划器)通过潜在命令来指挥低级策略(例如运动控制策略),并决定在发出新命令之前将该命令保持多长时间不变。然后,低级策略解释来自高级策略的潜在命令,并向机器人发出运动命令。
为了促进学习,我们还将观察空间分为高级(例如机器人位置和方向)和低级(IMU、电机位置)观察,这些观察被输入到相应的策略中。这种架构自然允许高级策略以比低级策略更慢的时间尺度运行,从而节省计算资源并降低训练复杂性。
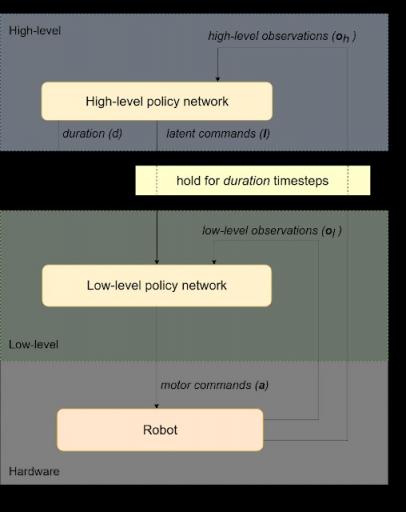
分层策略框架:策略从机器人获取观察结果并发送电机命令以执行所需动作。它分为两个级别(高级和低级)。高级策略向低级策略发出潜在命令,并决定低级策略运行的持续时间。
由于高级和低级策略在离散时间尺度上运行,因此整个策略结构不是端到端可微的,并且无法使用基于梯度的标准 RL 算法(如PPO和SAC) 。相反,我们选择通过增强随机搜索(ARS) 来训练分层策略,这是一种简单的进化优化方法,已在强化学习任务中表现出色。策略的两个级别的权重一起训练,目标是最大化机器人轨迹的总奖励。
我们使用同一个四足机器人在路径跟踪任务上测试我们的框架。除了直线行走外,机器人还需要朝不同方向转向才能完成任务。请注意,由于低级策略不知道机器人在路径中的位置,因此它没有足够的信息来独自完成整个任务。但是,通过高级和低级策略之间的协调,转向行为会自动出现在潜在命令空间中,从而使机器人能够高效地完成路径。在模拟环境中成功训练后,我们通过将 HRL 策略转移到真实机器人并记录产生的轨迹来在硬件上验证结果。

机器人在弯曲路径上的成功轨迹。左图:机器人行进轨迹的图,轨迹上的点标记了高级策略向低级策略发送新潜在命令的位置。中图:机器人在模拟环境中沿着路径行走。右图:机器人在现实世界中沿着路径行走。
为了进一步展示所学习的分层策略,我们将所学习的低级策略在不同潜在命令下的行为可视化。如下图所示,不同的潜在命令可使机器人直行,或以不同的速率左转或右转。我们还通过将低级策略转移到类似领域的新任务来测试其通用性,在我们的案例中,这包括遵循具有不同形状的路径。通过固定低级策略权重并仅训练高级策略,机器人可以成功遍历不同的路径。
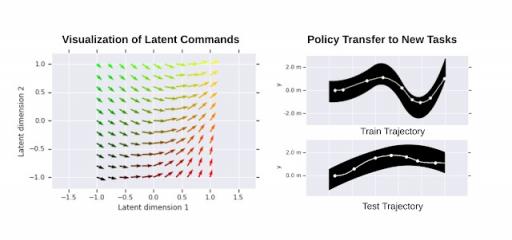
左图:学习到的 2D 潜在命令空间的可视化。向量方向对应于机器人的移动方向。向量长度与覆盖的距离成正比。右图:低级策略的迁移:在单个路径上训练 HRL 策略(右上)。然后在其他路径上训练高级策略时重新使用学习到的低级策略(例如右下)。
结论
强化学习通过自动化控制器设计过程为机器人技术带来了光明的未来。借助基于模型的强化学习,我们能够直接在真实机器人上高效学习可泛化的运动行为。借助分层强化学习,机器人学会了协调不同级别的策略来完成更复杂的任务。未来,我们计划将感知引入循环,以便机器人能够在现实世界中真正自主运行。
致谢
Deepali Jain 和 Yuxiang Yang 都是AI 驻留计划的驻留人员,由 Ken Caluwaerts 和 Atil Iscen 指导。我们还要感谢 Jie Tan 和 Vikas Sindhwani 对研究的支持,以及 Noah Broestl 对纽约 AI 驻留计划的管理。
评论