深度 神经网络(DNN) 是机器学习最新进展的基石,并推动了图像识别、图像分割、机器翻译等多种任务的最新突破。然而,尽管它们无处不在,研究人员仍在试图充分了解支配它们的潜在原理。特别是,传统设置中的经典理论(例如VC 维数和Rademacher 复杂度)表明过度参数化的函数对未见数据的表现不佳,但最近的研究发现,大量过度参数化的函数(参数比数据点数量多几个数量级)泛化良好。为了改进模型,需要更好地理解泛化,这可以导致更有理论基础、因而更有原则的 DNN 设计方法。理解泛化
的一个重要概念是泛化差距,即模型在训练数据上的性能与其在来自同一分布的未见数据上的性能之间的差异。在推导更好的 DNN 泛化界限(泛化差距的上限)方面,人们已经取得了重大进展,但它们仍然倾向于大大高估实际的泛化差距,从而无法解释为什么某些模型泛化得如此好。另一方面,边际的概念(数据点和决策边界之间的距离)已在支持向量机等浅层模型的背景下得到广泛研究,并且发现它与这些模型对看不见的数据的泛化能力密切相关。正因为如此,使用边际来研究泛化性能的方法已经扩展到 DNN,从而得到了高度精细的泛化差距理论上限,但并没有显著提高预测模型泛化能力的能力。
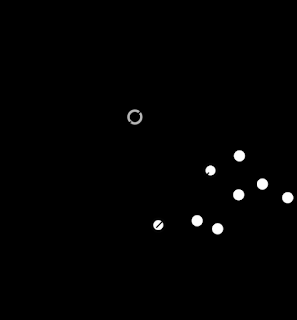
支持向量机决策边界的一个例子。由 w∙xb=0 定义的超平面是此线性分类器的“决策边界”,即,超平面上的每个点 x 在该分类器下属于任一类的可能性均相等。
在我们的ICLR 2019论文“使用边距分布预测深度网络中的泛化差距”中,我们提出使用跨网络层的归一化边距分布作为泛化差距的预测因子。我们通过实证研究了边距分布与泛化之间的关系,并表明,在对距离进行适当的归一化后,边距分布的一些基本统计数据可以准确预测泛化差距。我们还通过Github 存储库提供了所有用作研究泛化的数据集的模型。
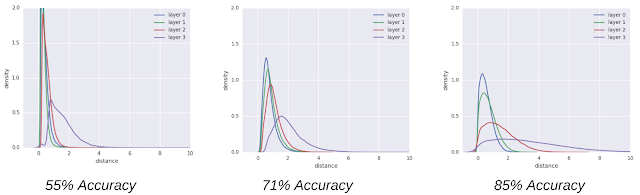
每个图都对应一个在CIFAR-10上训练的卷积神经网络,具有不同的分类准确率。图中显示了三个不同模型在网络 4 层上的归一化边距分布(x 轴)的概率密度(y 轴),这些模型的泛化能力越来越好(从左到右)。归一化边距分布与测试准确率密切相关,这表明它们可以用作预测网络泛化能力差距的指标。有关这些网络的更多详细信息,请参阅我们的论文。
边际分布作为泛化的预测因子
直观地看,如果边际分布的统计数据确实可以预测泛化性能,那么一个简单的预测方案就应该能够建立这种关系。因此,我们选择线性回归作为预测因子。我们发现泛化差距与边际分布的对数变换统计数据之间的关系几乎是完全线性的(见下图)。事实上,与其他现有的泛化指标相比,所提出的方案产生了更好的预测。这表明边际分布可能包含有关深度模型如何泛化的重要信息。
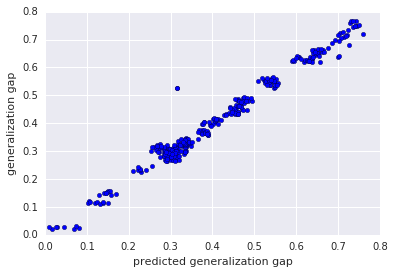
CIFAR-100 + ResNet-32上的预测泛化差距(x 轴)与真实泛化差距(y 轴)。这些点靠近对角线,这表明对数线性模型的预测值非常符合真实的泛化差距。
深度模型泛化数据集
除了我们的论文之外,我们还将介绍深度模型泛化(DEMOGEN)数据集,它包含 756 个经过训练的深度模型,以及它们在 CIFAR-10 和 CIFAR-100 数据集上的训练和测试性能。这些模型是 CNN(具有类似于Network-in-Network 的架构)和 ResNet-32 的变体,具有不同的流行正则化技术和超参数设置,从而产生了广泛的泛化行为。例如,在 CIFAR-10 上训练的 CNN 模型的测试准确率范围为 60% 到 90.5%,泛化差距范围为 1% 到 35%。有关数据集的详细信息,请参阅我们的论文或Github 存储库。作为数据集发布的一部分,我们还包含实用程序,以轻松加载模型并重现论文中提出的结果。
我们希望这项研究和 DEMOGEN 数据集能为社区提供一个易于使用的工具,用于研究深度学习中的泛化,而无需重新训练大量模型。我们还希望我们的研究结果能激发对隐藏层中的泛化差距预测因子和边际分布的进一步研究。
评论