机器学习 (ML) 的进步已显示出在协助医疗专业人员工作方面的巨大潜力,例如协助检测糖尿病眼病和转移性乳腺癌。虽然高性能算法对于赢得临床医生的信任和采用必不可少,但它们并不总是足够的——向医生呈现什么信息以及医生如何与这些信息互动,可能是决定 ML 技术最终对用户实用性的关键因素。解剖病理学
医学专业是通过对组织样本进行显微镜分析来诊断癌症和许多其他疾病的黄金标准,它可以从 ML 的应用中受益匪浅。虽然病理诊断传统上是在物理显微镜上进行的,但“数字病理学”的使用日益增多,其中可以在计算机上检查病理样本的高分辨率图像。这一运动带来了更容易查找信息的潜力,当病理学家处理疑难病例或罕见疾病的诊断时,“全科”病理学家处理专科病例时,以及病理学家实习生学习时都需要这些信息。在这种情况下,一个常见的问题出现了:“我看到的这个特征是什么?”传统的解决方案是医生询问同事,或者费力地浏览参考教科书或在线资源,希望找到具有相似视觉特征的图像。解决此类问题的通用计算机视觉解决方案称为基于内容的图像检索(CBIR),其中一个例子是Google 图片中的“反向图像搜索”功能,用户可以使用另一幅图像作为输入来搜索相似图像。今天,我们很高兴与大家分享两篇研究论文,它们描述了医学领域相似图像搜索 的人机交互研究的进一步进展。在发表于《自然合作期刊 (npj) 数字医学》的《组织病理学相似图像搜索:SMILY》中,我们报告了基于 ML 的病理学反向图像搜索工具。在我们的第二篇论文《以人为本的工具应对医疗决策过程中不完善的算法》(预印本可在此处获得)中,我们探索了基于图像的搜索的不同细化模式,并评估了它们对医生与 SMILY 互动的影响,该论文在2019 年 ACM CHI 计算机系统人为因素会议上获得了荣誉奖。SMILY设计
开发 SMILY 的第一步是应用深度学习模型,该模型使用 50 亿张自然、非病理图像(例如,狗、树、人造物体等)进行训练,将图像压缩为一个“摘要”数值向量,称为嵌入。网络在训练过程中学会了通过计算和比较嵌入来区分相似图像和不相似图像。然后使用该模型,使用来自Cancer Genome Atlas的去识别化幻灯片集,创建图像块及其相关嵌入的数据库。当在 SMILY 工具中选择查询图像块时,将以类似方式计算查询块的嵌入并将其与数据库进行比较,以检索具有最相似嵌入的图像块。
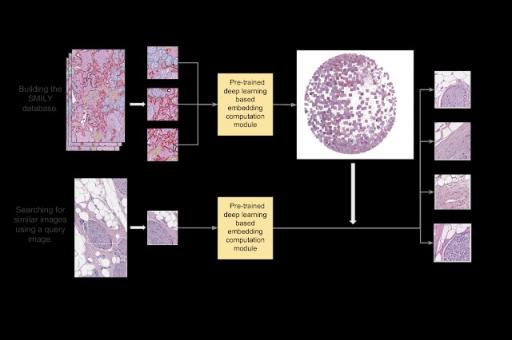
构建 SMILY 数据库的步骤示意图以及使用输入图像块执行相似图像搜索的过程。
该工具允许用户选择感兴趣的区域,并获得视觉上相似的匹配。我们使用来自乳房、结肠和前列腺(最常见的 3 个癌症部位)的组织图像测试了 SMILY 沿预先指定的相似性轴(例如组织学特征或肿瘤等级)检索图像的能力。我们发现,尽管没有针对病理图像进行专门训练或使用任何标记的组织学特征或肿瘤等级示例,SMILY 仍表现出令人鼓舞的结果。
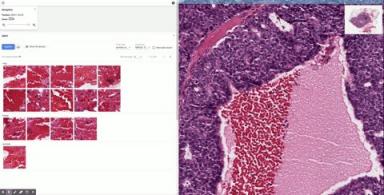
在幻灯片中选择一小块区域并使用 SMILY 检索类似图像的示例。SMILY 可在几秒钟内高效搜索数十亿张裁剪图像的数据库。由于病理图像可以在不同的放大倍数(缩放级别)下查看,因此 SMILY 会自动搜索与输入图像相同放大倍数的图像。
SMILY 的优化工具
然而,当我们观察病理学家如何与 SMILY 互动时,一个问题出现了。具体来说,用户试图回答“什么看起来与这张图片相似?”这个模糊的问题,以便他们可以从包含类似图像的过去案例中学习。然而,该工具无法理解搜索的意图:用户是在试图寻找具有相似组织学特征、腺体形态、整体结构还是其他特征的图像?换句话说,用户需要能够根据具体情况指导和优化搜索结果,以便真正找到他们想要的内容。此外,我们观察到,这种迭代搜索优化的需求源于医生经常进行“迭代诊断”的方式——通过生成假设、收集数据来测试这些假设、探索替代假设,并以迭代方式重新审视或重新测试以前的假设。很明显,为了让 SMILY 满足真正的用户需求,它需要支持不同的用户交互方式。通过第二篇论文
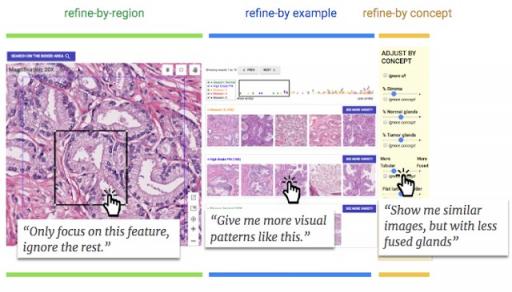
中描述的以人为本的细致研究,我们设计并增强了 SMILY,增加了一套交互式细化工具,使最终用户能够即时表达相似性的含义:1)按区域细化允许病理学家裁剪图像中感兴趣的区域,将搜索范围限制在该区域;2)按示例细化使用户能够选择搜索结果的子集并检索更多类似的结果;3)按概念细化滑块可用于指定搜索结果中出现的临床概念的多少(例如融合腺体)。我们并没有要求将这些概念内置到机器学习模型中,而是开发了一种方法,使最终用户能够事后创建新概念,根据他们认为对每个特定用例很重要的概念定制搜索算法。这使得机器学习模型在训练完成后可以通过事后工具进行新的探索,而无需为每个感兴趣的概念或应用重新训练原始模型。
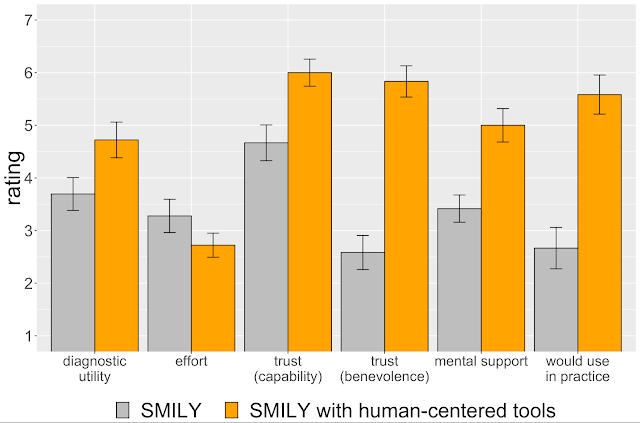
通过对病理学家进行的用户研究,我们发现基于工具的 SMILY 不仅提高了搜索结果的临床实用性,而且与不包含这些工具的传统 SMILY 版本相比,还显著提高了用户的信任度和采用的可能性。有趣的是,这些改进工具似乎不仅在相似性搜索中表现更好,还以其他方式支持了病理学家的决策过程。例如,病理学家利用迭代搜索结果中观察到的变化作为逐步跟踪假设可能性的手段。当搜索结果令人惊讶时,许多人会重新利用这些工具来测试和了解底层算法,例如,通过裁剪他们认为会干扰搜索的区域或通过调整概念滑块来增加他们怀疑被忽略的概念的存在。除了被动地接受机器学习结果之外,医生还被赋予了主动测试假设和应用其专业领域知识的权力,同时利用自动化的优势。
这些交互式工具使用户能够根据自己的意图定制每次搜索体验,我们很高兴看到 SMILY 有潜力帮助搜索大型数字化病理图像数据库。这项技术的一个潜在应用是索引带有描述性标题的病理图像教科书,并让医学生或受训病理学家使用视觉搜索搜索这些教科书,从而加快教育过程。另一个应用是让有兴趣研究肿瘤形态与患者结果相关性的癌症研究人员加速对类似病例的搜索。最后,病理学家可能能够利用 SMILY 等工具在同一患者的组织样本中定位某个特征的所有出现情况(例如活跃细胞分裂或有丝分裂的迹象),以更好地了解疾病的严重程度,从而为癌症治疗决策提供信息。重要的是,我们的研究结果进一步证明,复杂的机器学习算法需要与以人为本的设计和交互式工具相结合才能发挥最大作用。
致谢
如果没有 Jason D. Hipp、Yun Liu、Emily Reif、Daniel Smilkov、Michael Terry、Craig H. Mermel、Martin C. Stumpe 以及Google Health和PAIR的成员,这项工作就不可能完成。两篇论文的预印本可在此处和此处获取。
评论