表示实体之间关系的关系数据在网络(例如在线社交网络)和物理世界(例如蛋白质相互作用网络)中无处不在。此类数据可以表示为具有节点(例如用户、蛋白质)和连接节点(例如友谊关系、蛋白质相互作用)的边的图。鉴于图的广泛流行,图分析在机器学习中起着基础性的作用,可应用于聚类、链接预测、隐私和其他。要将机器学习方法应用于图(例如预测新的友谊或发现未知的蛋白质相互作用),需要学习一种适用于 ML 算法的图表示。 然而,图本质上是由节点和边等离散部分组成的组合结构,而许多常见的 ML 方法(如神经网络)则倾向于连续结构,尤其是向量表示。向量表示在神经网络中尤为重要,因为它们可以直接用作输入层。为了解决在机器学习中使用离散图形表示的困难,图形嵌入方法会学习图形的连续向量空间,将图形中的每个节点(和/或边)分配到向量空间中的特定位置。该领域的一种流行方法是基于随机游走的表示学习,如DeepWalk中所述。
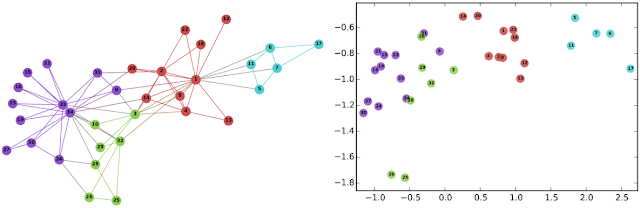
左图:代表社交网络的著名Karate图。右图:使用DeepWalk对图中的节点进行连续空间嵌入。
这里我们展示了最近两篇关于图嵌入的论文的结果:在WWW'19上发表的“单一嵌入就够了吗?学习可捕捉多种社交背景的节点表示”和在NeurIPS'18上发表的“小心脚下:通过图注意力学习节点嵌入” 。第一篇论文介绍了一种学习每个节点多个嵌入的新技术,从而能够更好地表征具有重叠社区的网络。第二篇论文解决了图嵌入中超参数调整的基本问题,使人们能够轻松部署图嵌入方法。我们也很高兴地宣布,我们已经在 Google Research github图嵌入存储库中发布了这两篇论文的代码。学习可捕捉多种社交背景的节点表示 在几乎所有情况下,标准图嵌入方法的关键假设是必须为每个节点学习一个嵌入。因此,可以说嵌入方法试图识别表征图的几何形状中每个节点的单一角色或位置。然而,最近的研究发现,现实网络中的节点属于多个重叠社区并扮演多个角色——想想你的社交网络,你既参与家庭社区,也参与工作社区。这一观察引发了以下研究问题:是否有可能开发出将节点嵌入多个向量中的方法,以表示它们在重叠社区中的参与? 在我们的WWW'19 论文中,我们开发了Splitter,这是一种无监督的嵌入方法,允许图中的节点具有多个嵌入,以更好地编码它们在多个社区中的参与。我们的方法基于基于自我网络分析的重叠聚类的最新创新,特别是使用角色图概念。此方法采用图G,并创建一个新图P(称为角色图),其中G中的每个节点由一系列称为角色的副本表示
节点。节点的每个角色都代表该节点在其所属的本地社区中的实例。对于图中的每个节点 U,我们分析节点的自我网络(即连接节点与其邻居的图,在此示例中为 A、B、C、D)以发现节点所属的本地社区。例如,在下图中,节点 U 属于两个社区:集群 1(与朋友 A 和 B 在一起,即 U 的家人)和集群 2(与 C 和 D 在一起,即 U 的同事)。
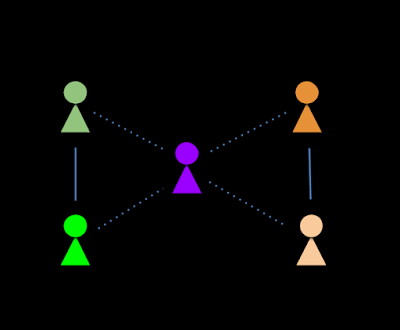
节点U的自我网络
然后,我们利用这些信息将节点 U “拆分”为两个角色U1(家庭角色)和 U2(工作角色)。这样就解开了两个社区,使它们不再重叠。
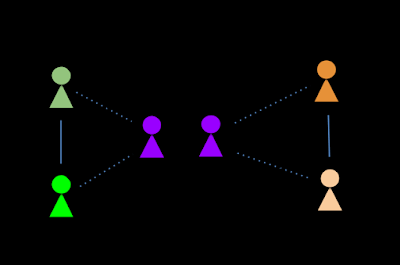
自我分裂方法将 U 节点分成 2 个角色。
该技术已用于改进图嵌入方法的最新成果,在各种图上将链接预测(即预测未来将形成哪种链接)错误率降低了 90%。这种改进的关键原因是该方法能够消除社交网络和其他现实世界图中发现的高度重叠社区的歧义。我们通过深入分析作者属于重叠研究社区(例如机器学习和数据挖掘)的合著者关系图来进一步验证这一结果。
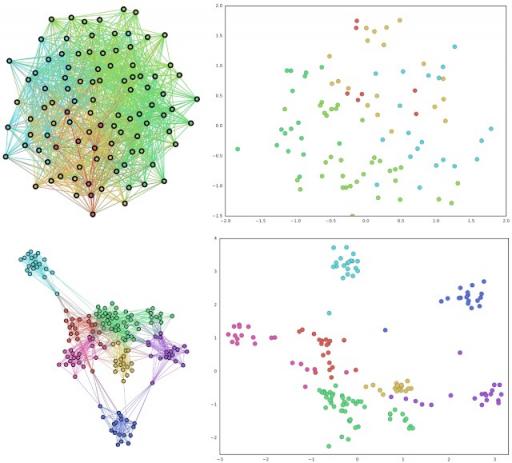
左上:典型的高度重叠社区图。右上:使用node2vec对左侧图进行传统嵌入。左下:上图的人物图。右下:人物图的Splitter嵌入。请注意人物图如何清晰地解开原始图的重叠社区,并且Splitter输出分离良好的嵌入。
通过图注意力机制自动调整超参数。
图嵌入方法在各种基于 ML 的应用(例如链接预测和节点分类)中都表现出色,但它们有许多必须手动设置的超参数。例如,在学习嵌入时,捕获附近的节点是否比捕获较远的节点更重要?尽管专家可以微调这些超参数,但必须针对每个图独立进行微调。为了避免这种手动工作,在我们的第二篇论文中,我们提出了一种自动学习最佳超参数的方法。
具体而言,许多图嵌入方法(例如DeepWalk)采用随机游走来探索给定节点周围的上下文(即直接邻居、邻居的邻居等)。这种随机游走可以具有许多超参数,允许调整图的局部探索,从而调节嵌入对附近节点的注意力。不同的图表可能呈现不同的最佳注意力模式,因此也呈现不同的最佳超参数(见下图,我们展示了两种不同的注意力分布)。Watch Your Step 根据上述超参数为嵌入方法的性能制定了一个模型。然后,我们使用标准反向传播优化超参数,以最大化模型预测的性能。我们发现,通过反向传播学习到的值与通过网格搜索获得的最佳超参数一致。
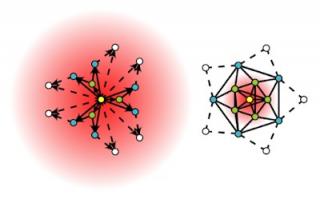
我们用于自动超参数调整的新方法 Watch Your Step 使用注意力模型来学习不同的图形上下文分布。上图显示了关于中心节点(黄色)的两个示例局部邻域以及模型学习到的上下文分布(红色渐变)。左侧图表显示了一个更加分散的注意力模型,而右侧的分布显示了一个集中在直接邻居上的模型。
这项工作属于不断壮大的AutoML 家族,我们希望减轻优化超参数的负担——这是实际机器学习中常见的问题。许多 AutoML 方法使用神经架构搜索。本文展示了一种变体,其中我们使用嵌入中的超参数与图论矩阵公式之间的数学联系。“自动”部分对应于通过反向传播学习图超参数。
我们相信我们的贡献将进一步推动图嵌入在各个方向上的研究状态。我们学习多节点嵌入的方法将丰富且研究充分的重叠社区检测领域与较新的图嵌入领域联系起来,我们相信这可能会带来富有成果的未来研究。该领域的一个未解决的问题是使用多嵌入方法进行分类。此外,我们在学习超参数方面的贡献将通过减少昂贵的手动调整需求来促进图嵌入的采用。我们希望这些论文和代码的发布将有助于研究界追寻这些方向。
致谢
我们感谢 Sami Abu-el-Haija 对本研究的贡献,他目前是南加州大学的博士生。有关图形挖掘团队(算法和优化的一部分)的更多信息,请访问我们的页面。
评论