几十年来,正如摩尔定律 所描述的,通过减小每个芯片内晶体管的尺寸,计算机处理器每隔几年就能将其性能提高一倍。随着减小晶体管尺寸变得越来越困难,业界重新将重点放在开发特定领域的架构(例如硬件加速器)上,以继续提高计算能力。对于机器学习来说尤其如此,其努力旨在构建用于神经网络 (NN) 加速的专用架构。具有讽刺意味的是,虽然这些架构在数据中心和边缘计算平台上稳步普及,但在其上运行的 NN 很少进行定制以利用底层硬件。
今天,我们很高兴地宣布发布EfficientNet-EdgeTPU,这是一系列源自EfficientNets的图像分类模型,但经过定制以在 Google 的Edge TPU上最佳运行,Edge TPU 是一种节能的硬件加速器,开发人员可通过Coral Dev Board和USB 加速器 使用。通过此类模型定制,Edge TPU 能够提供实时图像分类性能,同时实现通常只有在数据中心运行更大、计算量更大的模型时才能看到的准确度。使用 AutoML 为 Edge TPU 定制 EfficientNets EfficientNets已被证明可以在图像分类任务中实现最先进的准确度,同时显著降低模型大小和计算复杂度。为了构建旨在利用 Edge TPU 加速器架构的 EfficientNets,我们调用了AutoML MNAS 框架,并使用在 Edge TPU 上高效执行的构建块增强了原始 EfficientNet 的神经网络架构搜索空间(如下所述)。我们还构建并集成了一个“延迟预测器”模块,通过在周期精确的架构模拟器上运行模型,该模块提供了在 Edge TPU 上执行时模型延迟的估计值。AutoML MNAS 控制器实施强化学习算法来搜索这个空间,同时尝试最大化奖励,这是预测延迟和模型准确性的联合函数。根据以往的经验,我们知道当模型适合其片上内存时,Edge TPU 的功率效率和性能往往会达到最大化。因此,我们还修改了奖励函数,为满足此约束的模型生成更高的奖励。
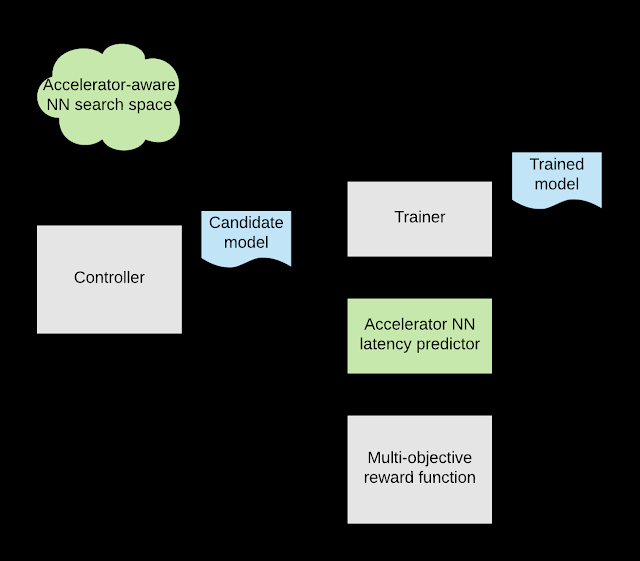
用于设计定制 EfficientNet-EdgeTPU 模型的整体 AutoML 流程。
搜索空间设计
在执行上述架构搜索时,必须考虑到 EfficientNets 主要依赖于深度可分离卷积,这是一种神经网络块,它可以分解常规卷积以减少参数数量和计算量。但是,对于某些配置,常规卷积可以更有效地利用 Edge TPU 架构并执行速度更快,尽管计算量要大得多。虽然可以手动制作一个使用不同构建块的最佳组合的网络,但很繁琐,使用这些加速器最佳块来增强 AutoML 搜索空间是一种更具可扩展性的方法。
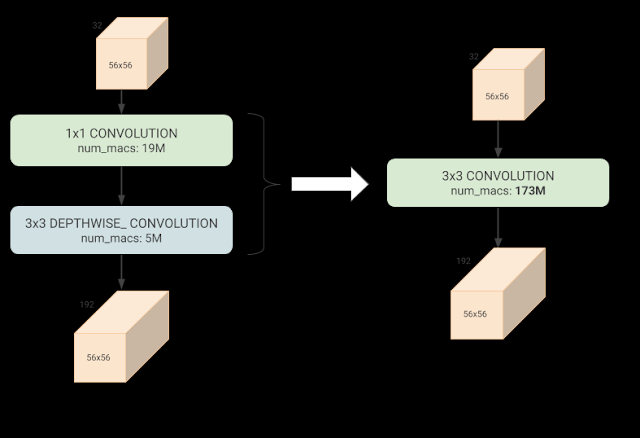
常规 3x3 卷积(右)比深度可分离卷积(左)具有更多的计算量(乘法和累加 (mac) 运算),但对于某些输入/输出形状,由于有效硬件利用率提高了约 3 倍,因此在 Edge TPU 上的执行速度更快。
此外,从搜索空间中删除某些需要修改 Edge TPU 编译器才能完全支持的操作(例如swish 非线性和squeeze-and-excitation 块),自然会导致模型可以轻松移植到 Edge TPU 硬件。这些操作往往会略微提高模型质量,因此通过将它们从搜索空间中消除,我们有效地指示 AutoML 发现可以弥补任何潜在质量损失的替代网络架构。
模型性能
上面描述的神经架构搜索 (NAS) 产生了一个基线模型 EfficientNet-EdgeTPU-S ,随后使用 EfficientNet 的复合缩放方法对其进行扩展以生成-M和-L模型。复合缩放方法选择输入图像分辨率缩放、网络宽度和深度缩放的最佳组合,以构建更大、更准确的模型。-M和-L模型以增加延迟为代价实现了更高的准确度,如下图所示。
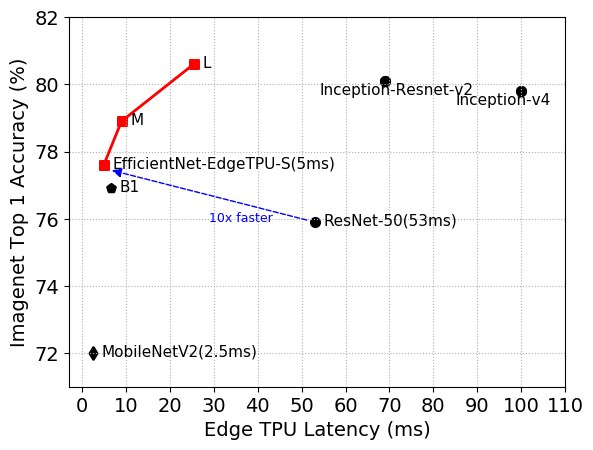
EfficientNet-EdgeTPU-S/M/L 模型通过专门针对 Edge TPU 硬件的网络架构,实现了比现有 EfficientNets (B1)、ResNet和Inception更好的延迟和准确性。特别是,我们的 EfficientNet-EdgeTPU-S 实现了更高的准确性,但运行速度比 ResNet-50 快 10 倍。
有趣的是,NAS 生成的模型在网络的初始部分广泛使用了常规卷积,而深度可分离卷积在加速器上执行时往往不如常规卷积有效。这清楚地表明,在为通用 CPU 优化模型时通常做出的权衡(例如减少总操作数)不一定是硬件加速器的最佳选择。此外,这些模型即使不使用深奥的操作也能实现高精度。与其他图像分类模型(如 Inception-resnet-v2 和 ResNet-50)相比,EfficientNet-EdgeTPU 模型不仅更准确,而且在 Edge TPU 上运行速度更快。
这项工作是使用 AutoML 构建加速器优化模型的首次实验。基于 AutoML 的模型定制不仅可以扩展到各种硬件加速器,还可以扩展到依赖神经网络的多种不同应用程序。
从 Cloud TPU 训练到 Edge TPU 部署我们已经在我们的github 存储库
上发布了 EfficientNet-EdgeTPU 的训练代码和预训练模型。我们使用 tensorflow 的训练后量化工具将浮点训练模型转换为与 Edge TPU 兼容的整数量化模型。对于这些模型,训练后量化效果非常好,并且仅产生非常轻微的准确度损失(~0.5%)。从训练检查点导出量化模型的脚本可以在这里找到。有关 Coral 平台的更新,请参阅Google 开发者博客上的这篇帖子,有关完整的参考资料和详细说明,请参阅Coral 网站。致谢特别感谢 Google Brain 团队的 Quoc Le、Hongkun Yu、Yunlu Li、Ruoming Pang 和 Vijay Vasudevan;Google Coral 团队的 Bo Wu、Vikram Tank 和 Ajay Nair;来自 Google Edge TPU 团队的 Han Vanholder、Ravi Narayanaswami、John Joseph、Dong Hyuk Woo、Raksit Ashok、Jason Jong Kyu Park、Jack Liu、Mohammadali Ghodrat、Cao Gau、Berkin Akin、Liang-Yun Wang、Chirag Gandhi 和 Dongdong Li,来自 Google Edge TPU 团队。
评论