全球有数亿人依靠公共交通进行日常通勤,而全球超过一半的交通出行都涉及公交车。随着全球城市不断增长,通勤者想要知道何时会出现延误,尤其是公交车,因为公交车很容易被交通堵塞。虽然谷歌地图提供的公共交通路线由许多提供实时数据的交通机构提供,但由于技术和资源限制,许多机构无法提供这些数据。
今天,谷歌地图推出了公交车实时交通延误功能,可预测全球数百个城市的公交车延误情况,包括亚特兰大、萨格勒布、伊斯坦布尔、马尼拉等。这提高了六千多万人的交通计时准确性。该系统三周前首次在印度推出,由机器学习模型驱动,将实时汽车交通预测与公交路线和站点数据相结合,以更好地预测公交车行程需要多长时间。
模型的开端
在许多没有来自交通机构的实时预报的城市,我们从接受调查的用户那里听说,他们采用了一种聪明的解决方法来粗略估计公交车延误时间:使用谷歌地图行车路线。但公交车不仅仅是大型汽车。它们会在公交车站停靠;需要更长的时间来加速、减速和转弯;有时甚至拥有特殊的道路权利,例如公交车专用道。
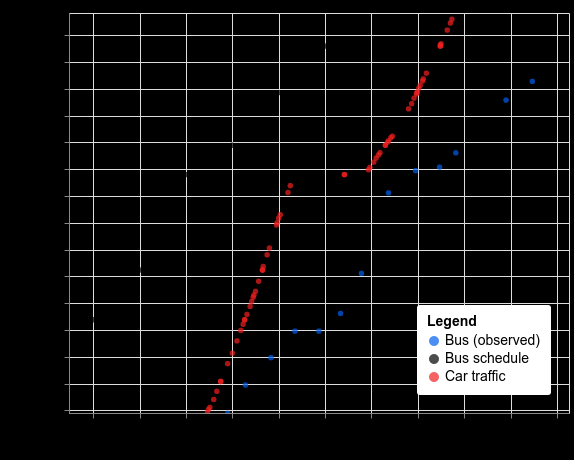
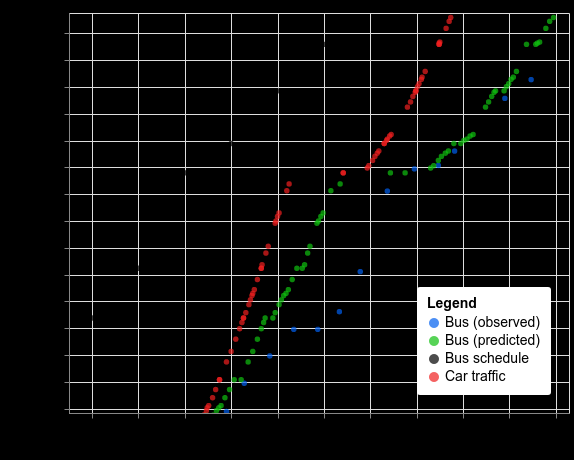
作为一个例子,让我们来看看周三下午在悉尼乘坐公交车的情况。公交车的实际运动(蓝色)比公布的时刻表(黑色)晚了几分钟。汽车交通速度(红色)确实会影响公交车,比如在 2000 米处减速,但在 800 米处长时间停车会使公交车的速度比汽车慢得多。
为了开发我们的模型,我们从公交机构实时反馈的随时间变化的公交车位置序列中提取了训练数据,并将它们与公交车在行程中行驶路径上的汽车交通速度进行校准。该模型被分成一系列时间线单元——访问街区和站点——每个单元对应公交车时间线的一部分,每个单元预测持续时间。由于报告不频繁、公交车行驶速度快以及街区和站点较短,一对相邻的观测值通常跨越多个单元。
这种结构非常适合神经序列模型,例如最近已成功应用于语音处理、机器翻译等的神经序列模型。我们的模型更简单。每个单元独立预测其持续时间,最终输出是每个单元预测的总和。与许多序列模型不同,我们的模型不需要学习组合单元输出,也不需要通过单元序列传递状态。相反,序列结构让我们能够共同(1)训练单个单元持续时间的模型,以及(2)优化“线性系统”,其中每个观察到的轨迹都会为其跨越的多个单元的总持续时间分配一个总持续时间。
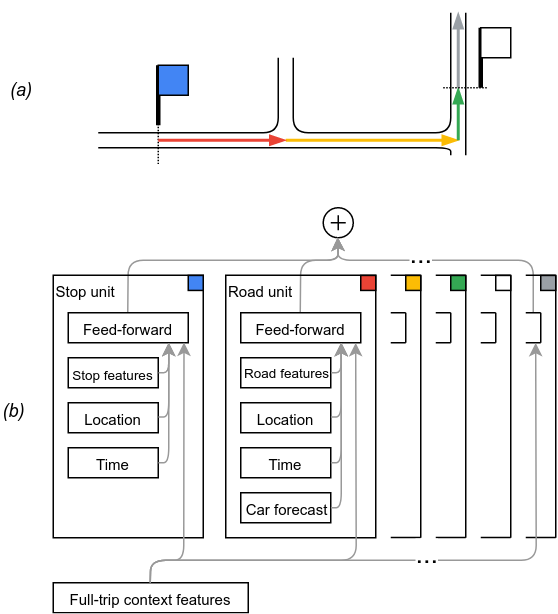
为了模拟从蓝色站点出发的公交车行程 (a),模型 (b) 将蓝色站点、三条路段、白色站点等时间线单元的延误预测相加。
对“地点”进行建模
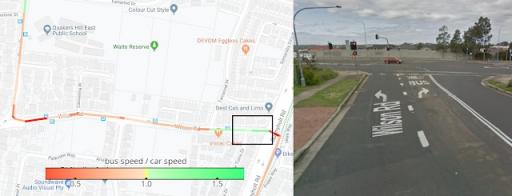
除了道路交通延误之外,在训练我们的模型时,我们还考虑了公交路线的详细信息,以及有关行程位置和时间的信号。即使在一个小的社区内,模型也需要将汽车速度预测转化为不同街道上的不同公交车速度。在下面的左侧面板中,我们用颜色编码了模型预测的公交行程中汽车速度和公交车速度之间的比率。红色较慢的部分可能对应于公交车在车站附近的减速。至于突出显示框中的快速绿色路段,我们从街景视图(右)中看到,我们的模型发现了一条公交专用转弯车道。顺便说一句,这条路线位于澳大利亚,那里的右转速度比左转慢,这是另一个不考虑位置特性的模型会忽略的方面。
为了捕捉特定街道、社区和城市的独特属性,我们让模型学习不同大小区域的表示层次结构,时间轴单元的地理位置(道路或站点的精确位置)在模型中表示为其在不同尺度上的位置嵌入的总和。我们首先对具有特殊情况的细粒度位置使用逐渐增加的惩罚来训练模型,并将结果用于特征选择。这确保了在足够复杂的区域中考虑细粒度特征,这些区域一百米的距离会影响公交车的行为,而不是在开阔的乡村,在这些乡村中,这种细粒度特征很少重要。
在训练时,我们还模拟了以后查询训练数据中没有的区域的可能性。在每个训练批次中,我们随机选取一些示例,并丢弃低于为每个示例随机选择的尺度的地理特征。一些示例保留了确切的公交路线和街道,其他示例仅保留了社区或城市级别的位置,而其他示例则根本没有地理背景。这更好地为模型做好了以后查询我们缺少训练数据的区域的准备。我们使用来自 Google 地图用于企业热门时间、停车难度和其他特征的同一数据集的关于用户公交行程的匿名推断来扩大训练语料库的覆盖范围。但即使是这些数据也不包括世界上大多数公交线路,因此我们的模型必须能够稳健地推广到新领域。
学习当地节奏
不同的城市和街区也有不同的节奏,因此我们允许模型将其位置表示与时间信号相结合。公交车对时间有着复杂的依赖性——周二晚上 6:30 和 6:45 之间的差异可能是某些街区的交通高峰期结束时间,其他街区的用餐高峰时间,以及其他地方沉睡小镇的完全安静时间。我们的模型学习当地时间和星期几信号的嵌入,当与位置表示相结合时,可以捕捉到汽车交通无法观察到的显着的局部变化,例如交通高峰时段公交车站的人群。
这种嵌入将 4 维向量分配给一天中的时间。与大多数神经网络内部结构不同,四个维度几乎不足以进行可视化,因此让我们通过下面的艺术渲染来了解模型如何在其中三个维度中安排一天的时间。该模型确实了解到时间是循环的,将时间置于“循环”中。但这个循环不仅仅是钟面的平面圆圈。该模型学习宽弯曲,让其他神经元组成简单的规则,轻松区分“半夜”或“上午晚些时候”等没有太多公交车行为变化的概念。另一方面,晚间通勤模式在社区和城市之间差异更大,并且该模型似乎在下午 4 点至晚上 9 点之间创建了更复杂的“皱褶”模式,从而可以更复杂地推断每个城市高峰时段的时间。

该模型的时间表示(4 个维度中的 3 个维度)形成一个循环,在此重新想象为手表的周长。位置相关的时间窗口(例如下午 4 点至晚上 9 点和早上 7 点至早上 9 点)会得到更复杂的“褶皱”,而像凌晨 2 点至凌晨 5 点这样没有特征的大窗口会弯曲成平弯,以符合更简单的规则。(艺术家 Will Cassella 的构想,使用了来自 Textures.com 的纹理和来自 hdrihaven 的 HDRI。)
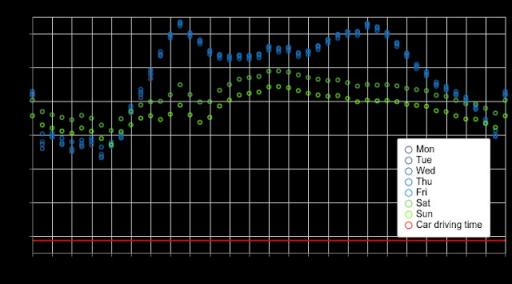
结合其他信号,这种时间表示法让我们能够预测复杂的模式,即使我们保持汽车速度不变。例如,在新泽西州 10 公里的公交车行程中,我们的模型可以捕捉到午餐时间的人群和工作日的交通高峰时间:
所有内容整合在一起
在模型经过全面训练后,让我们看看它对上述悉尼公交车行程的了解。如果我们在当天的汽车交通数据上运行该模型,它会给出下面的绿色预测。它并没有捕捉到所有内容。例如,它在 800 米处仅停留了 10 秒,尽管公交车至少停了 31 秒。但我们在 1.5 分钟内就能捕捉到公交车实际运动的细微差别,这比仅凭时间表或汽车行驶时间所能捕捉到的要多得多。
未来旅程
目前我们的模型中没有的一件事是什么?公交车时刻表本身。到目前为止,在对官方机构公交车时刻表的实验中,它们并没有显著改善我们的预测。在某些城市,严重的交通波动可能会压倒计划时刻表的尝试。在其他城市,公交车时刻表可能很精确,但这可能是因为交通机构仔细考虑了交通模式。我们从数据中推断出这些。
我们继续尝试更好地利用时刻表约束和许多其他信号来推动更精确的预测,并使我们的用户更容易计划他们的行程。我们希望我们也能在您的旅途中有所帮助。旅途愉快!
致谢
这项工作是 Google Research 的 James Cook、Alex Fabrikant、Ivan Kuznetsov 和 Fangzhou Xu 以及 Google 地图的 Anthony Bertuca、Julian Gibbons、Thierry Le Boulengé、Cayden Meyer、Anatoli Plotnikov 和 Ivan Volosyuk 共同努力的结果。我们感谢 Senaka Buthpitiya、Da-Cheng Juan、Reuben Kan、Ramesh Nagarajan、Andrew Tomkins 和 Transit 团队的支持和有益的讨论;以及 Will Cassella 对模型时间嵌入的启发性重新构想。我们还感谢我们的合作机构提供系统训练所需的交通数据。
评论