能够识别“谁说了什么”或进行说话人分类是通过自动化手段理解人类对话音频的关键步骤。例如,在医生和患者之间的医疗对话中,患者在回答“您一直在定期服用心脏病药物吗? ”时说的“是”与医生的修辞“是? ”的含义有很大不同。 传统的说话人分类 (SD) 系统使用两个阶段,第一阶段检测声谱的变化以确定对话中的说话人何时发生变化,第二阶段识别对话中的各个说话人。这种基本的多阶段方法已有近二十年历史,在此期间只有说话人变化检测组件有所改进。随着新型神经网络模型——循环神经网络传感器(RNN-T)—— 的最新开发,我们现在有了合适的架构来提高说话人分类的性能,解决了我们最近提出的上一个分类系统的一些局限性。正如我们最近的论文“通过序列转导实现联合语音识别和说话人分类”中所述,该论文将在Interspeech 2019上发表,我们开发了一种基于 RNN-T 的说话人分类系统,并已证明性能有所突破,将单词分类错误率从约 20% 降低到 2%——提高了 10 倍。传统的说话人分类系统 传统的说话人分类系统依靠人们在声学上的声音差异来区分对话中的说话人。虽然可以在单个阶段中使用简单的声学模型(例如高斯混合模型)根据音调相对容易地识别男性和女性说话人,但说话人分类系统使用多阶段方法来区分可能具有相似音调的说话人。首先,变化检测算法根据检测到的声音特征将对话分解为同质片段,希望只包含一个说话人。然后,使用深度学习模型将每个说话人的片段映射到嵌入向量。最后,在聚类阶段,这些嵌入被分组在一起,以跟踪对话中的同一个说话者。 实际上,说话者分类系统与自动语音识别 (ASR) 系统并行运行,并将两个系统的输出组合起来,为识别出的单词添加说话者标签。
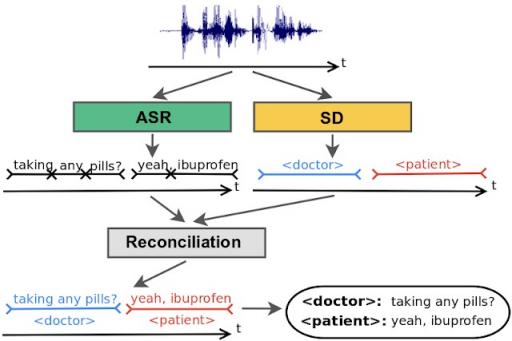
传统的说话人分类系统在声学域中推断说话人标签,然后将说话人标签叠加在单独的 ASR 系统生成的单词上。
这种方法存在一些限制,阻碍了该领域的发展。首先,对话需要分解成仅包含一个说话者的语音的片段。否则,嵌入将无法准确表示说话者。然而,在实践中,变化检测算法并不完善,导致片段可能包含多个说话者。其次,聚类阶段要求知道说话者的数量,并且对该输入的准确性特别敏感。第三,系统需要在估计语音特征的片段大小和所需的模型精度之间做出非常困难的权衡。片段越长,语音特征的质量越好,因为模型包含更多关于说话者的信息。这会带来将短促的感叹词归因于错误说话者的风险,这可能会产生非常严重的后果,例如,在处理需要准确跟踪肯定或否定的临床或财务对话的情况下。最后,传统的说话者分类系统没有一种简单的机制来利用在许多自然对话中特别突出的语言线索。在临床对话中,“您多久吃一次药? ”这样的话语很可能是医务人员说的,而不是患者。同样,“我们应该什么时候交作业? ”这句话很可能是学生说的,而不是老师。语言线索也表明说话人轮流改变的可能性很高,例如,在提问之后。
传统的说话人日志系统有一些例外,我们在最近的博客文章中报道了一种例外。在那项工作中,循环神经网络 (RNN) 的隐藏状态跟踪说话人,从而绕过了聚类阶段的弱点。这篇文章中报道的工作采用了不同的方法,也结合了语言线索。
集成的语音识别和说话人日志系统
我们开发了一个新颖而简单的模型,它不仅可以无缝地结合声学和语言线索,而且还将说话人日志和语音识别结合到一个系统中。与同等的仅识别系统相比,集成模型不会显著降低语音识别性能。
我们工作中的关键见解是认识到 RNN-T 架构非常适合整合声学和语言线索。RNN-T 模型由三个不同的网络组成:(1) 转录网络(或编码器) 将声学帧映射到潜在表示,(2) 预测网络,根据先前的目标标签预测下一个目标标签,以及 (3) 联合网络,结合前两个网络的输出并生成该时间步骤上输出标签集的概率分布。请注意,架构中有一个反馈回路(下图),其中先前识别的单词被反馈为输入,这使得 RNN-T 模型能够结合语言线索,例如问题的结尾。
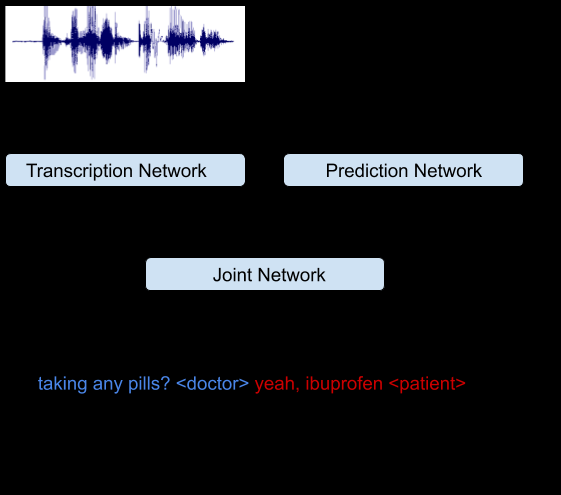
集成的语音识别和说话人分类系统,该系统可以联合推断谁在何时说了什么。
在图形处理单元 (GPU) 或张量处理单元 (TPU) 等加速器上训练 RNN-T 模型并非易事,因为计算损失函数需要运行前向-后向算法,该算法包括输入和输出序列的所有可能对齐。这个问题最近在TPU 友好的前向-后向算法实现中得到了解决,该算法将问题重新定义为一系列矩阵乘法。我们还利用了TensorFlow 中RNN-T 损失的高效实现,该实现允许快速迭代模型开发并训练非常深的网络。
集成模型可以像语音识别系统一样进行训练。训练的参考记录包含说话者所说的单词,后跟定义说话者角色的标签。例如,“什么时候交作业? ”≺学生≻,“我希望你明天上课前交作业”,≺老师≻。使用音频示例和相应的参考记录训练模型后,用户可以输入对话录音,并期望看到类似形式的输出。我们的分析表明,RNN-T 系统的改进会影响所有类别的错误,包括说话人轮换时间短、词边界处分词、重叠语音情况下说话人分配错误以及音频质量差。此外,与传统系统相比,RNN-T 系统在整个对话中表现出一致的性能,每次对话的平均错误率差异明显较低。
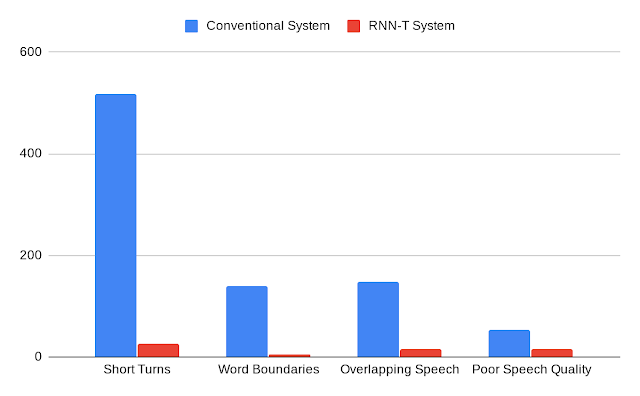
传统系统与 RNN-T 系统所犯错误的比较,由人工注释者分类。
此外,该集成模型可以预测生成更易于阅读的 ASR 转录本所需的其他标签。例如,我们能够使用适当匹配的训练数据成功改进带有标点符号和大写字母的转录本。我们的输出标点符号和大写字母错误比我们之前的模型要少,这些模型是单独训练并在 ASR 之后作为后处理步骤添加的。
该模型现在已成为我们理解医疗对话项目的标准组件,并且也在我们的非医疗语音服务中得到更广泛的采用。
致谢
我们要感谢 Hagen Soltau,如果没有他的贡献,这项工作就不可能完成。这项工作是与 Google Brain 和 Speech 团队合作完成的。
评论