自动生成的语音随处可见,从开车时大声朗读的方向,到手机上的虚拟助手或家中的智能扬声器设备。虽然人们正在做大量研究,试图让合成语音听起来尽可能自然——例如为资源匮乏的语言生成语音,以及使用 Tacotron 2 创建类似人类的语音——但如何评估生成的语音呢?最好的方法是询问那些非常擅长判断某句话听起来是否自然的人。
在语音合成领域,受试者通常会被要求聆听合成语音样本并对其质量进行评分。然而,到目前为止,对合成语音的评估都是逐句进行的。但人们通常想知道一系列句子的质量,例如新闻文章中的段落或对话中的转折。这就是事情变得有趣的地方,因为评估自然出现在序列中的句子的方法不止一种,而且令人惊讶的是,还没有对这些不同的方法进行严格的比较。这反过来会阻碍依赖生成语音的产品的开发研究进展。
为了应对这一挑战,我们提出了“评估长格式文本转语音:比较句子和段落的评分”,这是一份将在SSW10上发表的出版物,其中我们比较了评估多行文本合成语音的几种方法。我们发现,当将一个句子作为涉及多个句子的长文本的一部分进行评估时,结果会受到向评估它的人呈现音频样本的方式的影响。例如,当句子单独呈现时,没有任何上下文,人们给出的平均评分与他们听同一句话时带有某些上下文时给出的评分有很大不同(而上下文不必评分)。
评估自动生成的语音
为了确定语音信号的质量,通常的做法是请几位人类评估者对特定样本给出意见,按 1 到 5 的等级进行评分。此样本可以自动生成,但也可以是自然语音(即真人大声说出一句话),作为对照。所有评论者对特定语音样本的评分被平均,以获得平均意见分数 (MOS)。
到目前为止,MOS 评分通常都是按句子收集的,即评分者单独听取句子以形成意见。与这种典型方法不同,我们考虑了三种向评分者呈现语音样本的不同方式(带有和不带有上下文),并且我们表明每种方法都会产生不同的结果。第一种方法,即单独呈现句子,是该领域常用的默认方法。另一种方法是提供句子的完整上下文。在这种情况下,将包括该句子所属的整个段落并对该整体进行评分。最后一种方法是提供上下文-刺激对。在这里,不是提供完整上下文,而是仅提供一些上下文,例如原始段落中的前面句子。有趣的是,即使应用于自然语音
,这三种不同的语音呈现方法也会产生不同的结果。下图演示了这一点,其中显示了使用三种不同呈现方法评分的自然语音样本的 MOS 分数。尽管在三种不同环境下评分的句子是相同的,但平均分数是不同的,这取决于句子呈现的上下文。
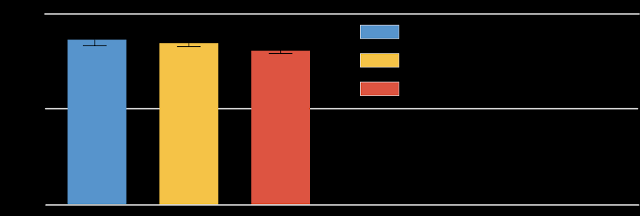
MOS 结果来自新闻文章数据集的自然语音。虽然差异看起来很小,但在所有条件下差异都很显著(双尾t 检验,α=0.05)。
检查上图可发现,评分者很少给出最高分(五分),即使是录制的人类语音也是如此,这可能令人惊讶。然而,这是句子评估研究中看到的典型结果,可能与一种更普遍的行为模式有关,即人们倾向于避免使用量表的极端值,无论任务或设置如何。
当评估合成语音时,差异更加明显。
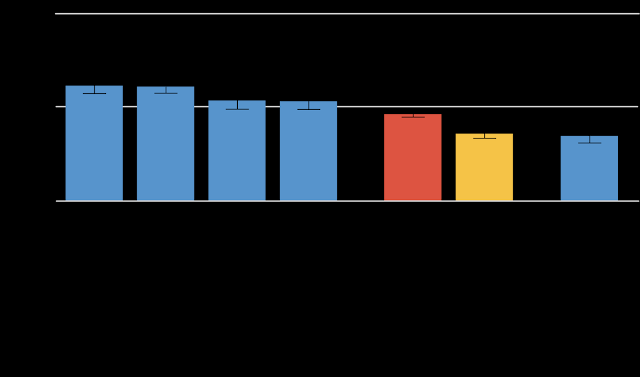
MOS 合成语音结果与上文所用新闻文章数据集相同。除非另有说明,否则所有句子均为合成语音。
为了查看上下文呈现方式是否会产生影响,我们尝试了几种不同的呈现方式:在要评估的句子之前提供一两句话,以生成的语音或真实语音的形式提供。添加上下文后,分数会更高(左侧的四个蓝色条),除非呈现的上下文是真实语音,在这种情况下分数会下降(最右边的蓝色条)。我们的假设是,这与锚定效应有关——如果上下文非常好(真实语音),相比之下,合成语音会被认为不那么自然。
预测段落分数
当播放整段合成语音(黄色条)时,这比其他设置更不自然。我们最初的假设是最弱链接论证——评分可能与段落中最差的句子一样糟糕。如果是这样的话,应该很容易通过考虑段落中各个句子的评分来预测段落的评分,也许只需取最小值即可获得段落评分。但事实证明,这并不奏效。
最弱环节假设的失败可能是由于更微妙的因素,这些因素很难用这种简单的方法梳理出来。为了测试这一点,我们还训练了一种机器学习算法来根据单个句子预测段落得分。然而,这种方法也无法成功可靠地预测段落得分。
结论
当涉及多个句子时,评估合成语音并不是一件简单的事情。传统的单独评价句子的范式并不能提供全貌,在提供上下文时,人们应该注意锚定效应。评价整个段落可能是最保守的方法。我们希望我们的研究结果有助于推动未来涉及长篇内容的语音合成工作,例如有声读物阅读器和对话代理。
致谢
非常感谢本文的所有作者:Rob Clark、Hanna Silen、Ralph Leith。
评论