生成式人工智能革命正在创造奇怪的伙伴,就像利用它们的革命和新兴垄断企业经常做的那样。
超级以太网联盟成立于 2023 年 7 月,旨在取代 Nvidia 的 InfiniBand 高性能互连,后者已迅速成为连接 GPU 加速节点的事实标准,并且获得了丰厚的利润。现在,由许多相同公司组成的超级加速器链接联盟正在组建中,旨在取代 Nvidia 的 NVLink 协议和 NVLink Switch(有时称为 NVSwitch)内存结构,用于将 GPU 连接到服务器节点内部和 pod 中多个节点的共享内存群集中。
毫无疑问,英伟达以 69 亿美元收购 Mellanox Technologies 的交易是英伟达的分水岭事件。该交易于 2019 年 3 月宣布,并于 2020 年 4 月完成。自 Mellanox 被纳入英伟达旗下以来,英伟达已收回了投资成本的三倍左右。
Nvidia 的网络业务主要由 Quantum InfiniBand 交换机销售推动,偶尔也会向少数超大规模企业和云构建商大量销售 Spectrum 以太网交换机产品。以太网业务和 InfiniBand 经验让 Nvidia 有能力构建更好的以太网,其第一代产品名为 Spectrum X,旨在对抗超级以太网联盟的努力,该联盟旨在构建低延迟、无损的以太网变体,该变体兼具 InfiniBand 拥塞控制和动态路由的所有优点(以独特方式实现),同时具备以太网更广泛、更扁平的规模,其既定目标是最终在单个集群中支持超过 100 万个计算引擎端点,具有少量网络级别和可观的性能。
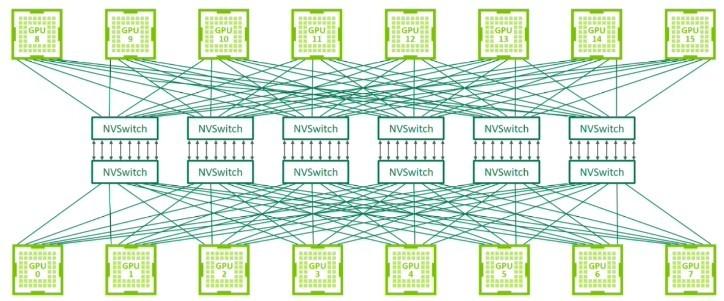
NVLink 最初是一种将 Nvidia GPU 卡上的内存组合在一起的方法,最终 Nvidia Research 实现了一个交换机来驱动这些端口,允许 Nvidia 以杠铃拓扑连接两个以上的 GPU,或以十字交叉方形拓扑连接四个 GPU,这种拓扑几十年来通常用于创建基于 CPU 的双插槽和四插槽服务器。几年前,AI 系统需要八个或十六个 GPU 共享内存,以简化编程,并使这些 GPU 能够以内存速度(而不是网络速度)访问数据集。因此,实验室中的 NVSwitch 于 2018 年在基于“Volta”V100 GPU 加速器的 DGX-2 平台上迅速商业化。
早在 2023 年 3 月,也就是“Hopper”H100 GPU 发布一年后,以及 DGX H100 SuperPOD 系统首次亮相时,我们就详细讨论了NVLink 和 NVSwitch 的历史,理论上,该系统可以在单个 GPU 共享内存占用空间中扩展到 256 个 GPU。可以说,NVLink 及其 NVLink Switch 结构对 Nvidia 的数据中心业务来说,已经变得和 InfiniBand 一样具有战略意义,以太网也有可能成为这样。许多支持超级以太网联盟 (Ultra Ethernet Consortium) 的公司都同意为以太网提供一套通用的增强功能来对抗 InfiniBand,现在他们联合起来组建超级加速器链接 (UALink) 联盟,以对抗 NVLink 和 NVSwitch,并提供更开放的共享内存加速器互连,该互连受多种技术支持,并可从多个供应商处获得。
Ultra Accelerator Link 联盟的核心于去年 12 月建立,当时 CPU 和 GPU 制造商 AMD 和 PCI-Express 交换机制造商博通表示,博通未来的 PCI-Express 交换机将支持 xGMI 和 Infinity Fabric 协议,用于将其 Instinct GPU 内存相互连接,以及使用 CPU NUMA 链接的加载/存储内存语义将其内存连接到 CPU 主机的内存。我们听说这将是未来的“Atlas 4”交换机,它遵循 PCI-Express 7.0 规范,将于 2025 年上市。博通数据中心解决方案集团副总裁兼总经理 Jas Tremblay 证实,这项工作仍在进行中,但不要妄下结论。不要以为 PCI-Express 是唯一的 UALink 传输,也不要以为 xGMI 是唯一的协议。
AMD 为 UALink 计划贡献了范围更广的 Infinity Fabric 共享内存协议以及功能更有限且特定于 GPU 的 xGMI,而所有其他参与者都同意使用 Infinity Fabric 作为加速器互连的标准协议。英特尔高级副总裁兼网络和边缘事业部总经理 Sachin Katti 表示,由 AMD、博通、思科系统、谷歌、惠普企业、英特尔、Meta Platforms 和微软组成的 Ultra Accelerator Link“推动者小组”正在考虑使用以太网第 1 层传输层,并在其上采用 Infinity Fabric,以便将 GPU 内存粘合到类似于 CPU 上的 NUMA 的巨大共享空间中。
以下是创建 UALink GPU 和加速器舱的概念:

以下是如何使用以太网将 Pod 链接到更大的集群:

没人期望将来自多个供应商的 GPU 连接到一个机箱内,甚至可能是一个机架或多个机架中的一个舱内。但 UALink 联盟成员确实相信,系统制造商将创建使用 UALink 的机器,并允许在客户构建其舱时将来自许多参与者的加速器放入这些机器中。您可以有一个带有 AMD GPU 的舱,一个带有 Intel GPU 的舱,另一个带有来自任意数量的其他参与者的自定义加速器舱。它允许在互连级别实现服务器设计的通用性,就像 Meta Platforms 和 Microsoft 发布的开放加速器模块 (OAM) 规范允许系统板上加速器插槽的通用性一样。
你为何而来 CXL?
我们知道您在想什么:我们不是已经承诺过在 PCI-Express 结构上运行的 Compute Express Link (CXL) 协议将提供同样的功能吗?CXLmem 子集不是已经提供了 CPU 和 GPU 之间的内存共享吗?是的,确实如此。但 PCI-Express 和 CXL 是更广泛的传输和协议。Katti 表示,AI 加速器模块的内存域比 CPU 集群的内存域大得多,我们知道 CPU 集群的扩展范围从 2 个到 4 个,有时到 8 个,很少到 16 个计算引擎。许多人认为,AI 加速器的 GPU 模块可扩展到数百个计算引擎,并且需要扩展到数千个。Katti 告诉 The Next Platform,与 CPU NUMA 集群不同,GPU 集群(尤其是运行 AI 工作负载的集群)对内存延迟的容忍度更高。
因此,不要指望看到 UALinks 将 CPU 捆绑在一起,但没有理由相信未来的 CXL 链接最终不会成为 CPU 共享内存的标准方式——甚至可能跨越不同的架构。(奇怪的事情已经发生过。)
这实际上是为了打破 NVLink 在互连结构内存语义方面的垄断。无论 Nvidia 如何使用 NVLink 和 NVSwitch,它的几家竞争对手都需要为潜在客户提供可靠的替代方案——无论他们是销售 GPU 还是其他类型的加速器或整个系统——这些潜在客户肯定希望为 AI 服务器节点和机架式设备提供比 Nvidia 互连更开放、更便宜的替代方案。
“当我们审视整个数据中心对 AI 系统的需求时,有一点非常明显,那就是 AI 模型继续大规模增长,”AMD 数据中心解决方案事业部总经理 Forrest Norrod 说道。“每个人都可以看到,这意味着对于最先进的模型,许多加速器需要协同工作以进行推理或训练。能够扩展这些加速器对于推动未来大规模系统的效率、性能和经济性至关重要。扩展有几个不同的方面,但 Ultra Accelerator Link 的所有支持者都非常强烈地感受到,行业需要一个可以快速推进的开放标准,一个允许多家公司为整个生态系统增加价值的开放标准。并且允许创新不受任何一家公司的束缚而快速进行。”
那就是你,Nvidia。但值得赞扬的是,你投资了 InfiniBand,并创建了具有绝对超大网络带宽的 NVSwitch 来为 GPU 进行 NUMA 集群。这样做是因为 PCI-Express 交换机在总带宽方面仍然有限。
有趣的是,UALink 1.0 规范将在今年第三季度完成,届时 Ultra Accelerator Consortium 也将加入进来,拥有知识产权并推动 UALink 标准的发展。UALink 1.0 规范将提供一种将多达 1,024 个加速器连接到共享内存 pod 的方法。今年第四季度,UALink 1.1 更新将发布,这将进一步提高规模和性能。目前尚不清楚 1.0 和 1.1 UALink 规范将支持哪些传输,或者哪些将支持 PCI-Express 或以太网传输。
使用 NVLink 4 端口的 NVSwitch 3 结构理论上可以在共享内存 pod 中跨越多达 256 个 GPU,但 Nvidia 的商业产品仅支持 8 个 GPU。借助 NVSwitch 4 和 NVLink 5 端口,Nvidia 理论上可以支持跨越多达 576 个 GPU 的 pod,但实际上,商业支持仅在 DGX B200 NVL72 系统中最多 72 个 GPU 的机器上提供。
本站全部资讯来源于实验室原创、合作机构投稿及网友汇集投稿,仅代表个人观点,不作为任何依据,转载联系作者并注明出处:https://www.lvsky.net/399.html
评论