在 Google,我们正在积极探索人们如何在制作多媒体内容时使用由机器学习和计算方法提供支持的创造力工具,包括创作音乐、重新构图视频、绘图等等。视频制作这一创造性过程尤其可以从此类工具中受益,因为它需要做出一系列决策,包括哪些内容最适合目标受众、如何在视野内定位可用资产,以及什么样的时间安排将产生最引人注目的故事。但如果可以利用现有资产(例如网站)来快速开始视频创作,那会怎样?企业通常拥有包含有关其服务或产品的丰富视觉表现的网站,所有这些网站都可以重新用于其他多媒体格式(例如视频),从而使那些没有大量资源的人能够接触到更广泛的受众。
在UIST 2020上发表的 “从网页自动创建视频”中,我们介绍了 URL2Video,这是一种研究原型流程,可在内容所有者提供的时间和视觉约束下自动将网页转换为短视频。URL2Video 从 HTML 源中提取资产(文本、图像或视频)及其设计样式(包括字体、颜色、图形布局和层次结构),并将视觉资产组织成一系列镜头,同时保持与源页面相似的外观和感觉。给定用户指定的宽高比和持续时间,它会将重新利用的材料渲染成非常适合产品和服务广告的视频。
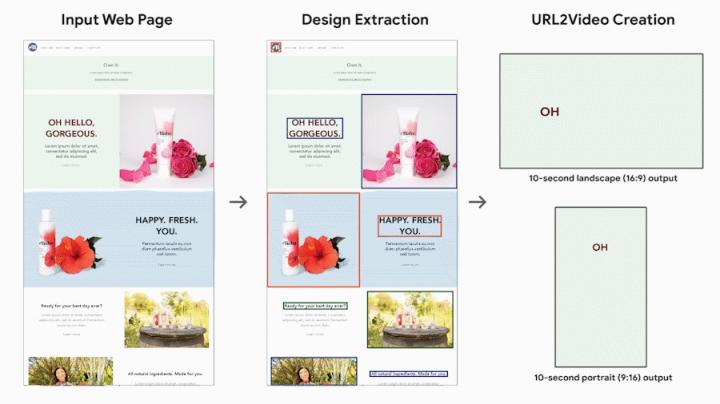
URL2Video 概述
假设用户提供一个指向说明其业务的网页的 URL。URL2Video 管道会根据从对熟悉网页设计和视频广告制作的设计师的访谈研究中得出的一组启发式方法,自动从页面中选择关键内容并决定每项资产的时间和视觉呈现方式。这些由设计师启发式方法捕捉了常见的视频编辑风格,包括内容层次结构、限制镜头中的信息量及其时间长度、为品牌提供一致的颜色和风格等等。使用这些信息,URL2Video 管道会解析网页,分析内容并选择视觉上突出的文本或图像,同时保留它们的设计风格,并根据用户提供的视频规格进行组织。

通过从输入网页中提取结构化内容和设计,URL2Video 会自动做出编辑决策,以在视频中呈现关键信息。它会考虑用户定义的输出视频的时间(例如,以秒为单位的持续时间)和空间(例如,宽高比)约束。
网页分析
给定一个网页 URL,URL2Video 会提取文档对象模型(DOM) 信息和多媒体材料。为了研究原型,我们将域限制为静态网页,其中包含显着资产和标题,这些资产和标题保存在遵循最新网页设计原则的 HTML 层次结构中,这些原则鼓励使用突出的元素、不同的部分和引导读者感知信息的视觉焦点顺序。URL2Video 将这些视觉上可区分的元素识别为资产组的候选列表,每个资产组可能包含标题、产品图像、详细描述和号召性用语按钮,并捕获原始资产(文本和多媒体文件)和每个元素的详细设计规范(HTML 标签、CSS 样式和渲染位置)。然后,它根据资产组的视觉外观和注释(包括其 HTML 标签、渲染大小和页面上显示的顺序)为每个资产组分配优先级分数,从而对资产组进行排名。这样,占据页面顶部较大区域的资产组将获得更高的分数。
基于约束的资产选择
在制作视频时,我们考虑两个目标:(1)每个视频镜头都应提供简明的信息,(2)视觉设计应与源页面一致。 根据这些目标和用户提供的视频约束,包括预期的视频时长(以秒为单位)和宽高比(通常为 16:9、4:3、1:1 等),URL2Video 会自动选择和排序资产组以优化总体优先级得分。 为了使内容简洁,它只呈现页面中的主导元素,例如标题和一些多媒体资产。 它限制每个视觉元素的持续时间,以便观看者感知内容。 通过这种方式,短视频会从页面顶部突出显示最突出的信息,而长视频则包含更多的活动或产品。
场景合成和视频渲染
根据 DOM 层次结构给出有序的资产列表,URL2Video 遵循从访谈研究中获得的设计启发法,决定在单个镜头中呈现资产的时间和空间安排。它将元素的图形布局转换为视频的宽高比,并应用字体和颜色等样式选择。为了使视频更具动感和吸引力,它会调整资产的呈现时间。最后,它将内容渲染为 MPEG-4 容器格式的视频。
用户控制
研究原型的界面允许用户查看从源页面提取的每个视频镜头的设计属性,重新排序材料,更改颜色和字体等详细设计,并调整约束以生成新视频。
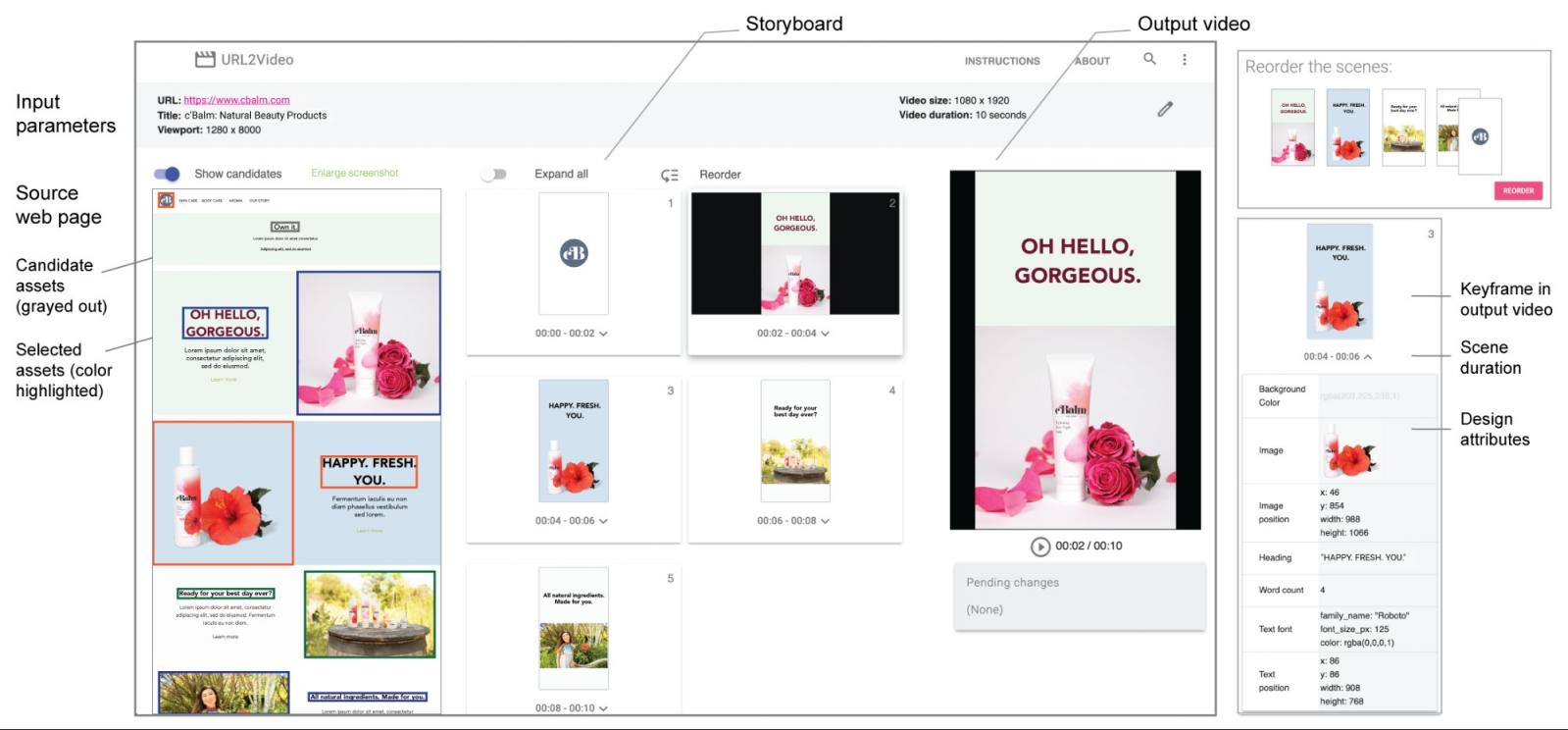
在 URL2Video 的创作界面(左)中,用户指定源页面的输入 URL、目标页面视图的大小以及输出视频参数。URL2Video 分析网页并提取主要的视觉组件。它组成一系列场景,并将关键帧可视化为故事板。这些组件被渲染成满足输入时间和空间约束的输出视频。用户可以播放视频、检查设计属性(右下),并进行调整以生成视频变化,例如重新排序场景(右上)。
URL2Video 用例
我们在各种现有网页上演示了端到端 URL2Video 管道的性能。下面我们重点介绍一个示例结果,其中 URL2Video 将嵌入多个短视频片段的页面转换为 12 秒的输出视频。请注意管道如何对从源页面捕获的视频中的字体和颜色选择、时间和内容排序做出自动编辑决策。

URL2Video 从我们的Google 搜索介绍页面(顶部)中识别关键内容,包括标题和视频资产。它通过考虑演示流程、源设计和输出约束将它们转换为视频(12 秒横向视频;底部)。
下一步
虽然当前的研究重点是视觉呈现,但我们正在开发支持视频编辑中的音轨和画外音的新技术。总而言之,我们设想的未来是,创作者专注于做出高层决策,而 ML 模型会以交互方式为最终在多个平台上创作的视频提供详细的时间和图形编辑建议。
致谢
我们非常感谢我们的论文合著者,Zheng Sun(研究)和 Katrina Panovich(YouTube)。我们还要感谢为 URL2Video 做出贡献的同事(按姓氏字母顺序排列)Jordan Canedy、Brian Curless、Nathan Frey、Madison Le、Alireza Mahdian、Justin Parra、Emily Ryan、Mogan Shieh、Sandor Szego 和 Weilong Yang。我们非常感谢我们的领导 Tomas Izo、Rahul Sukthankar 和 Jay Yagnik 的支持。
评论