机器学习 (ML) 在实际应用中的应用越来越广泛,因此了解模型的不确定性和稳健性对于确保实际性能至关重要。例如,当模型部署在与训练数据不同的数据上时,它会如何表现?模型如何发出可能出错的信号?
为了掌握 ML 模型的行为,通常需要根据感兴趣任务的基线来衡量其性能。对于每个基线,研究人员必须尝试仅使用相应论文中的描述来重现结果,这给复制带来了严峻挑战。假设实验代码有详尽的文档记录和维护,那么访问实验代码可能会更有用。但即使这样还不够,因为必须严格验证基线。例如,在对一系列作品 [ 1、2、3 ] 进行回顾性分析时,作者经常发现简单且经过良好调整的基线表现优于更复杂的方法。为了真正了解模型相对于彼此的表现,并让研究人员能够衡量新想法是否确实产生了有意义的进展,必须将感兴趣的模型与共同基线进行比较。
在“不确定性基线:深度学习中不确定性和鲁棒性的基准”中,我们介绍了不确定性基线,这是一系列针对各种任务的标准和最先进的深度学习方法的高质量实现,目的是使不确定性和鲁棒性研究更具可重复性。该集合涵盖 9 项任务的 19 种方法,每种方法至少有 5 个指标。每个基线都是一个独立的实验管道,具有易于重用和可扩展的组件,并且对其编写框架之外的依赖性极小。所包含的管道在TensorFlow、PyTorch和Jax中实现。此外,每个基线的超参数都经过了多次迭代的广泛调整,以提供更强的结果。
不确定性基线
截至撰写本文时,不确定性基线共提供了 83 条基线,包括 19 种方法,涵盖 9 个数据集的标准和较新的策略。示例方法包括BatchEnsemble、Deep Ensembles、Rank-1 Bayesian Neural Nets、Monte Carlo Dropout和Spectral-normalized Neural Gaussian Processes。它作为合并社区中几个流行基准的后继者:您可以信任模型的不确定性吗?、BDL 基准和Edward2 的基线。
数据集 输入 输出 训练示例 测试数据集
人工智能与计算实验室 RGB 图像 10 类分布 5万 3
图像网 RGB 图像 1000 级分布 1,281,167 6
CLINC 意图检测 对话系统查询文本 150 类分布(10 个领域) 15,000 2
Kaggle 的糖尿病视网膜病变检测 RGB 图像 糖尿病视网膜病变的概率 35,126 1
维基百科 毒性 维基百科评论文本 毒性概率 159,571 3
9 个可用数据集中的 5 个数据集的子集,为其提供了基线。数据集涵盖表格、文本和图像模式。
不确定性基线根据基础模型、训练数据集和一套评估指标的选择设置每个基线。然后根据超参数调整每个基线,以最大限度地提高这些指标的性能。可用的基线在以下三个轴之间有所不同:
基础模型(架构)包括Wide ResNet 28-10、ResNet-50、BERT和简单的全连接网络。
训练数据集包括标准机器学习数据集(CIFAR、ImageNet和UCI)以及更多现实问题(Clinc Intent Detection、Kaggle 的糖尿病视网膜病变检测和维基百科毒性)。
评估包括预测指标(例如准确性)、不确定性指标(例如选择性预测和校准误差)、计算指标(推理延迟)以及分布内和分布外数据集的性能。
模块化和可重用性
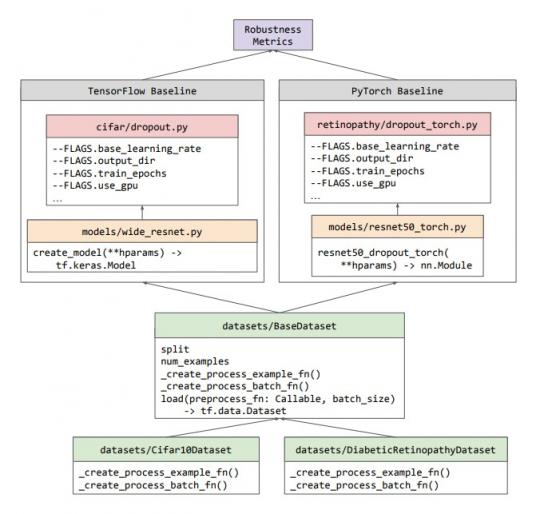
为了让研究人员能够使用和构建基线,我们特意对它们进行了优化,使其尽可能模块化和最小化。如下面的工作流程图所示,不确定性基线没有引入新的类抽象,而是重用生态系统中预先存在的类(例如 TensorFlow 的tf.data.Dataset)。每个基线的训练/评估管道都包含在该实验的独立 Python 文件中,该文件可以在 CPU、GPU 或 Google Cloud TPU 上运行。由于基线之间的这种独立性,我们能够在 TensorFlow、PyTorch或JAX中的任何一个中开发基线。
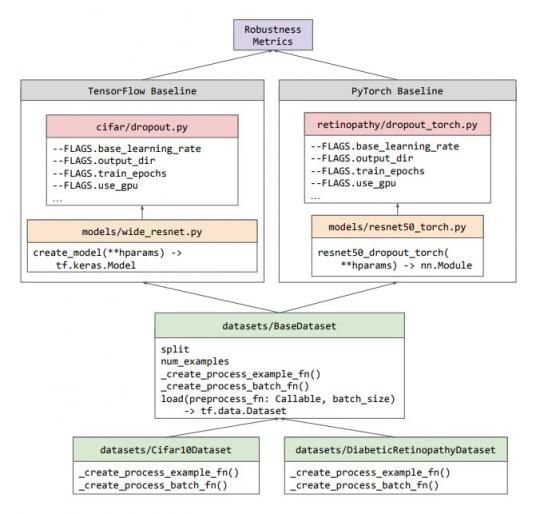
不确定性基线不同组件的结构工作流程图。所有数据集都是 BaseDataset 类的子类,该类提供了一个简单的 API,可用于使用任何受支持的框架编写的基线。然后可以使用稳健性指标库分析任何基线的输出。
研究工程师争论的焦点是如何管理超参数和其他实验配置值,这些值的数量很容易达到几十个。我们没有使用为此构建的众多框架之一,也不必冒着用户必须学习另一个库的风险,而是选择简单地使用 Python 标志,即使用Abseil定义的遵循 Python 约定的标志。这应该是大多数研究人员熟悉的技术,并且易于扩展和插入其他管道。
可重复性
除了能够使用记录的命令运行我们的每个基线并获得相同的报告结果之外,我们还旨在发布超参数调整结果和最终模型检查点,以实现进一步的可重复性。目前,我们只有糖尿病视网膜病变基线完全开源,但我们将在运行它们时继续上传更多结果。此外,我们还有一些基线示例,这些示例在硬件确定性方面完全可重复。
实际影响
我们存储库中包含的每个基线都经过了大量的超参数调整,我们希望研究人员可以轻松重复使用这一成果,而无需进行昂贵的重新训练或重新调整。此外,我们希望避免管道实现中的细微差异影响基线比较。
不确定性基线已用于众多研究项目。如果您是一名研究人员,并有其他方法或数据集想要贡献,请打开 GitHub 问题来开始讨论!
致谢
我们要感谢一些共同开发者、提供指导和/或帮助审阅这篇文章的人:Neil Band、Mark Collier、Josip Djolonga、Michael W. Dusenberry、Sebastian Farquhar、Angelos Filos、Marton Havasi、Rodolphe Jenatton、Ghassen Jerfel、Jeremiah Liu、Zelda Mariet、Jeremy Nixon、Shreyas Padhy、Jie Ren、Tim GJ Rudner、Yeming Wen、Florian Wenzel、Kevin Murphy、D. Sculley、Balaji Lakshminarayanan、Jasper Snoek 和 Yarin Gal。
评论