
情绪是社交互动的关键因素,影响着人们的行为方式和人际关系。语言尤其如此——我们只需几个词就能表达各种微妙而复杂的情绪。因此,研究界长期以来一直致力于让机器理解语境和情绪,这反过来又可以实现各种应用,包括富有同理心的聊天机器人、检测有害在线行为的模型以及改进的客户支持互动。
在过去十年中,NLP研究界已经提供了多个基于语言的情绪分类数据集。其中大多数是手动构建的,涵盖目标领域(新闻标题、电影字幕甚至童话故事),但往往规模相对较小,或仅关注1992 年提出的六种基本情绪(愤怒、惊讶、厌恶、喜悦、恐惧和悲伤) 。虽然这些情绪数据集使人们能够对情绪分类进行初步探索,但它们也凸显了需要大规模数据集来涵盖更广泛的情绪,以便促进未来潜在应用的更广泛范围。
在“ GoEmotions:细粒度情绪数据集”中,我们描述了GoEmotions,这是一个人工注释的数据集,包含从流行的英语子版块中提取的 58k 条Reddit评论,并标有27 种情绪类别。作为迄今为止最大的全注释英语细粒度情绪数据集,我们在设计 GoEmotions 分类法时同时考虑了心理学和数据适用性。与仅包含一种积极情绪(快乐)的基本六种情绪相比,我们的分类法包括 12 种积极情绪、11 种消极情绪、4 种模糊情绪类别和 1 种“中性情绪”,使其广泛适用于需要对情绪表达进行细微区分的对话理解任务。
我们将发布 GoEmotions 数据集以及详细的教程,该教程演示了使用 GoEmotions 训练神经模型架构(可在TensorFlow Model Garden上获得)并将其应用于根据对话文本建议表情符号的任务的过程。在GoEmotions 模型卡中,我们探讨了使用 GoEmotions 构建的模型的其他用途,以及使用数据的注意事项和限制。

这段文字同时表达了几种情感,包括兴奋、赞许和感激。

这段文字表达了一种解脱感,一种既传达积极情绪又传达消极情绪的复杂情感。

这段文字传达了悔恨,这是一种经常表达但无法通过简单的情感模型捕捉到的复杂情感。
构建数据集
我们的目标是构建一个大型数据集,专注于对话数据,其中情感是交流的关键组成部分。由于 Reddit 平台提供了大量公开可用的内容,包括直接的用户对用户对话,因此它是情感分析的宝贵资源。因此,我们使用 2005 年(Reddit 成立之初)至 2019 年 1 月的 Reddit 评论构建了 GoEmotions,这些评论来自至少有 10,000 条评论的子版块,不包括已删除的评论和非英语评论。
为了能够构建具有广泛代表性的情感模型,我们应用了数据管理措施,以确保数据集不会强化一般或特定于情感的语言偏见。这一点尤为重要,因为众所周知,Reddit倾向于年轻男性用户,这不能反映全球人口的多样性。该平台还引入了对有毒、攻击性语言的偏见。为了解决这些问题,我们使用预定义的术语来识别攻击性/成人和粗俗内容,以及身份和宗教,以识别有害评论,并使用它们进行数据过滤和屏蔽。我们还对数据进行了过滤,以减少亵渎、限制文本长度,并平衡所代表的情绪和情感。为了避免热门 subreddit 过度代表性,并确保评论也反映不太活跃的 subreddit,我们还在 subreddit 社区之间平衡了数据。
我们创建了一个分类法,旨在共同实现三个目标:(1) 最大程度地覆盖 Reddit 数据中表达的情绪;(2) 最大程度地覆盖情绪表达类型;(3) 限制情绪的总体数量及其重叠。这种分类法允许数据驱动的细粒度情绪理解,同时还可以解决某些情绪的潜在数据稀疏性问题。
建立分类法是一个定义和改进情绪标签类别的迭代过程。在数据标记阶段,我们总共考虑了 56 个情绪类别。从这个样本中,我们识别并删除了那些很少被评分者选择的情绪、由于与其他情绪相似而导致评分者间一致性较低或难以从文本中检测到的情绪。我们还添加了评分者经常建议且在数据中得到充分体现的情绪。最后,我们改进了情绪类别名称以最大限度地提高可解释性,从而提高了评分者间的一致性,94% 的样本中有至少两名评分者至少同意 1 个情绪标签。
已发布的 GoEmotions 数据集包括下面介绍的分类法,并通过最后一轮数据标记完全收集,其中分类法和评级标准都是预先定义和固定的。
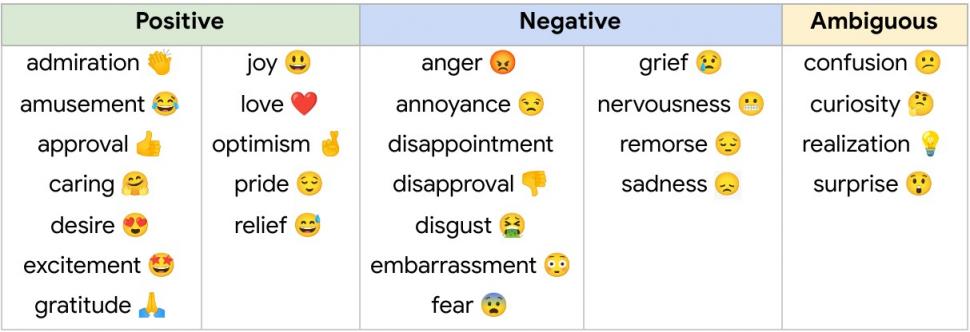
GoEmotions 分类:包括 28 种情绪类别,其中包括“中性”。
数据分析和结果
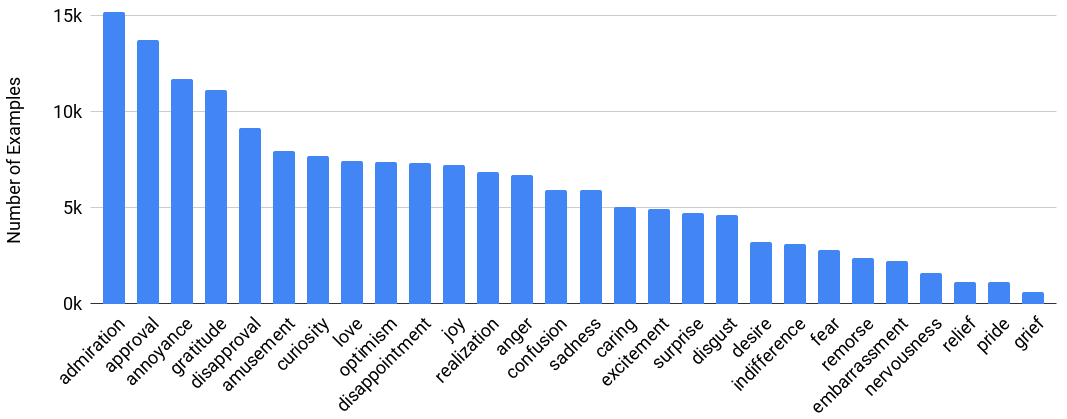
在 GoEmotions 数据集中,情绪分布并不均匀。重要的是,积极情绪的高频率强化了我们对比标准六种基本情绪提供的更多样化的情绪分类法的动机
为了验证我们的分类选择与基础数据相匹配,我们进行了主保留成分分析(PPCA),这是一种通过提取在两组评分者中表现出最高联合变异性的情绪判断的线性组合来比较两个数据集的方法。因此,它有助于我们发现在评分者之间具有高度一致性的情绪维度。PPCA 以前用于了解视频和语音中情绪识别的主要维度,我们在这里使用它来了解文本中情绪的主要维度。
我们发现每个成分都很重要(所有维度的 p 值均小于 1.5e-6),表明每种情绪都捕捉到了数据的独特部分。这并非易事,因为在之前的语音情绪识别研究中,我们发现 30 个情绪维度中只有 12 个维度很重要。
我们根据评分者判断之间的相关性来检查已定义情绪的聚类。通过这种方法,当评分者经常同时选择两种情绪时,它们会聚在一起。我们发现,尽管我们的分类法中没有预先定义的情绪概念,但情绪相关的情绪(消极、积极和模糊)会聚在一起,这表明评级的质量和一致性。例如,如果一位评分者选择“兴奋”作为给定评论的标签,那么另一位评分者更有可能选择相关情绪,例如“快乐”,而不是“恐惧”。也许令人惊讶的是,所有模糊情绪都聚在一起,并且它们与积极情绪的聚类更紧密。
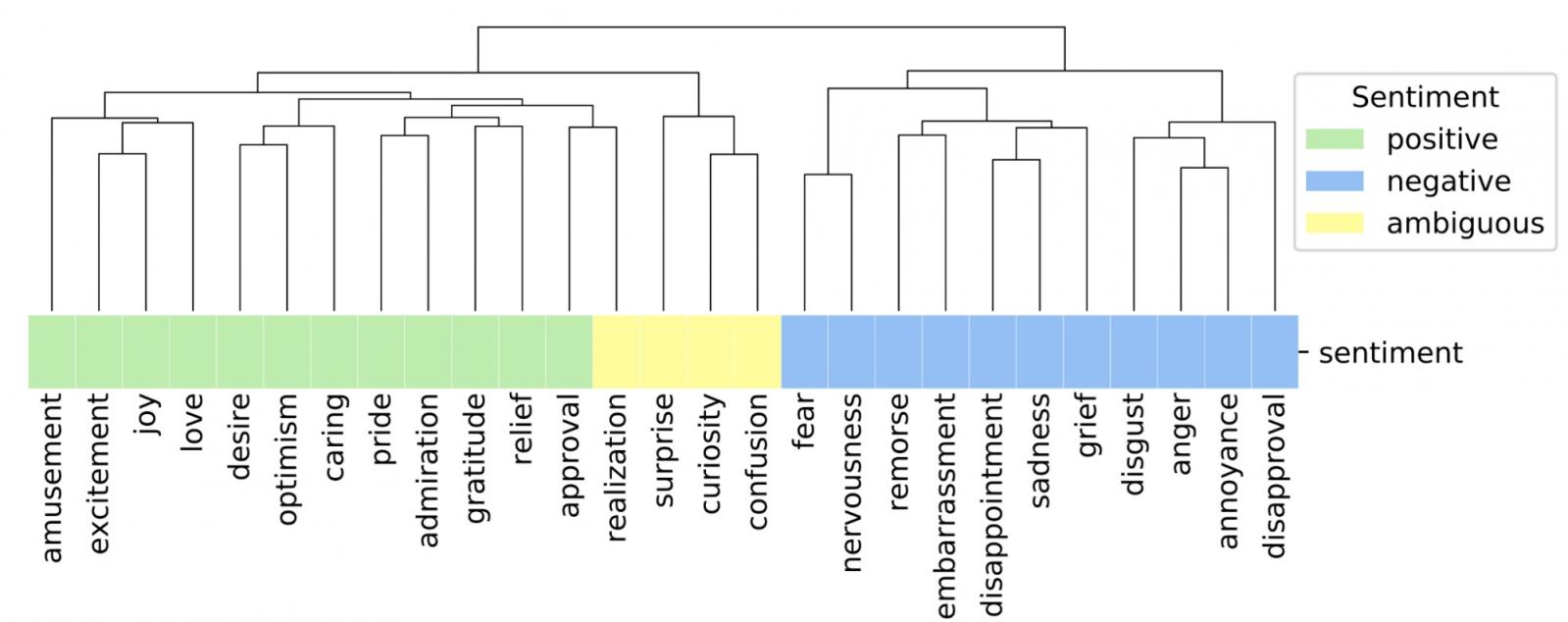
同样,强度相关的情绪,如喜悦和兴奋、紧张和恐惧、悲伤和悲痛、恼怒和愤怒,也密切相关。
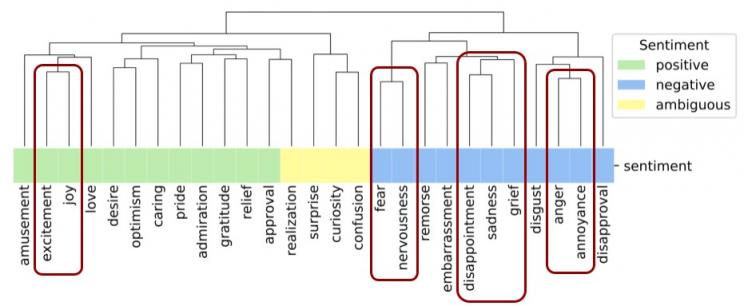
我们的论文使用 GoEmotions 提供了额外的分析和建模实验。
未来工作:人工标签的替代品
虽然 GoEmotions 提供了大量人工注释的情感数据,但还存在使用启发式方法自动进行弱标记的其他情感数据集。主要的启发式方法使用与情感相关的 Twitter 标签作为情感类别,这允许人们以低成本生成大型数据集。但这种方法有多种限制:Twitter 上使用的语言明显不同于许多其他语言领域,因此限制了数据的适用性;标签是人工生成的,直接使用时容易出现重复、重叠和其他分类不一致;这种方法对 Twitter 的特殊性限制了它在其他语言语料库中的应用。
我们提出了一种替代且更易于使用的启发式方法,其中嵌入在用户对话中的表情符号可作为情绪类别的代理。这种方法可以应用于任何包含合理表情符号的语言语料库,包括许多对话式表情符号。由于表情符号比 Twitter 标签更标准化且更不稀疏,因此它们出现的不一致现象更少。
请注意,我们提出的两种方法(使用 Twitter 标签和使用表情符号)并非直接针对情感理解,而是针对对话表达的变体。例如,在下面的对话中,🙏 表达感激之情,🎂 表达庆祝的表情,🎁 是“礼物”的字面替代。同样,虽然许多表情符号与情感相关的表情有关,但情感是微妙而多面的,在许多情况下,没有一个表情符号能够真正捕捉到情感的全部复杂性。此外,表情符号捕捉的不仅仅是情感,还有各种表情。出于这些原因,我们将它们视为表情而不是情感。
这种类型的数据对于构建富有表现力的对话代理以及建议上下文表情符号非常有价值,并且是未来研究的一个特别有趣的领域。
结论
GoEmotions 数据集提供了一个大型、手动注释的数据集,可用于细粒度的情绪预测。我们的分析证明了注释的可靠性和 Reddit 评论中表达的情绪的高覆盖率。我们希望 GoEmotions 将成为语言情绪研究人员的宝贵资源,并允许从业者构建创造性的情绪驱动应用程序,解决广泛的用户情绪。
致谢
本博客介绍了 Dora Demszky(在 Google 实习期间)、Dana Alon(之前为 Movshovitz-Attias)、Jeongwoo Ko、Alan Cowen、Gaurav Nemade 和 Sujith Ravi 所做的研究。我们感谢 Peter Young 对基础设施和开源的贡献。我们感谢 Erik Vee、Ravi Kumar、Andrew Tomkins、Patrick Mcgregor 和 Learn2Compress 团队对本研究项目的支持和赞助。
评论