将一种语言的语音自动翻译成另一种语言的语音,称为语音到语音翻译 (S2ST),对于打破不同语言的人之间的沟通障碍非常重要。传统上,自动 S2ST 系统由自动语音识别(ASR)、文本到文本机器翻译 (MT) 和文本到语音 (TTS) 合成子系统的级联构建而成,因此整个系统以文本为中心。最近,不依赖于中间文本表示的 S2ST 研究正在兴起,例如端到端直接 S2ST(例如,Translatotron)和基于学习的语音离散表示的级联 S2ST(例如,Tjandra 等人)。虽然此类直接 S2ST 系统的早期版本的翻译质量与级联 S2ST 模型相比较低,但它们正在获得关注,因为它们既有可能减少翻译延迟和复合错误,又可以更好地保留原始语音中的副语言和非语言信息,如声音、情感、语调等。然而,此类模型通常必须在具有成对 S2ST 数据的数据集上进行训练,但此类语料库的公开可用性极其有限。
为了促进对新一代 S2ST 的研究,我们引入了基于通用语音的语音转语音翻译语料库 ( CVSS),其中包括 21 种语言的句子级语音转语音翻译对。与现有的公共语料库不同,CVSS 可以直接用于训练此类直接 S2ST 模型,而无需任何额外处理。在“ CVSS 语料库和大规模多语言语音转语音翻译”中,我们描述了数据集的设计和开发,并通过训练基线直接和级联 S2ST 模型并展示接近级联 S2ST 模型的直接 S2ST 模型的性能来证明语料库的有效性。
构建 CVSS
CVSS 直接源自CoVoST 2语音转文本 (ST) 翻译语料库,而后者又源自Common Voice语音语料库。Common Voice 是专为 ASR 设计的海量多语言转录语音语料库,其中的语音由贡献者阅读 Wikipedia 和其他文本语料库中的文本内容收集而成。CoVoST 2 还为原始转录本提供专业的文本翻译,将原始转录本从 21 种语言翻译成英语,并将英语翻译成 15 种语言。CVSS 在这些努力的基础上,提供了从 21 种语言到英语的句子级并行语音转语音翻译对(如下表所示)。
为了方便不同重点的研究,CVSS 中提供了两个版本的英语翻译语音,均使用最先进的 TTS 系统合成,每个版本都提供了其他公共 S2ST 语料库中不存在的独特价值:
CVSS-C:所有翻译语音均采用单个标准说话者的声音。尽管是合成的,但语音非常自然、清晰,说话风格也一致。这些特性简化了目标语音的建模,并使经过训练的模型能够生成高质量的翻译语音,适用于一般面向用户的应用程序,在这些应用程序中,语音质量比准确再现说话者的声音更重要。
CVSS-T:翻译语音从相应的源语音中捕获声音。尽管语言不同,但每个 S2ST 对在两侧都有相似的声音。因此,该数据集适合用于构建需要精确保留声音的模型,例如电影配音。
加上源语音,两个 S2ST 数据集分别包含 1,872 和 1,937 小时的语音。
源
语言 代码 源
语音(X) CVSS-C
目标语音(En) CVSS-T
目标语音(En)
法语 法国 309.3 200.3 222.3
德语 德 226.5 137.0 151.2
加泰罗尼亚语 钙 174.8 112.1 120.9
西班牙语 西文 157.6 94.3 100.2
意大利语 它 73.9 46.5 49.2
波斯语 法 58.8 29.9 34.5
俄语 汝 38.7 26.9 27.4
中国人 中文 26.5 20.5 22.1
葡萄牙语 点 20.0 10.4 11.8
荷兰语 荷兰 11.2 7.3 7.7
爱沙尼亚语 等 9.0 7.3 7.1
蒙 锰 8.4 5.1 5.7
土耳其 tr 7.9 5.4 5.7
阿拉伯 应收账 5.8 2.7 3.1
拉脱维亚语 吕 4.9 2.6 3.1
瑞典 SV 4.3 2.3 2.8
威尔士语 赛 3.6 1.9 2.0
泰米尔语 塔 3.1 1.7 2.0
印度尼西亚 ID 3.0 1.6 1.7
日本人 贾 3.0 1.7 1.8
斯洛文尼亚语 斯洛文尼亚 2.9 1.6 1.9
全部的 1,153.2 719.1 784.2
CVSS 中每个 X-En 对的源语音和目标语音的数量(小时)。
除了翻译语音,CVSS 还提供与翻译语音中的发音相匹配的规范化翻译文本(关于数字、货币、首字母缩略词等,请参见下面的数据样本,例如,将“100%”规范化为“百分之一百”或将“乔治二世国王”规范化为“乔治二世国王”),这既有利于模型训练,也有利于标准化评估。
CVSS 根据知识共享署名 4.0 国际(CC BY 4.0)许可证 发布,可以在线免费下载。
数据样本
示例 1:
源音频(法语)
原文记录(法语) 香颂的音乐风格是迪斯科的全部。
CVSS-C 翻译音频(英语)
CVSS-T 翻译音频(英语)
翻译文本(英文) 这首歌的音乐风格是 100% 迪斯科。
规范化翻译文本(英语) 这首歌的音乐风格是百分之百的迪斯科
示例 2:
源音频(中文)
原文记录(中文) 弗雷德里克王子,英国王室成员,为乔治二世之孙,乔治三世之幼弟。
CVSS-C 翻译音频(英语)
CVSS-T 翻译音频(英语)
翻译文本(英文) 弗雷德里克王子,英国王室成员,乔治二世国王的孙子,乔治三世国王的兄弟。
规范化翻译文本(英语) 弗雷德里克王子 英国王室成员 乔治国王的孙子 乔治三世国王的二弟
基线模型
在每个版本的 CVSS 上,我们都训练了一个基线级联 S2ST 模型以及两个基线直接 S2ST 模型,并比较了它们的性能。这些基线可用于未来研究中的比较。
级联 S2ST :为了构建强大的级联 S2ST 基线,我们在 CoVoST 2 上训练了一个 ST 模型,在不使用额外数据的情况下,该模型在所有 21 个语言对上的平均BLEU比之前的最佳水平高出 +5.8 (详见论文)。此 ST 模型与用于构建 CVSS 的相同 TTS 模型相连,以组成非常强大的级联 S2ST 基线(ST → TTS)。
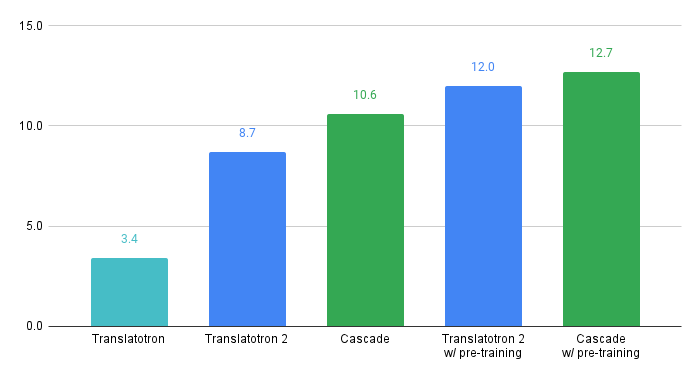
直接 S2ST :我们使用Translatotron和Translatotron 2构建了两个基线直接 S2ST 模型。使用 CVSS 从头开始训练时,Translatotron 2 (8.7 BLEU) 的翻译质量接近强级联 S2ST 基线 (10.6 BLEU)。此外,当两者都使用预训练时,ASR 转录翻译的差距缩小到仅 0.7 BLEU。这些结果验证了使用 CVSS 训练直接 S2ST 模型的有效性。
基于 CVSS-C 构建的基线直接和级联 S2ST 模型的翻译质量,通过语音翻译的 ASR 转录的 BLEU 进行测量。预训练是在 CoVoST 2 上进行的,没有其他额外的数据集。
结论
我们发布了两个版本的多语言到英语 S2ST 数据集,CVSS-C和CVSS-T,每个数据集包含约 1.9K 小时的句子级并行 S2ST 对,涵盖 21 种源语言。CVSS-C 中的翻译语音采用单个标准说话者的声音,而 CVSS-T 中的翻译语音采用从源语音转换而来的声音。这些数据集中的每一个都提供了其他公共 S2ST 语料库中不存在的独特价值。
我们在两个数据集上构建了基线多语言直接 S2ST 模型和级联 S2ST 模型,可用于未来工作的比较。为了构建强大的级联 S2ST 基线,我们在 CoVoST 2 上训练了一个 ST 模型,当在没有额外数据的语料库上训练时,该模型的平均 BLEU 比之前的最新水平高出 +5.8。尽管如此,当从头开始训练时,直接 S2ST 模型的性能接近强级联基线,而当使用预训练时,ASR 转录翻译的 BLEU 差异仅为 0.7。我们希望这项工作有助于加速对直接 S2ST 的研究。
致谢
我们感谢Common Voice和LibriVox项目的志愿者贡献者和组织者对录音的贡献和收集,以及Common Voice、CoVoST、CoVoST 2、Librispeech和LibriTTS语料库的创建者之前所做的工作。CVSS 语料库和本文的直接贡献者包括 Ye Jia、Michelle Tadmor Ramanovich、Quan Wang、Heiga Zen。我们还要感谢 Ankur Bapna、Yiling Huang、Jason Pelecanos、Colin Cherry、Alexis Conneau、Yonghui Wu、Hadar Shemtov 和 Françoise Beaufays 提供的有益讨论和支持。
评论