现在,语言模型能够通过读取指令(通常是它们以前从未见过的指令)来执行许多新的自然语言处理(NLP) 任务。推理新任务的能力主要归功于对各种独特指令(称为“指令调整”)进行模型训练,该指令由FLAN引入,并在T0、超自然指令、MetaICL和InstructGPT中进行了扩展。然而,推动这些进步的大部分数据仍未向更广泛的研究界公布。
在“ Flan 集合:设计数据和方法以进行有效的指令调整”中,我们仔细研究并发布了一个更新、更广泛的公开可用的指令调整任务、模板和方法集合,以提高社区分析和改进指令调整方法的能力。该集合首次用于Flan-T5 和 Flan-PaLM,后者比PaLM取得了显着的改进。我们表明,在这个集合上训练模型在所有测试的评估基准上都比同类公共集合获得了更好的性能,例如,在大规模多任务语言理解(MMLU) 评估套件中的 57 个任务上提高了 3% 以上,在BigBench Hard (BBH)上提高了 8% 。分析表明,改进既源于更大、更多样化的任务集,也源于应用一组简单的训练和数据增强技术,这些技术既便宜又易于实现:在训练中混合零样本、小样本和思路链提示,通过输入反转丰富任务,并平衡任务混合。这些方法共同使生成的语言模型能够更有效地推理任意任务,即使是那些它没有看到任何微调示例的任务。我们希望公开这些发现和资源将加速对更强大和通用的语言模型的研究。
公共指令调整数据收集
自 2020 年以来,多个指令调优任务集相继发布,如下面的时间线所示。最近的研究尚未围绕一套统一的技术形成,其中有各种不同的任务集、模型大小和输入格式。这个新集合,以下称为“Flan 2022”,将之前的FLAN、P3/T0和Natural Instructions集合与新的对话、程序合成和复杂推理任务相结合。
公共指令调整集合的时间表,包括:UnifiedQA、CrossFit、Natural Instructions、FLAN、P3/T0、MetaICL、ExT5、Super-Natural Instructions、mT0、Unnatural Instructions、Self-Instruct和OPT-IML Bench。该表描述了发布日期、任务集合名称、模型名称、使用此集合微调的基础模型、模型大小、生成的模型是公开的(绿色)还是非公开的(红色)、它们是否使用零样本提示(“ZS”)、小样本提示(“FS”)、思路链提示(“CoT”)一起(“+”)或单独(“/”)训练,Flan 2022 中此集合的任务数、示例总数,以及这些工作中使用的与集合相关的一些值得注意的方法。请注意,任务和示例的数量在不同的假设下会有所不同,近似值也是如此。每个计数都是使用各自作品中的任务定义来报告的。
除了扩展到更具指导性的训练任务外,Flan Collection 还将训练与不同类型的输入输出规范相结合,包括仅指令(零样本提示)、带有任务示例的指令(少样本提示)以及要求对答案进行解释的指令(思路链提示)。除了利用专有数据集合的InstructGPT之外,Flan 2022 是第一部公开展示在训练过程中混合这些提示设置的强大优势的作品。无需在各种设置之间进行权衡,在训练期间混合提示设置可以在推理时改进所有提示设置,如下所示,针对微调任务集中的保留任务和保留任务进行了演示。
使用零样本和少样本提示模板进行联合训练可提高保留任务和保留任务的表现。星号表示每种设置下的峰值表现。红线表示零样本提示评估,淡紫色表示少样本提示评估。
评估指令调整方法
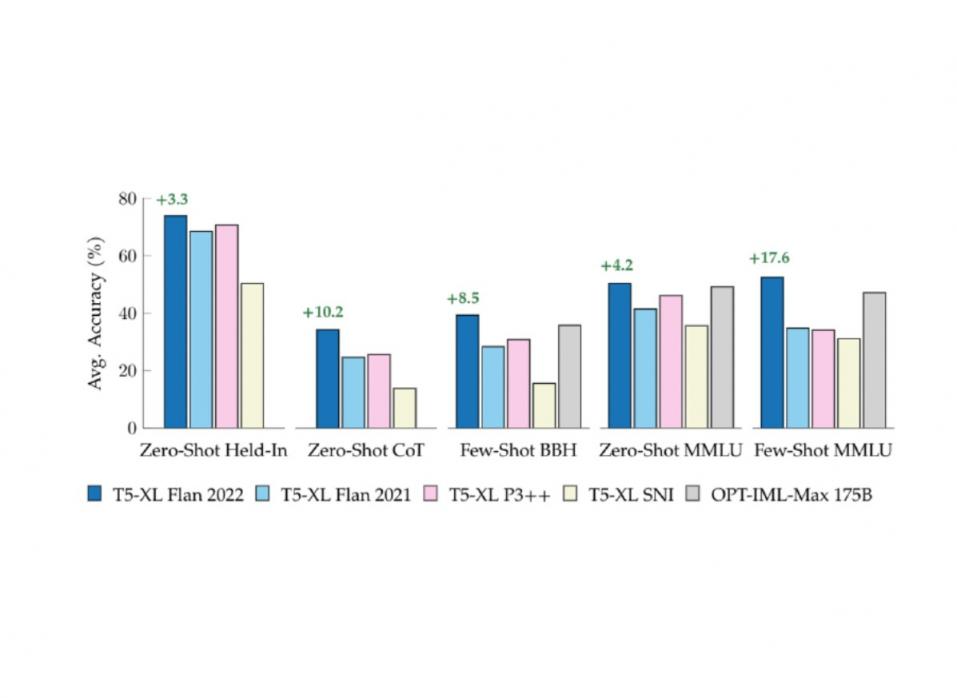
为了了解将一个指令调优集合换成另一个指令调优集合的整体效果,我们在流行的公共指令调优集合(包括 Flan 2021、T0++ 和 Super-Natural Instructions)上对等大小的T5模型进行了微调。然后,在一组已包含在每个指令调优集合中的任务、一组五个思路链任务以及一组来自MMLU基准的 57 个不同任务上对每个模型进行评估,这两个任务都带有零样本和少量样本提示。在每种情况下,新的 Flan 2022 模型 Flan-T5 都优于这些先前的研究,展示了更强大的通用 NLP 推理器。
在保留、思路链和保留外评估套件(如BigBench Hard和MMLU )上比较公共指令调优集合。除 OPT-IML-Max (175B) 外的所有模型均由我们使用具有 3B 参数的 T5-XL 进行训练。绿色文本表示比下一个最佳可比 T5-XL (3B) 模型有所改进。
单任务微调
在应用环境中,从业者通常会部署专门针对一项目标任务进行微调的 NLP 模型,其中训练数据已经可用。我们研究此设置以了解 Flan-T5 与 T5 模型的比较情况,作为应用从业者的起点。比较了三种设置:直接在目标任务上微调 T5、在目标任务上使用 Flan-T5 而不进行进一步微调,以及在目标任务上微调 Flan-T5。对于保持任务和保持任务,微调 Flan-T5 比直接微调 T5 有改进。在某些情况下,通常是目标任务的训练数据有限,无需进一步微调的 Flan-T5 优于直接微调的 T5。
Flan-T5 在单任务微调方面表现优于 T5。我们比较了单任务微调的 T5(蓝色条)、单任务微调的 Flan-T5(红色)和未经任何进一步微调的 Flan-T5(米色)。
使用 Flan-T5 作为起点的另一个好处是,训练速度明显更快、成本更低,收敛速度比 T5 微调更快,并且通常可以达到更高的准确度。这意味着,在特定任务上实现类似或更好的结果可能需要更少的任务特定训练数据。
对于 Flan 微调的五个保留任务,Flan-T5 在单任务微调上的收敛速度比 T5 更快。Flan-T5 的学习曲线用实线表示,T5 的学习曲线用虚线表示。Flan 微调期间保留了所有任务。
对于 NLP 社区来说,采用像 Flan-T5 这样的指令调整模型进行单任务微调,而不是采用传统的非指令调整模型,可以带来显著的能源效率优势。虽然预训练和指令微调在财务和计算上都很昂贵,但它们是一次性成本,通常会在数百万次后续微调运行中摊销,对于最突出的模型来说,总体而言成本会更高。指令调整模型提供了一种有希望的解决方案,可以显著减少实现相同或更好性能所需的微调步骤数量。
结论
新的 Flan 指令调优集合统一了之前最受欢迎的公共集合及其方法,同时添加了新模板和简单的改进,例如使用混合提示设置进行训练。在零样本和小样本变体中,该方法在保留、思路链、MMLU 和 BBH 基准测试中比 Flan、P3 和超自然指令高出 3-17%。结果表明,对于有兴趣推广到新指令或对单个新任务进行微调的研究人员和从业者来说,这个新集合是一个更高效的起点。
致谢
我很荣幸能与 Jason Wei、Barret Zoph、Le Hou、Hyung Won Chung、Tu Vu、Albert Webson、Denny Zhou 和 Quoc V Le 合作完成这个项目。
评论