世界上的许多语言都涵盖众多地区变体 (有时称为方言),例如巴西葡萄牙语和欧洲葡萄牙语,或大陆和台湾普通话。尽管这些变体对于其使用者来说通常可以互相理解,但它们之间仍然存在重要差异。例如,巴西葡萄牙语中“公共汽车”的单词是ônibus,而欧洲葡萄牙语中“公共汽车”的单词是autocarro。然而,当今的机器翻译(MT) 系统通常不允许用户指定要翻译成哪种语言变体。如果系统输出“错误”的变体或以不自然的方式混合变体,可能会导致混淆。此外,不了解地区的机器翻译系统倾向于青睐在线数据较多的变体,这会对资源不足的语言变体的使用者产生不成比例的影响。
在《计算语言学协会会刊》接受发表的 “ FRMT:少样本区域感知机器翻译的基准”中,我们通过对巴西葡萄牙语与欧洲葡萄牙语以及大陆普通话与台湾普通话的案例研究,提供了一个用于衡量机器翻译系统支持区域变体能力的评估数据集。随着 FRMT 数据和随附评估代码的发布,我们希望能够激励和帮助研究界发现创建适用于全球大量区域语言变体的机器翻译系统的新方法。
挑战:小样本泛化
大多数现代机器翻译系统都是基于数百万或数十亿个示例翻译进行训练的,例如一个英语输入句子及其对应的葡萄牙语翻译。但是,绝大多数可用的训练数据都没有指定翻译属于哪种地域变体。鉴于数据稀缺,我们将 FRMT 定位为小样本翻译的基准,衡量在给定每种语言变体不超过 100 个标记示例的情况下机器翻译模型翻译成地域变体的能力。机器翻译模型需要使用少量标记示例(称为“样本”)中展示的语言模式来识别未标记的训练示例中的类似模式。通过这种方式,模型可以进行概括,对样本中未明确显示的现象产生正确的翻译。
这是将英语句子“公交车到了”翻译成两种地区葡萄牙语的少样本机器翻译系统的示意图:巴西葡萄牙语(🇧🇷;左)和欧洲葡萄牙语(🇵🇹;右)。
少量样本机器翻译方法之所以具有吸引力,是因为它们使得在现有系统中添加对其他区域变体的支持变得更容易。虽然我们的工作专门针对两种语言的区域变体,但我们预计,表现良好的方法将很容易应用于其他语言和区域变体。原则上,这些方法也适用于其他语言区别,例如形式和风格。
数据收集
FRMT 数据集包含部分英文维基百科文章,来源于Wiki40b数据集,由付费专业翻译人员翻译成不同地区的葡萄牙语和普通话。为了突出关键的区域感知翻译挑战,我们使用三个内容类别设计了数据集:(1) 词汇、(2) 实体和 (3) 随机。
词汇桶关注词汇选择的区域差异,例如将包含“ bus ”一词的句子分别翻译成巴西葡萄牙语和欧洲葡萄牙语时,“ ônibus ”与“ autocarro ”的区别。我们根据博客和教育网站手动收集了 20-30 个具有区域特色翻译的术语,并根据来自每个地区的志愿者母语人士的反馈筛选和审查了这些翻译。根据生成的英语术语列表,我们从相关的英语维基百科文章(例如,bus)中提取了最多 100 个句子的文本。对普通话也进行了相同的过程。
实体存储桶的填充方式类似,涉及与给定语言的两个区域之一密切相关的人、位置或其他实体。考虑一个示例句子,例如“在里斯本,我经常乘坐公共汽车。”为了将其正确地翻译成巴西葡萄牙语,模型必须克服两个潜在的陷阱:
里斯本和葡萄牙之间的紧密地理关联可能会影响模型生成欧洲葡萄牙语翻译,例如选择“ autocarro ”而不是“ ônibus ”。
对于模型来说, 用“巴西利亚”代替“里斯本”可能是一种将其输出本地化为巴西葡萄牙语的简单方法,但即使在流畅的翻译中,在语义上也是不准确的。
随机桶用于检查模型是否正确处理其他不同现象,由从维基百科的“特色”和“好”集合中随机抽取的 100 篇文章的文本组成。
评估方法
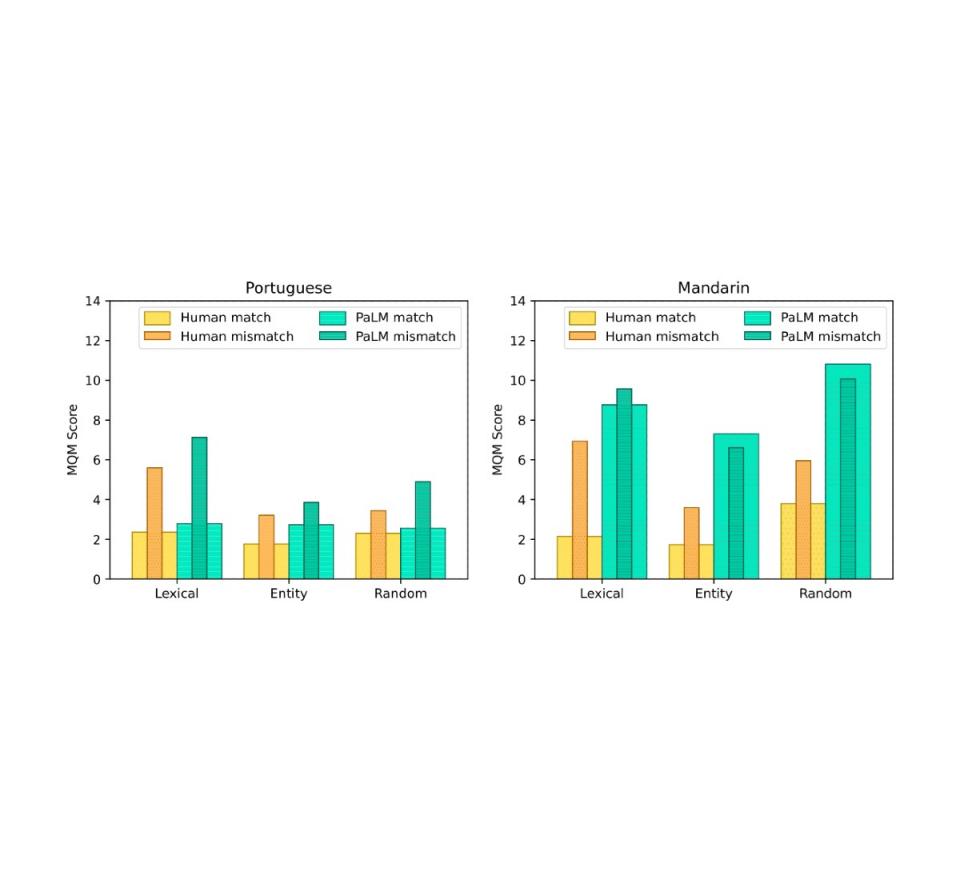
为了验证 FRMT 数据集收集的翻译是否捕捉到了特定地区的现象,我们对它们的质量进行了人工评估。每个地区的专家注释者使用多维质量指标(MQM) 框架来识别和分类翻译中的错误。该框架包括一个类别加权方案,将识别出的错误转换为一个分数,该分数大致代表每个句子的主要错误数量;因此,数字越低,翻译越好。对于每个地区,我们要求 MQM 评分员对他们所在地区的翻译和他们语言的另一个地区的翻译进行评分。例如,巴西葡萄牙语评分员对巴西葡萄牙语和欧洲葡萄牙语翻译进行评分。这两个分数之间的差异表明,在一种语言中可以接受,但在另一种语言中不可接受的语言现象普遍存在。我们发现,在葡萄牙语和中文中,评分员在错配翻译中发现的每个句子的主要错误平均比匹配翻译中多出大约两个。这表明我们的数据集确实捕捉到了特定地区的现象。
虽然人工评估是确保模型质量的最佳方式,但它通常很慢而且成本高昂。因此,我们希望找到一种现有的自动指标,让研究人员可以使用它在我们的基准上评估他们的模型,并考虑了chrF、BLEU和BLEURT。使用我们的 MQM 评分员也评估过的几个基线模型的翻译,我们发现 BLEURT 与人类判断的相关性最好,并且这种相关性的强度(0.65皮尔逊相关系数,ρ)与注释者之间的一致性(0.70 类内相关性)相当。
公制 皮尔逊 ρ
细胞因子 0.48
布鲁 0.58
布莱尔 0.65
FRMT 子集上不同自动指标与人工翻译质量判断之间的相关性。值介于 -1 和 1 之间;值越高越好。
系统性能
我们的评估涵盖了少数能够进行少样本控制的近期模型。根据 MQM 的人工评估,所有基线方法都表现出一定程度的葡萄牙语本地化输出能力,但对于普通话,它们大多未能利用目标区域的知识来生成优质的大陆或台湾翻译。
在我们评估的基准模型中,Google 的最新语言模型PaLM被评为总体最佳。为了使用 PaLM 生成针对区域的翻译,我们将指导性提示输入到模型中,然后从中生成文本来填补空白(参见下面的示例)。
将以下文本从英语翻译成欧洲葡萄牙语。
英语:[英语示例1]。
欧洲葡萄牙语:[正确翻译1]。
...
英语:[输入]。
欧洲葡萄牙语:_____”
PaLM 使用单个示例获得了出色的结果,而当示例增加到 10 个时,葡萄牙语的质量略有提高。考虑到 PaLM 是以无监督方式训练的,这种表现令人印象深刻。我们的结果还表明,像 PaLM 这样的语言模型可能特别擅长记忆流畅翻译所需的特定区域词汇选择。然而,PaLM 与人类的表现之间仍然存在显著的性能差距。有关更多详细信息, 请参阅我们的论文。
使用人工和 PaLM 翻译的 MQM 在数据集桶中的表现。粗条表示区域匹配的情况,其中来自每个区域的评估者评估针对他们自己区域的翻译。细的插入条表示区域不匹配的情况,其中来自每个区域的评估者评估针对另一个区域的翻译。人工翻译在所有情况下都表现出区域现象。PaLM 翻译仅对所有葡萄牙语桶和普通话词汇桶表现出区域现象。
结论
在不久的将来,我们希望看到一个语言生成系统(尤其是机器翻译)可以支持所有说话者群体的世界。我们希望在用户所在的地方与他们见面,生成流畅且适合其所在地区或区域的语言。为此,我们发布了FRMT 数据集和基准,使研究人员能够轻松比较区域感知机器翻译模型的性能。通过我们全面的人工评估研究验证,FRMT 中的语言变体具有显著差异,区域感知机器翻译模型的输出应该反映这些差异。我们很高兴看到研究人员如何利用这个基准来开发新的机器翻译模型,以更好地支持代表性不足的语言变体和所有说话者群体,从而提高自然语言技术的公平性。
致谢
我们衷心感谢本论文的合著者对本项目做出的所有贡献:Timothy Dozat、Xavier Garcia、Dan Garrette、Jason Riesa、Orhan Firat 和 Noah Constant。感谢 Jacob Eisenstein、Noah Fiedel、Macduff Hughes 和 Mingfei Lau 对本论文的有益讨论和评论。感谢 Andre Araujo、Chung-Ching Chang、Andreia Cunha、Filipe Gonçalves、Nuno Guerreiro、Mandy Guo、Luis Miranda、Vitor Rodrigues 和 Linting Xue 对特定区域语言差异提供的重要反馈。感谢 Google Translate 团队在收集人工翻译和评分方面提供的后勤支持。感谢专业翻译人员和 MQM 评分员在制作数据集方面发挥的作用。我们还要感谢 Tom Small 为本篇文章提供动画。
评论