过去几十年见证了光学字符识别(OCR) 技术的快速发展,该技术已从深度学习研究早期突破中使用的学术基准任务发展成为消费设备和第三方开发人员日常使用的有形产品。这些 OCR 产品将存储在纸质或基于图像的来源(例如书籍、杂志、报纸、表格、路牌、餐厅菜单)中的宝贵信息数字化和民主化,以便可以通过最先进的自然语言处理技术对其进行索引、搜索、翻译和进一步处理。
场景文本检测和识别(或场景文本识别) 研究是这一快速发展的主要驱动力,它通过将 OCR 应用于背景比文档图像更复杂的自然图像。然而,这些研究工作侧重于检测和识别图像中的每个单词,而不了解这些单词如何组成句子和文章。
布局分析是另一项相关的研究,它获取文档图像并提取其结构,即标题、段落、标题、图表、表格和说明。这些布局分析工作与 OCR 并行,并且在很大程度上是作为独立技术开发的,通常仅在文档图像上进行评估。因此,OCR 和布局分析之间的协同作用仍未得到充分探索。我们认为 OCR 和布局分析是相互补充的任务,使机器学习能够解释图像中的文本,并且当它们结合起来时,可以提高这两项任务的准确性和效率。
考虑到这一点,我们宣布举办分层文本检测与识别竞赛(HierText 挑战赛),作为第 17 届年度国际文档分析与识别会议(ICDAR 2023) 的一部分。该竞赛在Robust Reading 竞赛网站上举办,是统一 OCR 和布局分析的首次重大努力。在本次竞赛中,我们邀请来自世界各地的研究人员构建系统,使用聚类成行和段落的单词对图像中的文本进行分层注释。我们希望这次比赛将对基于图像的文本理解产生重大而长期的影响,目标是巩固 OCR 和布局分析的研究成果,并为下游信息处理任务创建新的信号。
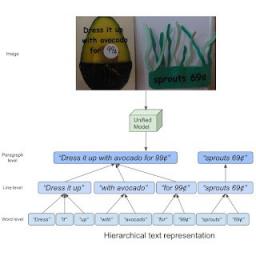
分层文本表示的概念。
构建分层文本数据集
在本次比赛中,我们使用了在CVPR 2022上发表的论文《面向端到端统一场景文本检测和布局分析》中的HierText 数据集。它是第一个提供文本分层注释的真实图像数据集,包含单词、行和段落级别的注释。在这里,“单词”被定义为不被空格打断的文本字符序列。然后,“行”被解释为“空格”分隔的“单词”簇,它们在一个方向上逻辑上连接,并在空间上接近对齐。最后,“段落”由共享相同语义主题且几何连贯的“行”组成。
为了构建此数据集,我们首先使用Google Cloud Platform (GCP)文本检测 API从Open Images 数据集中注释了图像。我们筛选了这些带注释的图像,仅保留文本内容和布局结构丰富的图像。然后,我们与第三方合作伙伴合作,手动更正所有转录并标记单词、行和段落组成。结果,我们获得了 11,639 张转录图像,分为三个子集:(1) 包含 8,281 张图像的训练集,(2) 包含 1,724 张图像的验证集,以及 (3) 包含 1,634 张图像的测试集。如论文中所述,我们还检查了我们的数据集TextOCR和英特尔 OCR (两者也从 Open Images 中提取了带注释的图像)之间的重叠,确保 HierText 数据集中的测试图像未包含在 TextOCR 或英特尔 OCR 训练和验证分组中,反之亦然。下面,我们使用 HierText 数据集对示例进行可视化,并通过用不同颜色为每个文本实体着色来演示分层文本的概念。我们可以看到 HierText 具有图像域的多样性、文本布局和高文本密度。
来自 HierText 数据集的样本。左:每个词实体的图示。中:行聚类的图示。右:段落聚类的图示。
文本密度最高的数据集
除了新颖的层次化表示之外,HierText 还代表了文本图像的新领域。我们注意到,HierText 是目前最密集的公开 OCR 数据集。下面我们总结了与其他 OCR 数据集相比,HierText 的特点。HierText 平均每幅图像识别 103.8 个单词,密度是 TextOCR 的 3 倍多,是ICDAR-2015 的25 倍。这种高密度对检测和识别提出了独特的挑战,因此 HierText 被用作 Google OCR 研究的主要数据集之一。
数据集 训练分组 验证拆分 测试拆分 每张图片的字数
ICDAR-2015 1,000 0 500 4.4
文本OCR 21,778 3,124 3,232 32.1
英特尔 OCR 19,1059 16,731 0 10.0
层次文本 8,281 1,724 1,634 103.8
将几个 OCR 数据集与 HierText 数据集进行比较。
空间分布
我们还发现,与其他 OCR 数据集(包括TextOCR、Intel OCR、IC19 MLT、COCO-Text和IC19 LSVT)相比,HierText 数据集中的文本具有更均匀的空间分布。这些先前的数据集往往具有构图良好的图像,其中文本位于图像中间,因此更容易识别。相反,HierText 中的文本实体广泛分布在图像中。这证明我们的图像来自更多样化的领域。这一特性使 HierText 在公共 OCR 数据集中具有独特的挑战性。
不同数据集中文本实例的空间分布。
HierText 的挑战
HierText 挑战赛代表着一项新任务,对 OCR 模型提出了独特的挑战。我们邀请研究人员参加这项挑战赛,并在今年加利福尼亚州圣何塞参加ICDAR 2023。我们希望这项比赛能够激发研究界对具有丰富信息表示的 OCR 模型的兴趣,这些模型可用于新颖的下游任务。
致谢
本项目的核心贡献者有:Shangbang Long、Siyang Qin、Dmitry Panteleev、Alessandro Bissacco、Yasuhisa Fujii 和 Michalis Raptis。Ashok Popat 和 Jake Walker 提供了宝贵的建议。我们还要感谢巴塞罗那自治大学的 Dimosthenis Karatzas 和 Sergi Robles 帮助我们建立了竞赛网站。
评论