大型深度学习模型正在成为各种关键机器学习 (ML) 任务的主力。然而,事实表明,如果没有任何保护措施,恶意行为者很可能会攻击各种模式的模型,从而泄露来自单个训练示例的信息。因此,防止此类信息泄露至关重要。
差分隐私(DP) 为攻击者提供正式保护,防止攻击者窃取有关训练数据的信息。深度学习中最流行的 DP 训练方法是差分隐私随机梯度下降(DP-SGD)。其核心方法实现了 DP 中的一个常见主题:用噪声“模糊化”算法的输出,以掩盖任何单个输入的贡献。
实际上,对于非常大的模型, DP 训练可能非常昂贵甚至无效。当需要隐私保证时,不仅计算成本通常会增加,而且噪声也会成比例增加。鉴于这些挑战,最近人们对开发能够实现高效DP 训练的方法产生了浓厚的兴趣。目标是开发简单实用的方法来生成高质量的大规模隐私模型。
ImageNet分类基准是实现这一目标的有效测试平台,因为 1) 即使在非隐私环境中,这也是一项具有挑战性的任务,需要足够大的模型才能成功对大量不同的图像进行分类;2) 它是一个公开的开源数据集,其他研究人员可以访问并用于协作。通过这种方法,研究人员可以模拟一个实际情况,即需要使用大型模型在具有 DP 保证的隐私数据上进行训练。
为此,今天我们讨论了在训练高效用、大规模隐私模型方面取得的改进。首先,在“大规模迁移学习用于差异隐私图像分类”中,我们分享了在具有 DP 约束的 ImageNet-1k 数据集上进行图像分类这一具有挑战性的任务时取得的强大成果。我们表明,通过结合大规模迁移学习和精心选择的超参数,即使在具有挑战性的任务和高维模型上,也确实有可能显着缩小隐私和非隐私性能之间的差距。然后在“根据特征进行差异隐私图像分类”中,我们进一步表明,使用更先进的优化算法仅对预训练模型的最后一层进行隐私微调可以进一步提高性能,从而在包括 ImageNet-1k 在内的各种流行图像分类基准上获得新的最先进的 DP 结果。为了鼓励在这个方向上进一步发展并使其他研究人员能够验证我们的发现,我们还发布了相关的源代码。
迁移学习和差异隐私
迁移学习背后的主要思想是重复使用从解决一个问题中获得的知识,然后将其应用于相关问题。当目标问题的数据有限或质量较低时,这尤其有用,因为它使我们能够利用从更大、更多样化的公共数据集中获得的知识。
在 DP 的背景下,迁移学习已经成为一种很有前途的技术,它利用从预训练任务中学到的知识来提高隐私模型的准确性。例如,如果一个模型已经在大型公共数据集上针对类似的隐私敏感任务进行了训练,那么它可以在更小、更具体的数据集上针对目标 DP 任务进行微调。更具体地说,首先在没有隐私问题的大型数据集上对模型进行预训练,然后在敏感数据集上私下微调该模型。在我们的工作中,我们提高了 DP 迁移学习的有效性,并通过在公开可用的数据集(即 ImageNet-1k、CIFAR-100 和 CIFAR-10)上模拟私人训练来说明它。
更好的预训练可以提高 DP 性能
为了开始探索迁移学习如何有效地用于差分隐私图像分类任务,我们仔细研究了影响 DP 性能的超参数。令人惊讶的是,我们发现,通过精心选择的超参数(例如,将最后一层初始化为零并选择较大的批量大小),仅对预训练模型的最后一层进行私密微调就可以比基线产生显着改进。仅训练最后一层还可以显著提高使用 DP 训练高质量图像分类模型的成本效用比。
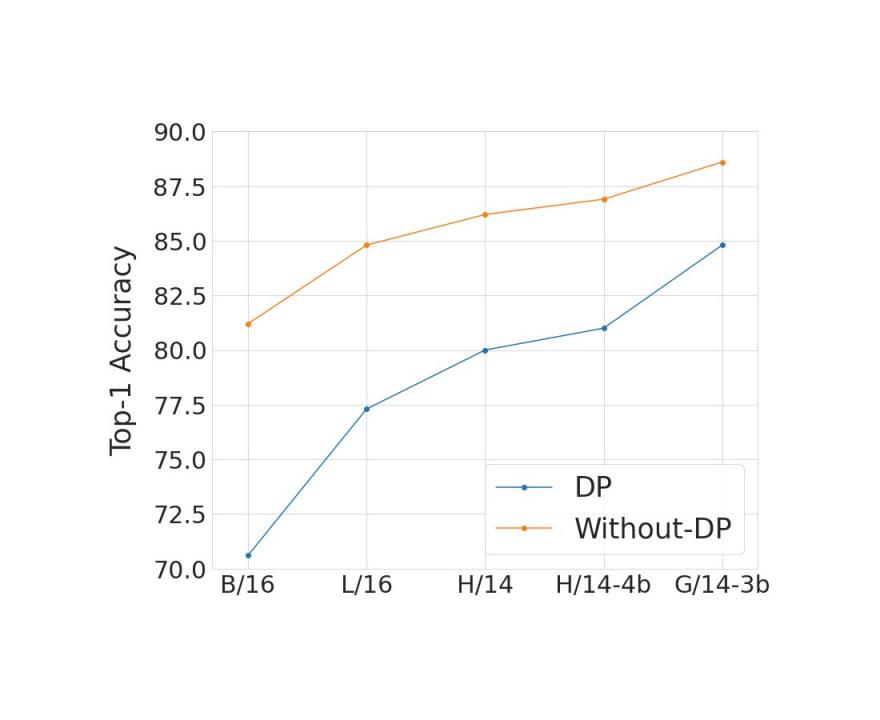
如下所示,我们比较了在各种模型和预训练数据集大小下,在有隐私和无隐私的情况下,最佳超参数建议在 ImageNet 上的表现。我们发现,扩展模型并使用更大的预训练数据集可以缩小因添加隐私保证而导致的准确度差距。通常,系统的隐私保证以正参数 ε 为特征,ε 越小,隐私性越好。在下图中,我们使用 ε = 10 的隐私保证。
在 ImageNet 上比较具有和不具有隐私的最佳模型,比较模型和预训练数据集大小。X 轴从左到右按模型大小升序显示我们用于本研究的不同Vision Transformer模型。我们使用JFT-300M预训练 B/16、L/16 和 H/14 模型,使用 JFT-4B(JFT-3B的较大版本)预训练 H/14-4b,使用JFT-3B预训练 G/14-3b。我们这样做是为了研究联合扩展模型和预训练数据集(JFT-3B 或 4B)的有效性。Y 轴显示使用 ImageNet- 1k 训练集对模型进行微调(以隐私或非隐私方式)后 ImageNet-1k 测试集上的Top-1 准确率。我们始终看到,模型和预训练数据集大小的扩展减少了因增加 ε = 10 的隐私保证而导致的准确率差距。
更好的优化器可提高 DP 性能
有点令人惊讶的是,我们发现仅对预训练模型的最后一层进行私密训练可以为 DP 提供最佳效用。虽然过去的研究 [ 1、2、3 ] 在很大程度上依赖于使用一阶差分隐私训练算法(如 DP-SGD)来训练大型模型,但在仅从特征中私密学习最后一层的特定情况下,我们观察到计算负担通常足够低,可以允许更复杂的优化方案,包括二阶方法(例如牛顿法或拟牛顿法),这些方法可能更准确,但计算成本也更高。
在“根据特征进行差异化隐私图像分类”中,我们系统地探索了损失函数和优化算法的效果。我们发现,虽然常用的逻辑回归在非隐私设置中表现优于线性回归,但在隐私设置中情况却相反:对于典型的 ε 值范围 ([1, 10]),从隐私和计算的角度来看,最小二乘线性回归比逻辑回归更有效,对于更严格的 epsilon 值 (ε < 1),甚至更有效。
我们进一步探索使用 DP 牛顿法来解决逻辑回归问题。我们发现,在高隐私条件下,DP 线性回归仍然比该方法表现更好。事实上,牛顿法涉及计算Hessian(一种捕获二阶信息的矩阵),而要使该矩阵具有差分隐私性,需要在逻辑回归中添加比线性回归(具有高度结构化的 Hessian)更多的噪声。
基于这一观察,我们引入了一种称为带特征协方差的差分隐私 SGD (DP-FC) 的方法,其中我们只需用私有化的特征协方差替换逻辑回归中的 Hessian 即可。由于特征协方差仅取决于输入(而不取决于模型参数或类标签),因此我们能够在类和训练迭代之间共享它,从而大大减少需要添加以保护它的噪声量。这使我们能够将使用逻辑回归的好处与线性回归的有效隐私保护相结合,从而改善隐私效用权衡。
借助 DP-FC,我们仅通过对从强大的预训练模型中提取的特征进行 DP 微调,就在三个私有图像分类基准(即 ImageNet-1k、CIFAR-10 和 CIFAR-100)上大大超越了之前最先进的结果。
在所有三个数据集上,使用 DP-FC 方法在 ε 范围内(X 轴)进行隐私微调与top-1 准确率(Y 轴)的比较。我们观察到,更好的预训练对较低的 ε 值(更严格的隐私保障)更有帮助。
结论
我们证明,在公共数据集上进行大规模预训练是一种有效的策略,可以在私下进行微调时获得良好的结果。此外,扩展模型大小和预训练数据集可以提高私有模型的性能,并缩小与非私有模型相比的质量差距。我们进一步提供了有效使用迁移学习进行 DP 的策略。请注意,这项工作有几个值得考虑的局限性——最重要的是,我们的方法依赖于大型且值得信赖的公共数据集的可用性,而这在获取和审查方面可能具有挑战性。我们希望我们的工作对训练具有有意义的隐私保证的大型模型有用!
致谢
除了这篇博文的作者之外,这项研究还由 Abhradeep Thakurta、Alex Kurakin 和 Ashok Cutkosky 进行。我们还要感谢 Jax、Flax 和 Scenic 库的开发人员。具体来说,我们要感谢 Mostafa Dehghani 帮助我们完成 Scenic 和高性能视觉基线,以及 Lucas Beyer 帮助我们对 JFT 数据进行重复数据删除。我们还要感谢 Li Zhang、Emil Praun、Andreas Terzis、Shuang Song、Pierre Tholoniat、Roxana Geambasu 和 Steve Chien 在整个项目中激发了关于差异隐私的讨论。此外,我们还要感谢匿名审稿人 Gautam Kamath 和 Varun Kanade 在整个出版过程中提供的有益反馈。最后,我们要感谢 Google Research 的 John Anderson 和 Corinna Cortes、DeepMind 的 Borja Balle、Soham De、Sam Smith、Leonard Berrada 和 Jamie Hayes 的慷慨反馈。
评论