大型语言模型 (LLM)(如PaLM或GPT-3)表明,将 Transformer 扩展到数千亿个参数可以提高性能并释放新兴能力。然而,用于图像理解的最大密集模型仅达到 40 亿个参数,尽管研究表明,像PaLI这样有前途的多模态模型继续受益于与语言模型一起扩展视觉模型。受此启发,以及扩展 LLM 的结果,我们决定在扩展Vision Transformer的旅程中迈出下一步。
在“将 Vision Transformers 扩展到 220 亿个参数”中,我们介绍了最大的密集视觉模型 ViT-22B。它比之前最大的视觉主干模型ViT-e大 5.5 倍,后者有 40 亿个参数。为了实现这种扩展,ViT-22B 吸收了扩展文本模型(如 PaLM)的思想,提高了训练稳定性(使用QK 规范化)和训练效率(采用一种称为异步并行线性运算的新方法)。由于其修改了架构、采用了高效的分片配方并定制实施,它能够在硬件利用率很高的云 TPU上进行训练1。ViT-22B 使用冻结表示或完全微调在许多视觉任务上取得了进步。此外,该模型也已成功用于PaLM-e,这表明将 ViT-22B 与语言模型相结合的大型模型可以显著提高机器人任务的水平。
建筑学
我们的工作建立在 LLM 的许多进步之上,例如 PaLM 和 GPT-3。与标准 Vision Transformer 架构相比,我们使用了并行层,这种方法中注意力和MLP 块是并行执行的,而不是像标准 Transformer 那样按顺序执行。这种方法在PaLM中得到使用,并将训练时间缩短了 15%。
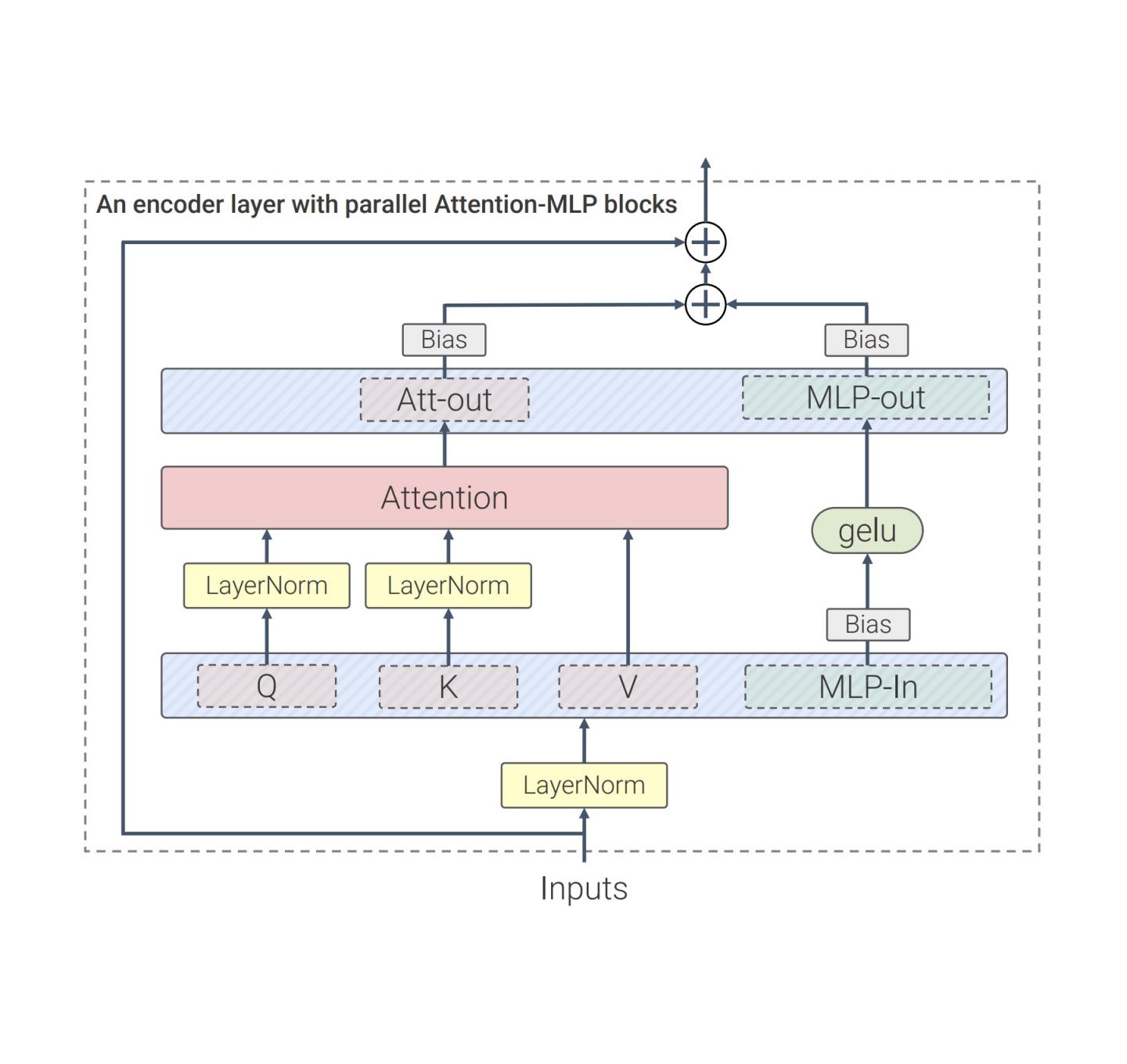
其次,ViT-22B 省略了QKV投影(自注意力机制的一部分)和LayerNorms中的偏差,从而将利用率提高了 3%。下图显示了 ViT-22B 中使用的经过修改的 Transformer 架构:
ViT-22B 变压器编码器架构使用并行前馈层,省略 QKV 和 LayerNorm 层中的偏差并规范化 Query 和 Key 投影。
这种规模的模型需要“分片”——将模型参数分布在不同的计算设备中。除此之外,我们还对激活(输入的中间表示)进行分片。即使是像矩阵乘法这样简单的事情也需要格外小心,因为输入和矩阵本身都分布在各个设备上。我们开发了一种称为异步并行线性运算的方法,通过该方法,设备之间的激活和权重通信与矩阵乘法单元(TPU 中占据绝大多数计算能力的部分)中的计算同时进行。这种异步方法最大限度地减少了等待传入通信的时间,从而提高了设备效率。下面的动画展示了矩阵乘法的示例计算和通信模式。
异步并行线性运算。目标是计算矩阵乘法 y = Ax,但矩阵 A 和激活 x 分布在不同设备上。这里我们说明了如何通过跨设备的重叠通信和计算来实现。矩阵 A 在设备之间按列分片,每个设备都包含一个连续的切片,每个块表示为 A ij。更多详细信息请参阅论文。
首先,新的模型规模导致严重的训练不稳定性。Gilmer 等人的规范化方法(2023,即将推出)解决了这些问题,实现了顺畅而稳定的模型训练;下面通过示例训练进度说明了这一点。
自注意力层中查询和键的归一化(QK 归一化)对训练动态的影响。如果没有 QK 归一化(红色),梯度会变得不稳定,训练损失会发散。
结果
这里我们重点介绍 ViT-22B 的一些结果。请注意,在论文中我们还探讨了其他几个问题领域,如视频分类、深度估计和语义分割。
为了说明学习到的表征的丰富性,我们训练了一个文本模型来生成对齐文本和图像表征的表征(使用LiT-tuning )。下面我们展示了由Parti和Imagen生成的分布外图像的几个结果:
ViT-22B 与文本模型配对的图像+文本理解示例。该图显示了每个图像描述的归一化概率分布。
人体物体识别对齐
为了了解 ViT-22B 分类决策与人类分类决策的一致程度,我们在分布外 (OOD) 数据集上评估了使用不同分辨率微调的 ViT-22B,可以通过模型与人类工具箱获得该数据集的人类比较数据。该工具箱测量三个关键指标:模型如何应对扭曲(准确度)?人类和模型的准确度有何不同(准确度差异)?最后,人类和模型的错误模式有多相似(错误一致性)?虽然并非所有微调分辨率的表现都同样出色,但 ViT-22B 变体在这三个指标上都是最先进的。此外,ViT-22B 模型还具有视觉模型中有史以来最高的形状偏差。这意味着它们主要使用物体形状而不是物体纹理来通知分类决策 — — 这是从人类感知中得知的一种策略(其形状偏差为 96%)。标准模型(例如,具有约 20-30% 形状偏差的ResNet-50)通常根据纹理(大象)对类似下图中带有大象纹理的猫的图像进行分类;具有高形状偏差的模型则倾向于关注形状(猫)。虽然人类和模型感知之间仍存在许多重要差异,但 ViT-22B 显示出与人类视觉对象识别的相似性增加。
猫还是大象?汽车还是钟表?鸟还是自行车?具有一个物体的形状和另一个物体的纹理的示例图像,用于测量形状/纹理偏差。
形状偏差评估(越高 = 形状偏差越大)。许多视觉模型具有低形状/高纹理偏差,而在ImageNet上微调的 ViT-22B (在 4B 图像上训练的红色、绿色、蓝色,如模型名称后的括号所示,除非仅在 ImageNet 上训练)具有迄今为止在 ML 模型中记录的最高形状偏差,使它们更接近人类的形状偏差。
分销外表现
测量 OOD 数据集上的性能有助于评估泛化能力。在这个实验中,我们构建了从JFT到ImageNet的标签图(数据集之间的标签映射) ,以及从 ImageNet 到不同分布外数据集(如ObjectNet)的标签图(下图左侧曲线显示了对此数据进行预训练后的结果)。然后在 ImageNet 上对模型进行全面微调。
我们观察到,扩展 Vision Transformers 会提高 OOD 性能:即使 ImageNet 准确度达到饱和,我们也会看到 ObjectNet 从 ViT-e 到 ViT-22B 有显著提升(如下图右上方的三个橙色点所示)。
尽管 ImageNet 准确度已达到饱和,但我们看到 ObjectNet 上的性能从 ViT-e/14 到 ViT-22B 显著提升。
线性探头
线性探测是一种在冻结模型之上训练单个线性层的技术。与完全微调相比,这种技术训练起来更便宜,设置起来也更容易。我们观察到,ViT-22B 性能的线性探测接近使用高分辨率图像对较小模型进行最先进的完全微调的性能(使用更高分辨率进行训练通常要昂贵得多,但对于许多任务来说,它会产生更好的结果)。以下是在 ImageNet 数据集上训练的线性探测的结果,并在 ImageNet 验证数据集和其他 OOD ImageNet 数据集上进行评估。
在ImageNet上训练的线性探测结果,在Imagenet-ReaL、ImageNet-v2、ObjectNet、ImageNet-R和ImageNet-A数据集上进行评估。高分辨率微调的 ViT-e/14 提供作为参考。
蒸馏
可以使用蒸馏方法 将较大模型的知识转移到较小的模型。这很有用,因为大模型速度较慢且使用成本较高。我们发现 ViT-22B 知识可以转移到较小的模型,如 ViT-B/16 和 ViT-L/16,从而在 ImageNet 上实现这些模型尺寸的新状态。
模型 方法(数据集) ImageNet1k 准确率
维生素-B/16 大规模图像识别 Transformers (JFT) 84.2
扩展视觉转换器(JFT) 86.6
DeiT III:ViT 的复仇( INet21k ) 86.7
从 ViT-22B (JFT) 中提取 88.6
ViT-L/16 大规模图像识别 Transformers (JFT) 87.1
扩展视觉转换器(JFT) 88.5
DeiT III:ViT 的复仇(INet21k) 87.7
从 ViT-22B (JFT) 中提取 89.6
公平与偏见
ML 模型可能会受到非预期的不公平偏见的影响,例如拾取虚假相关性(使用人口统计学均等性来衡量)或子群体之间的绩效差距。我们表明,扩大规模有助于缓解此类问题。
首先,规模提供了更有利的权衡边界——即使模型在训练后进行后处理以将其人口统计学水平控制在规定的可容忍水平以下,性能也会随着规模的扩大而提高。重要的是,这不仅适用于以准确性来衡量性能,也适用于其他指标,例如校准,这是对模型估计概率真实性的统计度量。其次,所有子群体的分类往往会随着规模的扩大而改善,如下所示。第三,ViT-22B 缩小了子群体之间的绩效差距。
顶部:消除偏差之前CelebA中每个子组的准确率。底部: y 轴显示此示例中突出显示的两个特定子组(女性和男性)之间的绝对性能差异。与较小的 ViT 架构相比,ViT-22B 的性能差距很小。
结论
我们推出了 ViT-22B,这是目前最大的视觉变换模型,拥有 220 亿个参数。通过对原始架构进行细微但关键的更改,我们实现了出色的硬件利用率和训练稳定性,从而产生了一个在多个基准上领先于最先进水平的模型。使用冻结模型生成嵌入,然后在其上训练薄层,可以获得出色的性能。我们的评估进一步表明,与现有模型相比,ViT-22B 在形状和纹理偏差方面与人类视觉感知的相似性更高,并且在公平性和稳健性方面具有优势。
致谢
这是 Mostafa Dehghani、Josip Djolonga、Basil Mustafa、Piotr Padlewski、Jonathan Heek、Justin Gilmer、Andreas Steiner、Mathilde Caron、Robert Geirhos、Ibrahim Alabdulmohsin、Rodolphe Jenatton、Lucas Beyer、Michael Tschannen、Anurag Arnab、Xiao Wang、Carlos Riquelme、Matthias Minderer、Joan Puigcerver、Utku Evci、Manoj Kumar、Sjoerd van Steenkiste、Gamaleldin Fathy、Elsayed Aravindh Mahendran、Fisher Yu、Avital Oliver、Fantine Huot、Jasmijn Bastings、Mark Patrick Collier、Alexey Gritsenko、Vighnesh Birodkar、Cristina Vasconcelos、Yi Tay、Thomas Mensink、Alexander Kolesnikov、Filip Pavetić、Dustin Tran 的合作作品,托马斯·基普夫 (Thomas Kipf)、马里奥·卢契奇 (Mario Lučić)、翟晓华、丹尼尔·凯瑟斯 (Daniel Keysers)、杰里迈亚·哈姆森 (Jeremiah Harmsen) 和尼尔·霍尔斯比 (Neil Houlsby)
我们要感谢 Jasper Uijlings、Jeremy Cohen、Arushi Goel、Radu Soricut、Xingyi Zhou、Lluis Castrejon、Adam Paszke、Joelle Barral、Federico Lebron、Blake Hechtman 和 Peter Hawkins。他们的专业知识和坚定不移的支持对本文的完成起到了至关重要的作用。我们还要感谢 Google Research 才华横溢的研究人员和工程师的合作和奉献。
评论