代码变更审查是大规模软件开发过程中的关键部分,占用了代码作者和代码审查人员的大量时间。作为此过程的一部分,审查人员会检查提议的代码,并通过用自然语言编写的评论向作者询问代码变更。在 Google,我们每年会看到数百万条审查人员的评论,并且作者在发送变更以供审查和最终提交变更之间平均需要约 60 分钟的积极引导时间。在我们的测量中,代码作者必须处理审查人员评论所需的积极工作时间几乎随评论数量线性增长。但是,借助机器学习 (ML),我们有机会自动化和简化代码审查过程,例如通过根据评论文本提出代码变更建议。
今天,我们将介绍如何在真实环境中应用大型序列模型的最新进展(使用DIDACT 方法),以自动解决 Google 日常开发工作流程中的代码审查评论。截至今天,Google 的代码更改作者通过应用 ML 建议的编辑来解决大量审阅者的评论。我们预计,这将在 Google 规模上每年减少数十万小时的代码审查时间。未经请求的非常积极的反馈突显出 ML 建议的代码编辑的影响提高了 Google 员工的工作效率,使他们能够专注于更具创造性和更复杂的任务。
预测代码编辑
我们首先训练一个模型,该模型可以预测处理审阅者评论所需的代码编辑。该模型针对各种编码任务和相关的开发人员活动(例如,重命名变量、修复损坏的构建、编辑文件)进行了预先训练。然后,根据审阅的代码更改、审阅者评论以及作者为处理这些评论而执行的编辑,针对此特定任务对其进行微调。
这是 ML 建议的分布在代码中的重构编辑的示例。
Google 使用monorepo,即其所有软件工件的单一存储库,这使我们的训练数据集包含用于构建 Google 最新软件以及以前版本的所有不受限制的代码。
为了提高模型质量,我们对训练数据集进行了迭代。例如,我们比较了每个文件有单个审阅者评论的数据集和每个文件有多个评论的数据集的模型性能,并尝试使用分类器根据小型精选数据集清理训练数据,以选择具有最佳离线精确度和召回率指标的模型。
服务基础设施和用户体验
我们在经过训练的模型上设计并实现了该功能,重点关注整体用户体验和开发人员效率。为此,我们通过一系列用户研究探索了不同的用户体验 (UX) 替代方案。然后,我们根据内部测试版(即开发中的功能测试)的见解(包括用户反馈,例如建议的修改旁边的“这有帮助吗?”按钮)改进了该功能。
最终模型的目标精度为 50%。也就是说,我们调整了模型和建议过滤,以便评估数据集上 50% 的建议编辑是正确的。一般来说,提高目标精度会减少显示的建议编辑数量,而降低目标精度会导致更多不正确的建议编辑。不正确的建议编辑会浪费开发人员的时间,并降低开发人员对该功能的信任度。我们发现 50% 的目标精度提供了良好的平衡。
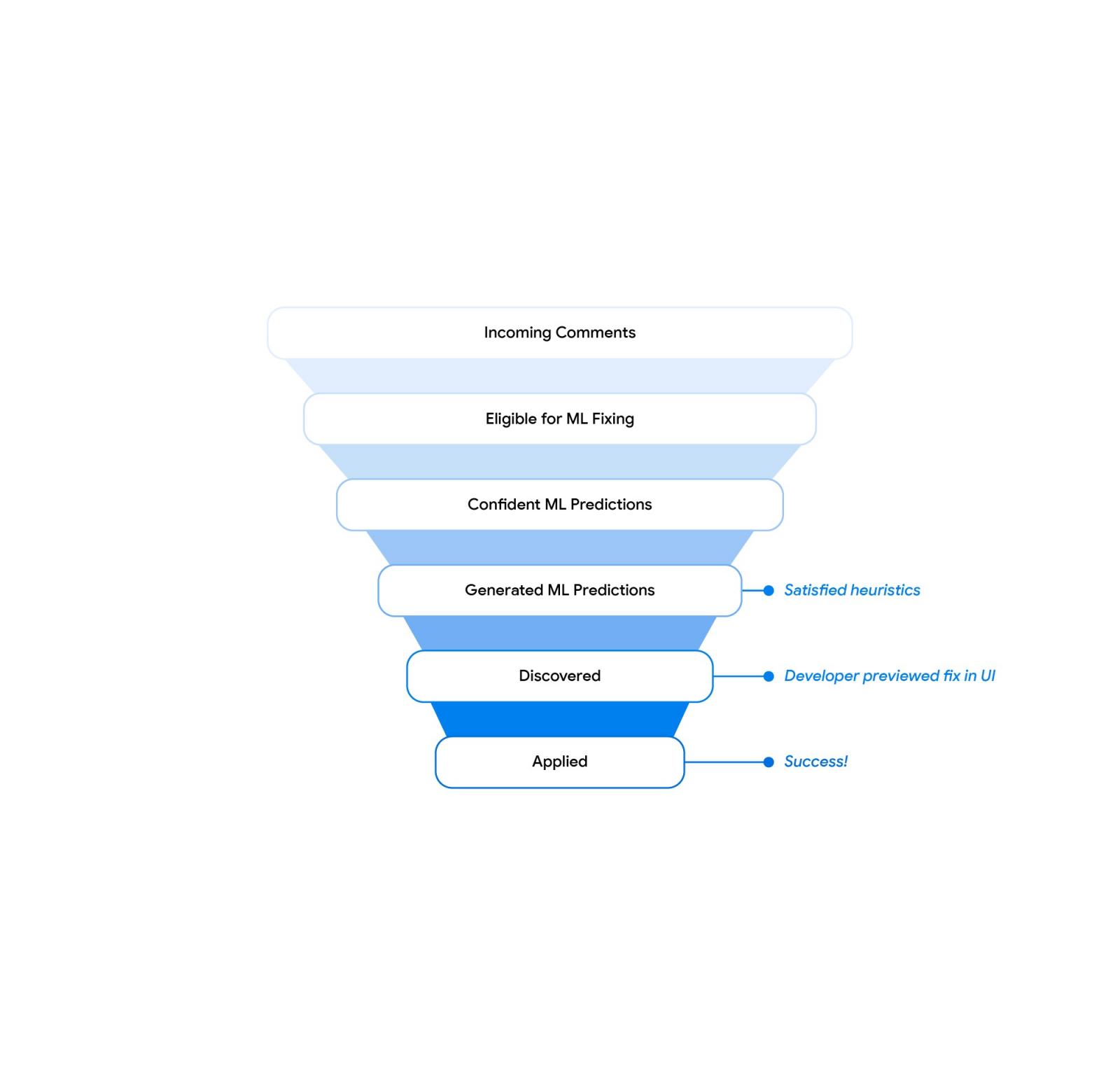
从高层次上讲,对于每条新的审阅者评论,我们都会以与训练相同的格式生成模型输入,查询模型并生成建议的代码编辑。如果模型对预测有信心并且满足一些额外的启发式方法,我们会将建议的编辑发送到下游系统。下游系统(即代码审查前端和集成开发环境 (IDE))向用户公开建议的编辑并记录用户交互,例如预览和应用事件。专用管道收集这些日志并生成汇总见解,例如本博客文章中报告的总体接受率。
ML 建议编辑基础设施的架构。我们处理来自多个服务的代码和基础设施,获取模型预测,并在代码审查工具和 IDE 中显示预测。
开发人员在代码审查工具和 IDE 中与 ML 建议的编辑进行交互。根据用户研究的见解,集成到代码审查工具中最适合简化审查体验。IDE 集成提供了额外的功能,并支持在合并结果(中间)中存在与审查代码状态(右)顶部的本地更改发生冲突的情况下,将 ML 建议的编辑(下图左侧)进行三向合并。
IDE 中的三向合并 UX。
结果
离线评估表明,该模型解决了 52% 的评论,目标准确率为 50%。测试版和全面内部发布的在线指标证实了这些离线指标,即,对于所有相关审阅者评论中约 50% 的评论,我们看到模型建议高于我们的目标模型置信度。所有预览的建议编辑中有 40% 到 50% 被代码作者采纳。
我们在测试期间使用了“无用”反馈来识别模型中反复出现的故障模式。我们实施了服务时间启发式方法来过滤这些故障模式,从而减少了显示的错误预测数量。通过这些改变,我们以数量换取质量,并观察到现实世界的接受率有所提高。
代码审查工具 UX。建议作为评论的一部分显示,可以预览、应用并评定为有用或无用。
我们的测试版发布显示出可发现性挑战:代码作者仅预览了所有生成的建议编辑的约 20%。我们修改了用户体验,并在审阅者评论旁边引入了一个显眼的“显示 ML 编辑”按钮(见上图),导致发布时的整体预览率约为 40%。我们还发现,由于作者在审阅过程中所做的更改相互冲突,代码审查工具中的建议编辑通常不适用。我们在代码审查工具中增加了一个按钮来解决这个问题,该按钮会在建议编辑的合并视图中打开 IDE。我们现在观察到,其中超过 70% 是在代码审查工具中应用的,而不到 30% 是在 IDE 中应用的。所有这些变化使我们能够将使用 ML 建议编辑处理的审阅者评论的总体比例从测试版到内部全面发布增加了 2 倍。在 Google 规模上,这些结果有助于每年自动解决数十万条评论。
建议过滤漏斗。
我们看到 ML 建议的编辑解决了生产中各种审阅者的评论。这包括简单的本地重构和分散在代码中的重构,如上述博客文章中的示例所示。该功能解决了需要代码生成、重构和导入的较长且措辞不太正式的评论。
对于需要代码生成、重构和导入的较长且措辞不太正式的评论的建议示例。
该模型还可以响应复杂的注释并生成大量代码编辑(如下所示)。生成的测试用例遵循现有的单元测试模式,同时更改注释中描述的细节。此外,编辑还为测试提供了一个反映测试语义的综合名称。
该模型响应复杂注释和产生大量代码编辑的能力的示例。
结论和未来工作
在这篇文章中,我们介绍了一项 ML 辅助功能,以减少花在代码审查相关更改上的时间。目前,谷歌已应用 ML 建议的编辑来处理大量受支持语言的所有可操作代码审查评论。一项针对所有谷歌开发人员的为期 12 周的 A/B 实验将进一步衡量该功能对整体开发人员生产力的影响。
我们正在努力改进整个堆栈。这包括提高模型的质量和召回率,并通过提高整个审核流程的可发现性为开发人员打造更简化的体验。作为其中的一部分,我们正在研究在审核者起草评论时向他们显示建议的编辑的选项,并将该功能扩展到 IDE 中,以使代码更改作者能够获得针对自然语言命令的建议代码编辑。
致谢
这是 Google Core Systems & Experiences 团队、Google Research 和 DeepMind 的许多人的工作。我们要特别感谢 Peter Choy 促成此次合作,并感谢我们所有团队成员的关键贡献和有益建议,包括 Marcus Revaj、Gabriela Surita、Maxim Tabachnyk、Jacob Austin、Nimesh Ghelani、Dan Zheng、Peter Josling、Mariana Stariolo、Chris Gorgolewski、Sascha Varkevisser、Katja Grünwedel、Alberto Elizondo、Tobias Welp、Paige Bailey、Pierre-Antoine Manzagol、Pascal Lamblin、Chenjie Gu、Petros Maniatis、Henryk Michalewski、Sara Wiltberger、Ambar Murillo、Satish Chandra、Madhura Dudhgaonkar、Niranjan Tulpule、Zoubin Ghahramani、Juanjo Carin、Danny Tarlow、Kevin Villela、Stoyan Nikolov、David Tattersall、Boris Bokowski、Kathy Nix、Mehdi Ghissassi、Luis C. Cobo、 Yujia Li、David Choi、Kristóf Molnár、Vahid Meimand、Amit Patel、Brett Wiltshire、Laurent Le Brun、Mingpan Guo、Hermann Loose、Jonas Mattes、Savinee Dancs。感谢 John Guilyard 为本文制作图片。
评论