计算机架构研究在开发模拟器和工具以评估和塑造计算机系统设计方面有着悠久的历史。例如,SimpleScalar模拟器于 20 世纪 90 年代末推出,让研究人员能够探索各种微架构思想。计算机架构模拟器和工具(如gem5、DRAMSys等)在推动计算机架构研究方面发挥了重要作用。从那时起,这些共享的资源和基础设施使行业和学术界受益匪浅,并使研究人员能够系统地借鉴彼此的工作,从而推动该领域取得重大进展。
尽管如此,计算机架构研究仍在不断发展,行业和学术界正转向机器学习 (ML) 优化以满足严格的特定领域要求,例如用于计算机架构的 ML、用于 TinyML 加速的 ML、 DNN 加速器 数据路径优化、内存控制器、功耗、安全性和隐私。尽管之前的工作已经证明了 ML 在设计优化方面的优势,但缺乏强大、可重复的基线阻碍了不同方法之间公平客观的比较,并对其部署带来了一些挑战。为了确保稳步进展,必须共同理解和应对这些挑战。
为了缓解这些挑战,我们在ISCA 2023上接受的“ ArchGym:机器学习辅助架构设计的开源健身房”中引入了 ArchGym,它包括各种计算机架构模拟器和 ML 算法。在 ArchGym 的支持下,我们的结果表明,只要有足够多的样本,各种 ML 算法中的任何一个都能够为每个目标问题找到最佳的架构设计参数集;没有一个解决方案一定比另一个更好。这些结果进一步表明,为给定的 ML 算法选择最佳超参数对于找到最佳架构设计至关重要,但选择它们并非易事。我们发布了跨多个计算机架构模拟和 ML 算法的代码和数据集。
机器学习辅助架构研究面临的挑战
机器学习辅助架构研究面临着多项挑战,包括:
对于特定的 ML 辅助计算机架构问题(例如,为DRAM控制器寻找最佳解决方案),没有系统的方法来识别最佳 ML 算法或超参数(例如,学习率、预热步骤等)。有更广泛的 ML 和启发式方法,从随机游走到强化学习(RL),可用于设计空间探索(DSE)。虽然这些方法在基线选择上显示出明显的性能改进,但尚不清楚这些改进是由于选择了优化算法还是超参数。
因此,为了确保可重复性并促进 ML 辅助架构 DSE 的广泛采用,有必要概述系统的基准测试方法。
虽然计算机架构模拟器一直是架构创新的支柱,但在架构探索中,人们越来越需要解决准确性、速度和成本之间的权衡。性能估计的准确性和速度在不同的模拟器之间差异很大,这取决于底层建模细节(例如,周期精确模型与基于ML的代理模型)。虽然分析或基于 ML 的代理模型由于丢弃低级细节而灵活,但它们通常存在较高的预测误差。此外,由于商业许可,从模拟器收集的运行次数可能会受到严格限制。总体而言,这些约束表现出不同的性能与样本效率权衡,影响了架构探索优化算法的选择。
在这些约束条件下,描述如何系统地比较各种 ML 算法的有效性是一项挑战。
最后,机器学习算法的格局正在迅速演变,一些机器学习算法需要数据才能发挥作用。此外,将 DSE 的结果转化为有意义的成果(如数据集)对于深入了解设计空间至关重要。
在这个快速发展的生态系统中,确保如何分摊架构探索的搜索算法的开销至关重要。如何在不考虑底层搜索算法的情况下利用探索数据,这一点并不明显,也没有系统地研究过。
建筑健身房设计
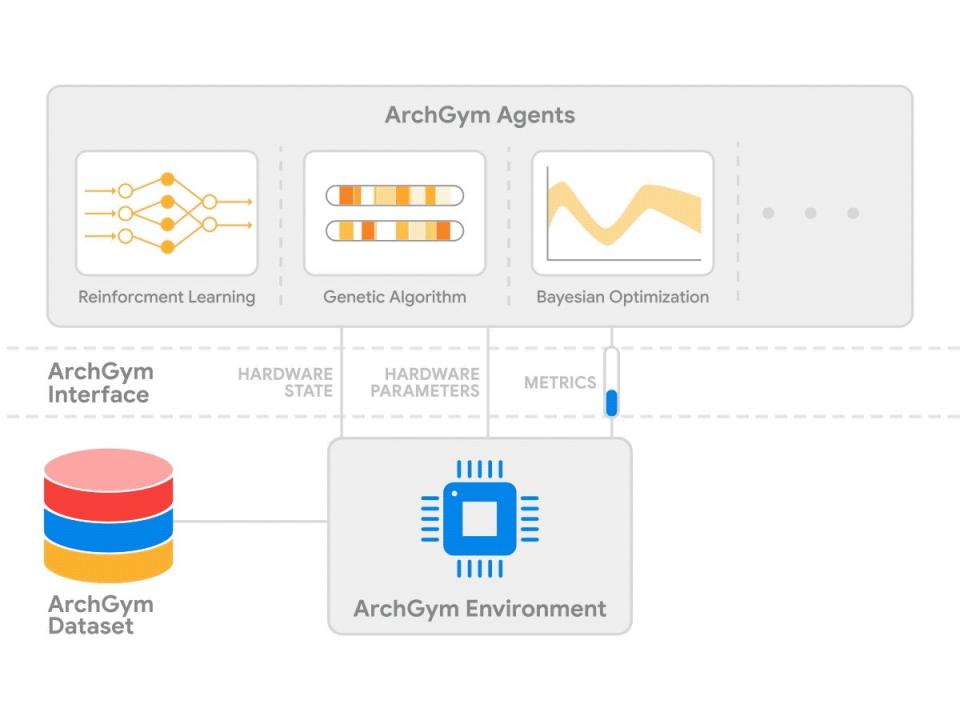
ArchGym 通过提供统一的框架来公平评估不同的基于 ML 的搜索算法,从而解决了这些挑战。它由两个主要组件组成:1) ArchGym 环境和 2) ArchGym 代理。环境是架构成本模型的封装,包括延迟、吞吐量、面积、能耗等,用于确定在给定一组架构参数的情况下运行工作负载的计算成本,并与目标工作负载配对。代理是用于搜索的 ML 算法的封装,由超参数和指导策略组成。超参数是要优化模型的算法所固有的,可以显著影响性能。另一方面,策略决定了代理如何迭代选择参数来优化目标目标。
值得注意的是,ArchGym 还包括一个连接这两个组件的标准化接口,同时还将探索数据保存为 ArchGym 数据集。该接口的核心包括三个主要信号:硬件状态、硬件参数和指标。这些信号是建立环境和代理之间有意义的通信渠道的最低限度。使用这些信号,代理可以观察硬件的状态并建议一组硬件参数来迭代优化(用户定义的)奖励。奖励是硬件性能指标的函数,例如性能、能耗等。
ArchGym 包含两个主要组件:ArchGym 环境和 ArchGym 代理。ArchGym 环境封装了成本模型,而代理是策略和超参数的抽象。ArchGym 提供了一个连接这两个组件的标准化接口,提供了一个统一的框架,可以公平地评估不同的基于 ML 的搜索算法,同时将探索数据保存为 ArchGym 数据集。
ML 算法同样可以满足用户定义的目标规范
使用 ArchGym,我们通过经验证明,在不同的优化目标和 DSE 问题中,至少存在一组超参数,可产生与其他 ML 算法相同的硬件性能。ML 算法或其基线的超参数选择不当(随机选择)可能会导致误导性结论,即某一类 ML 算法优于另一类。我们表明,通过充分的超参数调整,不同的搜索算法,甚至随机游走(RW),都能够确定最佳奖励。但是,请注意,找到正确的超参数集可能需要详尽的搜索,甚至需要运气才能使其具有竞争力。
如果有足够数量的样本,则至少存在一组超参数,它们会在一系列搜索算法中产生相同的性能。此处的虚线表示最大标准化奖励。Cloud -1、cloud-2、stream和random表示DRAMSys(DRAM 子系统设计空间探索框架)的四种不同内存轨迹。
数据集构建和高保真代理模型训练
使用 ArchGym 创建统一界面还可以创建数据集,该数据集可用于设计更好的数据驱动的基于 ML 的代理架构成本模型,以提高架构模拟的速度。为了评估数据集在构建 ML 模型以近似架构成本方面的优势,我们利用 ArchGym 从 DRAMSys 记录每次运行数据的能力来创建四个数据集变体,每个变体都有不同数量的数据点。对于每个变体,我们创建两个类别:(a) 多样化数据集,代表从不同代理(ACO、GA、RW和BO)收集的数据,(b) 仅 ACO,显示仅从 ACO 代理收集的数据,这两个数据均与 ArchGym 一起发布。我们使用随机森林回归在每个数据集上训练代理模型,目的是预测DRAM 模拟器设计的延迟。我们的结果表明:
随着数据集大小的增加,平均归一化均方根误差(RMSE) 略有下降。
然而,当我们在数据集中引入多样性(例如,从不同的代理收集数据)时,我们观察到不同数据集大小的 RMSE 降低了 9 倍到 42 倍。
使用 ArchGym 界面跨不同代理收集多样化的数据集。
多样化数据集和数据集大小对归一化 RMSE 的影响。
机器学习辅助建筑研究需要社区驱动的生态系统
虽然 ArchGym 是创建开源生态系统的初步努力,该生态系统 (1) 以统一且易于扩展的方式将广泛的搜索算法连接到计算机架构模拟器,(2) 促进 ML 辅助计算机架构的研究,以及 (3) 形成开发可重复基线的支架,但仍有许多开放挑战需要社区的支持。下面我们概述了 ML 辅助架构设计中的一些开放挑战。应对这些挑战需要协调一致的努力和社区驱动的生态系统。
ML辅助架构设计中的关键挑战。
我们将这个生态系统称为架构 2.0。我们概述了关键挑战和构建一个包容性跨学科研究人员生态系统的愿景,以解决将 ML 应用于计算机架构研究的长期未解决的问题。如果您有兴趣帮助塑造这个生态系统,请填写兴趣调查。
结论
ArchGym是 ML 架构 DSE 的开源训练中心,它启用了标准化接口,可以轻松扩展以适应不同的用例。此外,ArchGym 可以在不同的 ML 算法之间进行公平且可重复的比较,并有助于为计算机架构研究问题建立更强大的基线。
我们邀请计算机架构社区和机器学习社区积极参与 ArchGym 的开发。我们相信,为计算机架构研究创建一个体育馆式的环境将是该领域的一大进步,并为研究人员提供一个平台,让他们使用机器学习来加速研究并带来新的创新设计。
致谢
本博文基于与 Google 和哈佛大学几位合著者的合作。 我们要感谢并特别强调 Srivatsan Krishnan (哈佛大学),他与 Shvetank Prakash (哈佛大学)、Jason Jabbour (哈佛大学)、Ikechukwu Uchendu (哈佛大学)、Susobhan Ghosh (哈佛大学)、Behzad Boroujerdian (哈佛大学)、Daniel Richins (哈佛大学)、Devashree Tripathy (哈佛大学) 和 Thierry Thambe (哈佛大学) 合作为该项目贡献了许多想法。此外,我们还要感谢 James Laudon、Douglas Eck、Cliff Young 和 Aleksandra Faust 对这项工作的支持、反馈和激励。我们还要感谢 John Guilyard 为本文提供的动画人物。Amir Yazdanbakhsh 现在是 Google DeepMind 的研究科学家,Vijay Janapa Reddi 是哈佛大学的副教授。
评论