时间序列预测对于各种实际应用都至关重要,从需求预测到流行病传播预测。在多变量时间序列预测(同时预测多个变量)中,可以将现有方法分为两类:单变量模型和多变量模型。单变量模型侧重于序列间相互作用或时间模式,这些模式包含具有单个变量的时间序列上的趋势和季节性模式。此类趋势和季节性模式的例子可能是抵押贷款利率因通货膨胀而增加的方式,以及交通在高峰时段如何达到峰值。除了序列间模式之外,多变量模型还处理序列内特征,称为交叉变量信息,当一个序列是另一个序列的高级指标时,这尤其有用。例如,体重增加可能导致血压升高,而产品价格上涨可能导致销量下降。多变量模型最近已成为多变量预测的流行解决方案,因为从业者认为它们处理交叉变量信息的能力可以带来更好的性能。
近年来,基于深度学习 Transformer 的架构因其在序列任务上的出色表现而成为多变量预测模型的热门选择。然而,在常用的长期预测基准(例如电力变压器温度(ETT)、电力、交通和天气)上,高级多变量模型的表现却出奇地差于简单的单变量线性模型。这些结果提出了两个问题:
交叉变量信息是否有利于时间序列预测?
当交叉变量信息无益时,多元模型还能像单变量模型一样表现良好吗?
在《机器学习研究汇刊》(TMLR)上发表的 “ TSMixer:一种用于时间序列预测的全 MLP 架构”中,我们分析了单变量线性模型的优势并揭示了它们的有效性。从这些分析中获得的见解促使我们开发了时间序列混合器(TSMixer),这是一种先进的多变量模型,它利用线性模型特性并在长期预测基准上表现良好。据我们所知,TSMixer 是第一个在长期预测基准上表现与最先进的单变量模型一样好的多变量模型,我们表明交叉变量信息的益处较小。为了证明交叉变量信息的重要性,我们评估了一个更具挑战性的实际应用M5。最后,实证结果表明 TSMixer 优于最先进的模型,例如PatchTST、Fedformer、Autoformer、DeepAR和TFT。
TSMixer 架构
线性模型和 Transformers 之间的一个关键区别在于它们如何捕捉时间模式。一方面,线性模型应用固定且依赖于时间步长的权重来捕捉静态时间模式,无法处理跨变量信息。另一方面,Transformers 使用注意力机制,在每个时间步长应用动态且依赖于数据的权重,捕捉动态时间模式并使其能够处理跨变量信息。
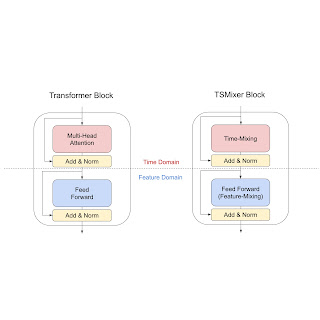
在我们的分析中,我们表明,在时间模式的常见假设下,线性模型具有完美的解决方案,可以完美地恢复时间序列或对误差设置界限,这意味着它们是更有效地学习单变量时间序列的静态时间模式的绝佳解决方案。相比之下,找到类似的注意力机制解决方案并非易事,因为应用于每个时间步骤的权重是动态的。因此,我们通过用线性层替换 Transformer 注意力层来开发一种新架构。由此产生的 TSMixer 模型类似于计算机视觉MLP-Mixer方法,在不同方向上交替应用多层感知器,我们分别称之为时间混合和特征混合。TSMixer 架构有效地捕获时间模式和跨变量信息,如下图所示。残差设计确保 TSMixer 保留时间线性模型的容量,同时仍然能够利用跨变量信息。
Transformer 块和 TSMixer 块架构。TSMixer 用时间混合(一种应用于时间维度的线性模型)取代了多头注意力层。
数据依赖(注意力机制)和时间步依赖(线性模型)之间的比较。这是通过学习前三个时间步的权重来预测下一个时间步的示例。
长期预测基准的评估
我们使用七个流行的长期预测数据集(ETTm1、ETTm2、ETTh1、ETTh2、电力、交通和天气)对 TSMixer 进行评估,最近的研究表明,单变量线性模型的表现优于先进的多元模型,且优势较大。我们将 TSMixer 与最先进的多元模型(TFT、FEDformer、Autoformer、Informer)和单变量模型(包括线性模型和PatchTST )进行了比较。下图显示了TSMixer 与其他模型相比的均方误差(MSE) 的平均改进。平均值是跨数据集和多个预测范围计算的。我们证明 TSMixer 明显优于其他多元模型,并且性能与最先进的单变量模型相当。这些结果表明多元模型的性能能够与单变量模型一样好。
TSMixer 与其他基线相比的平均 MSE 改进。红色条表示多变量方法,蓝色条表示单变量方法。TSMixer 比其他多变量模型取得了显著的改进,并且取得了与单变量模型相当的结果。
消融研究
我们进行了一项消融研究,将 TSMixer 与 TMix-Only(一种仅由时间混合层组成的 TSMixer 变体)进行比较。结果表明,TMix-Only 的表现几乎与 TSMixer 相同,这意味着额外的特征混合层并不能提高性能,并证实了交叉变量信息在流行基准上的好处较少。结果验证了先前研究中显示的优越的单变量模型性能。然而,现有的长期预测基准不能很好地代表某些实际应用中对交叉变量信息的需求,其中时间序列可能是间歇性的或稀疏的,因此时间模式可能不足以进行预测。因此,仅根据这些基准来评估多元预测模型可能是不合适的。
M5评估:交叉变量信息的有效性
为了进一步证明多变量模型的优势,我们在具有挑战性的 M5 基准上评估了 TSMixer,这是一个包含关键交叉变量相互作用的大规模零售数据集。M5 包含 5 年内收集的 30,490 种产品的信息。每种产品描述都包括时间序列数据,如每日销售额、销售价格、促销活动信息和静态(非时间序列)特征,如商店位置和产品类别。目标是预测未来 28 天每种产品的每日销售额,使用M5 竞赛中的加权均方根缩放误差(WRMSSE) 进行评估。零售业的复杂性使得仅使用关注时间模式的单变量模型进行预测更具挑战性,因此具有交叉变量信息甚至辅助特征的多变量模型更为重要。
首先,我们将 TSMixer 与仅考虑历史数据(例如每日销售额和历史销售价格)的其他方法进行比较。结果表明,多变量模型的表现明显优于单变量模型,表明交叉变量信息非常有用。在所有比较的方法中,TSMixer 有效地利用了交叉变量信息并取得了最佳表现。
此外,为了利用更多信息,例如 M5 中提供的静态特征(例如商店位置、产品类别)和未来时间序列(例如未来几天安排的促销活动),我们提出了一种扩展 TSMixer 的原理设计。扩展的 TSMixer 将不同类型的特征对齐到相同的长度,然后将多个混合层应用于连接的特征以进行预测。扩展的 TSMixer 架构优于工业应用中流行的模型,包括DeepAR和TFT,展示了其对现实世界产生影响的强大潜力。
扩展的 TSMixer 的架构。在第一阶段(对齐阶段),它将不同类型的特征对齐到相同的长度,然后再将它们连接起来。在第二阶段(混合阶段),它应用多个以静态特征为条件的混合层。
M5 上的 WRMSSE。前三种方法(蓝色)是单变量模型。中间三种方法(橙色)是仅考虑历史特征的多变量模型。后三种方法(红色)是考虑历史、未来和静态特征的多变量模型。
结论
我们提出了 TSMixer,这是一种先进的多变量模型,它利用线性模型特征,在长期预测基准上的表现与最先进的单变量模型一样好。TSMixer 通过深入了解交叉变量和辅助信息在现实场景中的重要性,为时间序列预测架构的开发创造了新的可能性。实证结果强调了在未来的研究中需要考虑更现实的多变量预测模型基准。我们希望这项工作能够激发时间序列预测领域的进一步探索,并开发出更强大、更有效的模型,这些模型可以应用于实际应用。
致谢
这项研究由 Si-An Chen、Chun-Liang Li、Nate Yoder、Sercan O. Arik 和 Tomas Pfister 进行。
评论