我们周围世界不断变化的性质对 AI 模型的开发提出了重大挑战。通常,模型是在纵向数据上进行训练的,希望所使用的训练数据能够准确地代表模型未来可能收到的输入。更一般地说,所有训练数据都同样相关的默认假设在实践中经常被打破。例如,下图显示了来自 CLEAR非平稳学习基准的图像,它说明了物体的视觉特征在 10 年的时间跨度内如何发生显著变化(我们称之为缓慢概念漂移的现象),这对物体分类模型提出了挑战。
来自 CLEAR 基准的样本图像。(改编自 Lin 等人)
替代方法(例如在线和持续学习)使用少量最新数据反复更新模型,以使其保持最新状态。这隐含地优先考虑最新数据,因为从过去数据中学习到的知识会逐渐被后续更新抹去。然而,在现实世界中,不同类型的信息以不同的速度失去相关性,因此存在两个关键问题:1) 从设计上讲,它们只关注最新数据,并会丢失任何被抹去的旧数据的信号。2)无论数据的内容如何,数据实例的贡献都会随着时间的推移均匀衰减。
在我们最近的作品“非平稳学习的实例条件衰减时间尺度”中,我们建议在训练期间为每个实例分配一个重要性分数,以最大限度地提高模型在未来数据上的性能。为了实现这一点,我们使用了一个辅助模型,该模型使用训练实例及其年龄来生成这些分数。该模型与主模型联合学习。我们解决了上述两个挑战,并在一系列非平稳学习基准数据集上取得了比其他稳健学习方法更显著的进步。例如,在最近的一个非平稳学习大规模基准测试(10 年内约 3900 万张照片)中,我们通过学习重新加权训练数据,实现了高达 15% 的相对准确率提升。
监督学习中概念漂移的挑战
为了定量了解缓慢概念漂移,我们根据近期的照片分类任务构建了分类器,该任务包含 10 年期间来自社交媒体网站的大约 3900 万张照片。我们比较了离线训练(以随机顺序多次迭代所有训练数据)和持续训练(按连续(时间)顺序多次迭代每个月的数据)。我们测量了训练期间和后续期间的模型准确率,随后两个模型都处于冻结状态,即不再根据新数据进行更新(如下所示)。在训练期结束时(左图,x 轴 = 0),两种方法都看到了相同数量的数据,但性能差距很大。这是由于灾难性遗忘造成的,这是持续学习中的一个问题,模型对训练序列早期数据的了解会以不受控制的方式减少。另一方面,遗忘也有其优势——在测试期间(如右图所示),持续训练模型的退化速度比离线模型慢得多,因为它不太依赖旧数据。测试期间两种模型的准确率下降证实了数据确实在随着时间的推移而变化,并且两种模型的相关性都变得越来越低。
在照片分类任务中比较离线和持续训练的模型。
对训练数据进行时间敏感的重新加权
我们设计了一种方法,结合离线学习(有效重复使用所有可用数据的灵活性)和持续学习(淡化旧数据的能力)的优势来解决缓慢的概念漂移问题。我们以离线学习为基础,然后仔细控制过去数据的影响并设定优化目标,这两者都旨在减少未来的模型衰减。
假设我们希望根据一段时间内收集的一些训练数据来训练模型M。 我们还建议训练一个辅助模型,该模型根据每个点的内容和年龄为其分配权重。该权重会衡量该数据点在M的训练目标中的贡献。权重的目标是提高M在未来数据上的表现。
在我们的工作中,我们描述了如何对辅助模型进行元学习,即以一种有助于模型M本身学习的方式与M一起学习。辅助模型的一个关键设计选择是,我们以分解的方式分离出与实例和年龄相关的贡献。具体来说,我们通过组合来自多个不同固定衰减时间尺度的贡献来设置权重,并学习将给定实例近似“分配”到最适合的时间尺度。我们在实验中发现,由于这种辅助模型兼具简单性和表现力,其表现优于我们考虑的许多其他替代方案,从不受约束的联合函数到单一衰减时间尺度(指数或线性)。完整详细信息可在论文中找到。
实例权重评分
下图顶部显示,我们的学习辅助模型确实在CLEAR 物体识别挑战 中增加了更多现代物体的权重;而看起来较旧的物体的权重则相应降低。仔细检查(下图,基于梯度的特征重要性评估),我们发现辅助模型专注于图像中的主要物体,而不是可能与实例年龄虚假相关的背景特征。
我们的辅助模型分别给来自CLEAR基准(相机和计算机类别)的样本图像分配了最高和最低的权重。
我们的辅助模型对来自CLEAR基准的样本图像进行特征重要性分析。
结果
大规模数据带来的收益
我们首先研究前面讨论过的YFCC100M 数据集上的 大规模照片分类任务(PCAT) ,使用前五年的数据进行训练,使用后五年的数据作为测试数据。我们的方法(下图中红色部分)比无重新加权基线(黑色)以及许多其他稳健学习技术有了显著的改进。有趣的是,我们的方法故意牺牲了遥远过去的准确度(训练数据不太可能在未来再次出现),以换取测试期的显著改进。此外,正如所期望的那样,我们的方法在测试期内的下降幅度小于其他基线。
在 PCAT 数据集上比较我们的方法和相关基线。
适用性广泛
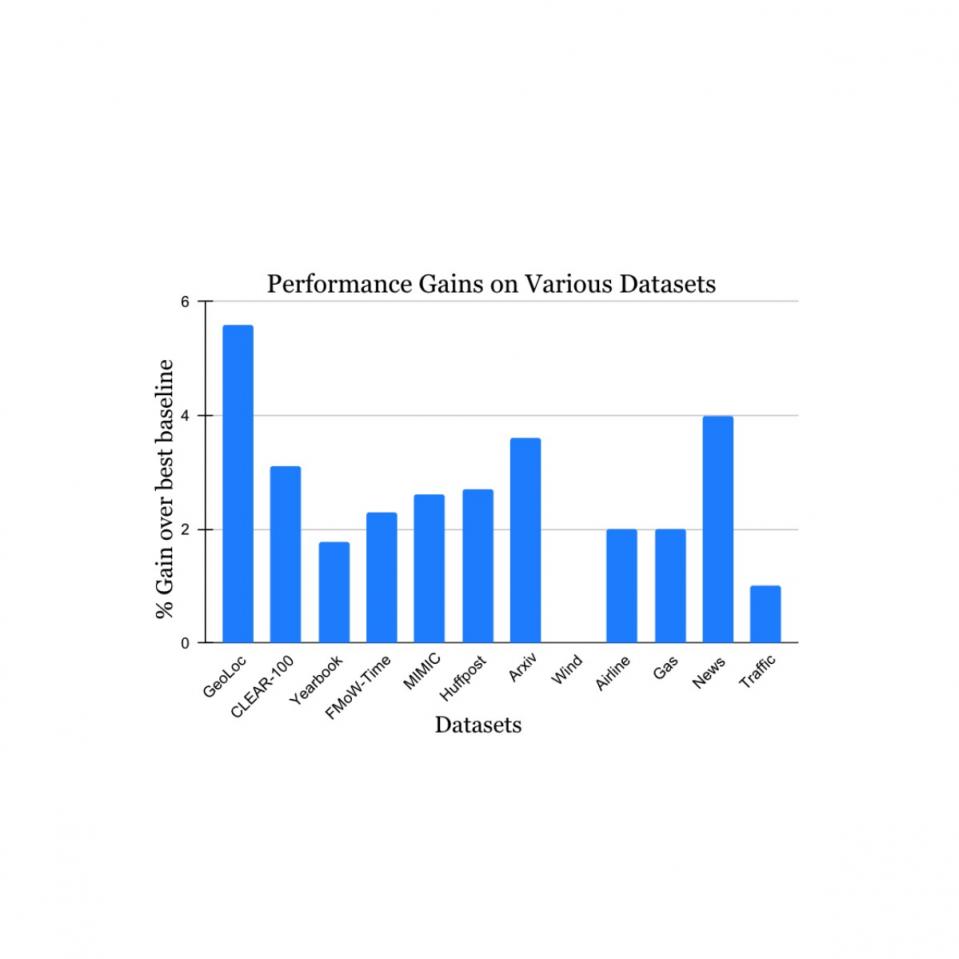
我们在来自学术文献的大量非平稳学习挑战数据集上验证了我们的发现(详情请参阅1、2、3、4 ) ,这些数据集涵盖了各种数据来源和形式(照片、卫星图像、社交媒体文本、医疗记录、传感器读数、表格数据)和大小(从 10k 到 39M 个实例)。与每个数据集最近发布的基准方法相比,我们报告了测试期间的显著收益(如下所示)。请注意,之前最著名的方法可能因每个数据集而异。这些结果展示了我们方法的广泛适用性。
我们的方法在研究自然概念漂移的各种任务上都获得了性能提升。我们报告的增益优于之前每个数据集上最知名的方法。
持续学习的扩展
最后,我们考虑了我们工作的一个有趣的扩展。上述工作描述了如何使用受持续学习启发的思想扩展离线学习以处理概念漂移。但是,有时离线学习是不可行的——例如,如果可用的训练数据量太大而无法维护或处理。我们通过在用于顺序更新模型的每个数据桶的上下文中应用时间重新加权,以直接的方式调整了我们的方法以适应持续学习。该提议仍然保留了持续学习的一些局限性,例如,模型更新仅针对最新数据执行,并且所有优化决策(包括我们的重新加权)仅针对该数据进行。尽管如此,我们的方法在照片分类基准上始终优于常规持续学习以及各种其他持续学习算法(见下文)。由于我们的方法与此处比较的许多基线中的想法相辅相成,因此我们预计与它们结合时会获得更大的收益。
与最新的基线相比,我们的方法的结果适应了持续学习。
结论
我们结合了之前方法的优势,即离线学习可以有效地重复使用数据,而持续学习则侧重于更新的数据,从而解决了学习中数据漂移的难题。我们希望我们的工作有助于在实践中提高模型对概念漂移的鲁棒性,并激发更多兴趣和新想法来解决普遍存在的缓慢概念漂移问题。
致谢
我们感谢 Mike Mozer 在本工作早期阶段进行的许多有趣的讨论,以及在开发过程中提供的非常有用的建议和反馈。
评论