今天,我们推出 Croissant,一种适用于 ML 数据集的新元数据格式。Croissant 是由来自行业和学术界的社区共同开发的,是 MLCommons 工作的一部分。
希望重用现有数据集来训练 ML 模型的机器学习 (ML) 从业者通常会花费大量时间来理解数据、理解其组织结构或确定要使用哪个子集作为特征。事实上,花费了如此多的时间,以至于 ML 领域的进展受到一个根本障碍的阻碍:数据表示形式种类繁多。
ML 数据集涵盖了广泛的内容类型,从文本和结构化数据到图像、音频和视频。即使在涵盖相同类型内容的数据集中,每个数据集也都有独特的文件和数据格式临时安排。这一挑战降低了整个 ML 开发过程(从查找数据到训练模型)的生产力。它还阻碍了开发处理数据集所急需的工具。
数据集有通用的元数据格式,例如schema.org和DCAT。但是,这些格式是为数据发现而设计的,而不是为满足 ML 数据的特定需求而设计的,例如从结构化和非结构化来源提取和组合数据的能力、包含能够负责任地使用数据的元数据,或描述 ML 使用特征(例如定义训练、测试和验证集)。
今天,我们推出了Croissant,一种用于 ML 就绪数据集的新元数据格式。Croissant 是由来自工业界和学术界的社区共同开发的,是MLCommons工作的一部分。Croissant 格式不会改变实际数据的表示方式(例如,图像或文本文件格式)——它提供了一种描述和组织数据的标准方法。Croissant 以schema.org为基础,schema.org 是发布 Web 结构化数据的事实标准,已有超过 4000 万个数据集使用该标准。Croissant 为 ML 相关元数据、数据资源、数据组织和默认 ML 语义提供了全面的层。
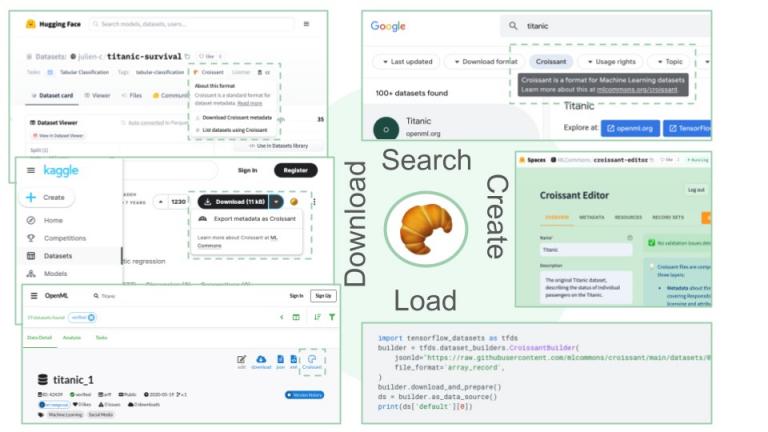
此外,我们还宣布了来自主要工具和存储库的支持:今天,三个广泛使用的 ML 数据集集合—— Kaggle、Hugging Face和OpenML——将开始支持它们托管的数据集的 Croissant 格式;数据集搜索工具允许用户在 Web 上搜索 Croissant 数据集;流行的 ML 框架,包括TensorFlow、PyTorch和JAX ,可以使用TensorFlow 数据集(TFDS)包轻松加载 Croissant 数据集。
羊角面包
Croissant 1.0 版本包含完整的格式规范、一组示例数据集、一个用于验证、使用和生成 Croissant 元数据的开源Python 库,以及一个用于以直观的方式加载、检查和创建 Croissant 数据集描述的开源可视化编辑器。
从一开始,支持负责任的人工智能 (RAI) 就是 Croissant 工作的一个主要目标。我们还发布了Croissant RAI 词汇扩展的第一个版本,它为 Croissant 增加了描述重要 RAI 用例所需的关键属性,例如数据生命周期管理、数据标签、参与式数据、ML 安全性和公平性评估、可解释性和合规性。
为什么要采用 ML 数据共享格式?
大部分机器学习工作其实都是数据工作。训练数据是决定模型行为的“代码”。数据集可以是用于训练大型语言模型 (LLM) 的文本集合,也可以是用于训练汽车防撞系统的驾驶场景 (带注释的视频) 集合。但是,开发机器学习模型的步骤通常遵循相同的以数据为中心的迭代过程:(1) 查找或收集数据,(2) 清理和优化数据,(3) 在数据上训练模型,(4) 在更多数据上测试模型,(5) 发现模型不起作用,(6) 分析数据以找出原因,(7) 重复,直到获得可行的模型。由于缺乏通用格式,许多步骤变得更加困难。这种“数据开发负担”对于资源有限的研究和早期创业工作来说尤其沉重。
Croissant 等格式的目标是让整个过程更加简单。例如,搜索引擎和数据集存储库可以利用元数据来更轻松地找到正确的数据集。数据资源和组织信息使开发用于清理、优化和分析数据的工具变得更加容易。这些信息和默认的 ML 语义使 ML 框架能够使用数据以最少的代码来训练和测试模型。这些改进共同大大减轻了数据开发负担。
此外,数据集作者关心数据集的可发现性和易用性。采用 Croissant 可以提高数据集的价值,同时只需付出很少的努力,这要归功于可用的创建工具和 ML 数据平台的支持。
Croissant 今天能做什么呢?
Croissant1-概览英雄
Croissant 生态系统:用户可以搜索 Croissant 数据集,从主要存储库下载它们,并轻松将它们加载到他们最喜欢的 ML 框架中。他们可以使用 Croissant 编辑器创建、检查和修改 Croissant 元数据。
目前,用户可以在以下位置找到 Croissant 数据集:
Google数据集搜索,提供 Croissant 过滤器。
拥抱脸
卡格勒
开放机器学习
使用 Croissant 数据集,可以:
通过TensorFlow 数据集轻松提取数据,以便在TensorFlow、PyTorch和JAX等流行的 ML 框架中使用。
使用Croissant 编辑器 UI(github )检查和修改元数据。
要发布 Croissant 数据集,用户可以:
使用Croissant 编辑器 UI(github)通过分析用户提供的数据自动生成大部分 Croissant 元数据,并填充重要的元数据字段,例如 RAI 属性。
将 Croissant 信息作为其数据集网页的一部分发布,以使其可被发现和重复使用。
将他们的数据发布在支持 Croissant 的存储库之一,例如 Kaggle、HuggingFace 和 OpenML,并自动生成 Croissant 元数据。
未来方向
我们对 Croissant 帮助 ML 从业者的潜力感到兴奋,但要让这种格式真正有用,需要社区的支持。我们鼓励数据集创建者考虑提供 Croissant 元数据。我们鼓励托管数据集的平台提供 Croissant 文件供下载,并将 Croissant 元数据嵌入数据集网页中,以便数据集搜索引擎可以发现它们。帮助用户使用 ML 数据集的工具(例如标记或数据分析工具)也应考虑支持 Croissant 数据集。我们可以共同减轻数据开发负担,并实现更丰富的 ML 研究和开发生态系统。
我们鼓励社区与我们一起为此做出贡献。
致谢
Croissant 由 Google 的Dataset Search、 Kaggle和 TensorFlow Datasets团队开发,是MLCommons社区工作组的一部分 ,该工作组还包括来自以下组织的贡献者:拜耳、cTuning 基金会、DANS-KNAW、Dotphoton、哈佛、Hugging Face、伦敦国王学院、LIST、Meta、NASA、北卡罗来纳州立大学、开放数据研究所、加泰罗尼亚开放大学、Sage Bionetworks 和埃因霍温理工大学。
评论