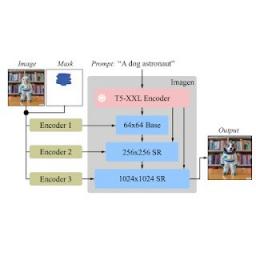
Imagen Editor 和 EditBench:推进和评估文本引导的图像修复
在过去的几年中,文本到图像生成研究取得了大量突破(尤其是Imagen、Parti、DALL-E 2等),这些突破自然而然地渗透到了相关主题中。具体来说,文本引导的图像编辑 (TGIE) 是一项实用的任务,它涉及编辑生成和拍摄的视觉效果,而不...
在过去的几年中,文本到图像生成研究取得了大量突破(尤其是Imagen、Parti、DALL-E 2等),这些突破自然而然地渗透到了相关主题中。具体来说,文本引导的图像编辑 (TGIE) 是一项实用的任务,它涉及编辑生成和拍摄的视觉效果,而不...
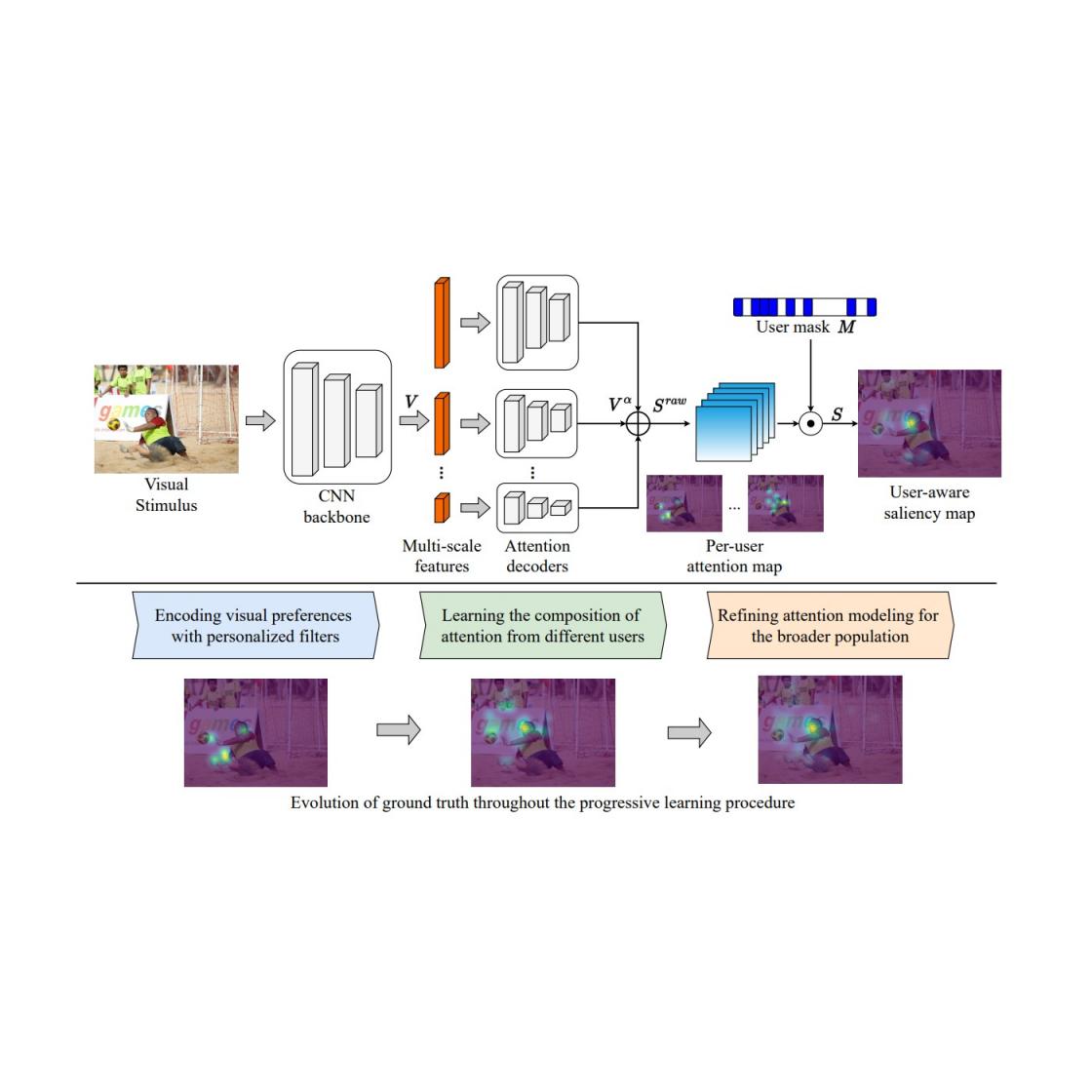
人类具有非凡的能力,能够接收大量信息(估计每秒约有 10 10比特进入视网膜),并选择性地关注一些与任务相关且有趣的区域,以便进一步处理(例如记忆、理解、行动)。因此,对人类注意力进行建模(其结果通常称为显着性模型)一直是神经科学、心理学、...

在选择地点时,我们经常会问自己以下问题:这家餐厅的氛围适合约会吗?户外座位好吗?有足够的屏幕观看比赛吗?虽然照片和视频可以部分回答这些问题,但它们无法代替身临其境的感觉,即使无法亲自前往也不行。具有交互性、照片级真实感和多维度的沉浸式体验可...

用于图像生成的大型扩散模型 的激增导致模型大小和推理工作量大幅增加。在移动环境中进行设备上的 ML 推理需要细致的性能优化,并考虑资源限制带来的权衡。在设备上运行大型扩散模型 (LDM) 的推理,出于对成本效率和用户隐私的需求,由于这些模型...
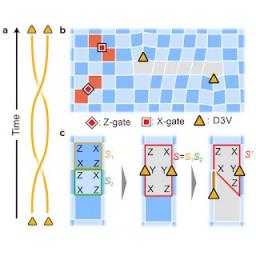
想象一下,有人向你展示了两个完全相同的物体,然后要求你闭上眼睛。当你睁开眼睛时,你会看到两个完全相同的物体,它们的位置也完全相同。你如何判断它们是否被调换了位置?直觉和量子力学定律一致:如果物体真的完全相同,就无法分辨。虽然这听起来像是常识...
Google 的AI for Social Good团队由研究人员、工程师、志愿者和其他人员组成,他们共同关注积极的社会影响。我们的使命是通过实现现实世界的价值来展示 AI 的社会效益,项目涉及公共卫生、无障碍、危机应对、气候和能源以及自然...
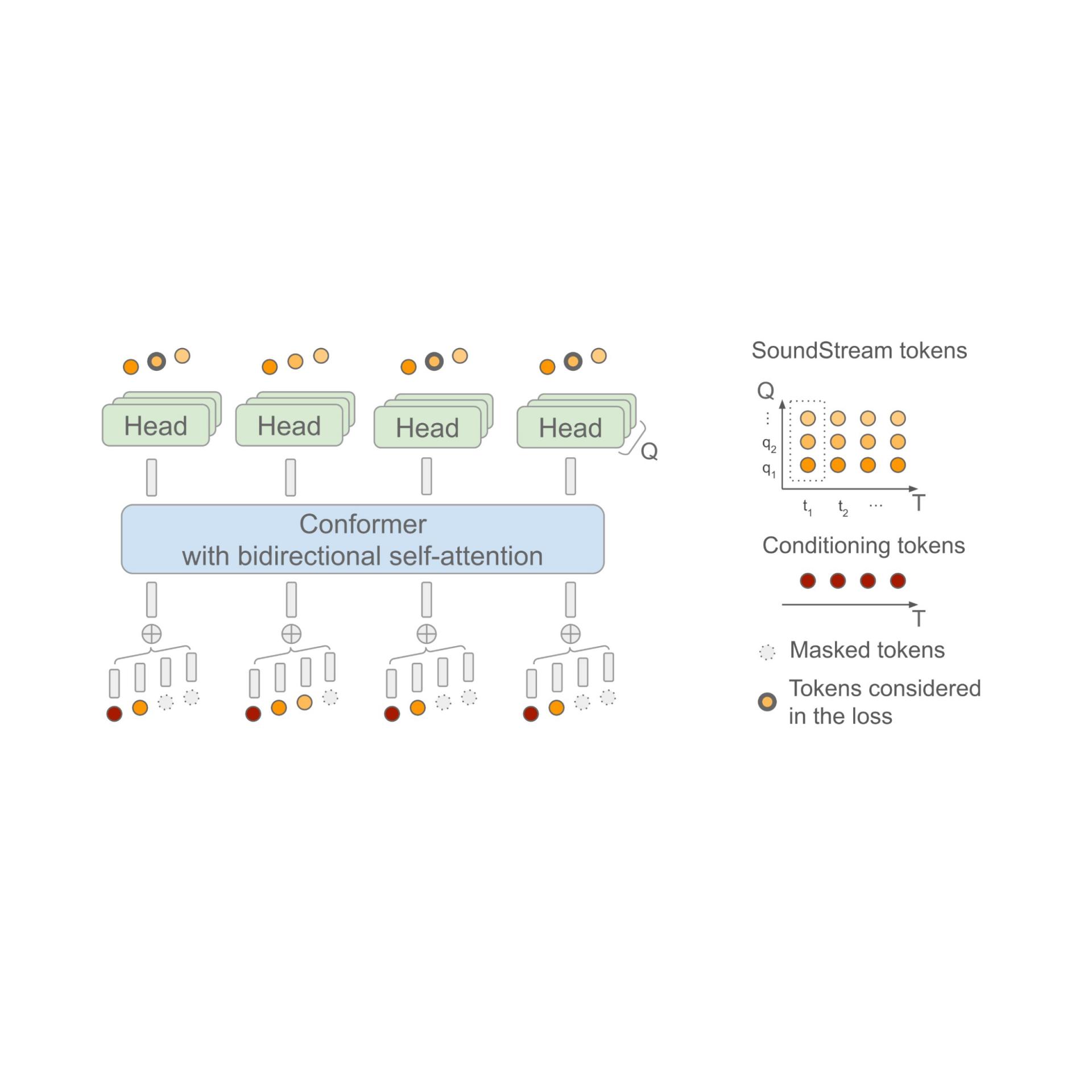
生成式 AI 的最新进展开启了在文本、视觉和音频等多个不同领域创建新内容的可能性。这些模型通常依赖于这样一个事实:原始数据首先被转换为标记序列的压缩格式。对于音频,神经音频编解码器(例如SoundStream或EnCodec)可以有效地将波...

缓存是计算机科学中一种普遍存在的概念,它通过根据请求模式将一部分热门项目存储到离客户端更近的地方,显著提高存储和检索系统的性能。缓存管理的一个重要算法是用于动态更新存储项目集的决策策略,该策略经过了几十年的广泛优化,产生了几种高效、鲁棒的启...
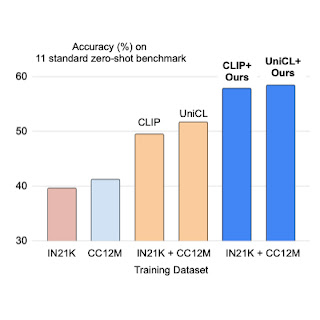
最近,在网络规模的图像标题数据集上对视觉语言 (VL) 模型进行预训练已成为传统图像分类数据预训练的有力替代方案。图像标题数据集被认为更“开放领域”,因为它们包含更广泛的场景类型和词汇,这使得模型在少样本和零样本识别任务中表现优异。然而,具...
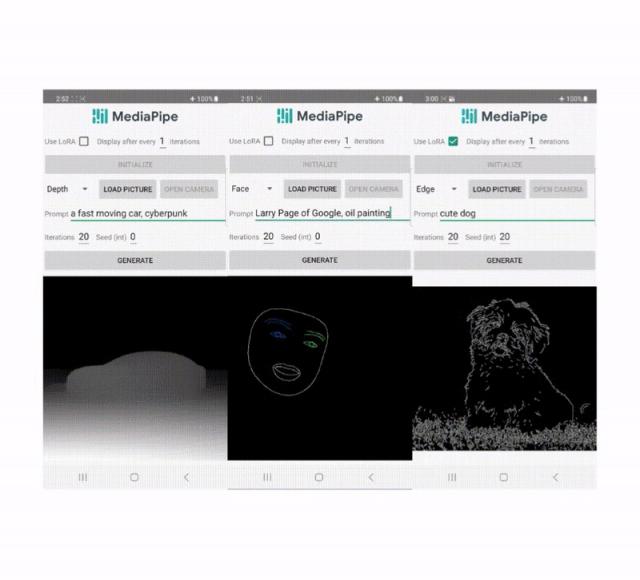
近年来,扩散模型在文本到图像的生成中取得了巨大成功,实现了高图像质量、提升了推理性能,并拓展了我们的创作灵感。然而,有效控制生成仍然具有挑战性,特别是在难以用文字描述的条件下。今天,我们发布了MediaPipe扩散插件,该插件支持在设备上运...