最近,在网络规模的图像标题数据集上对视觉语言 (VL) 模型进行预训练已成为传统图像分类数据预训练的有力替代方案。图像标题数据集被认为更“开放领域”,因为它们包含更广泛的场景类型和词汇,这使得模型在少样本和零样本识别任务中表现优异。然而,具有细粒度类别描述的图像可能很少见,而且由于图像标题数据集未经过人工管理,类别分布可能不平衡。相比之下,大规模分类数据集(如ImageNet)通常是经过管理的,因此可以提供具有平衡标签分布的细粒度类别。虽然听起来很有希望,但直接结合标题和分类数据集进行预训练往往不会成功,因为它可能导致有偏见的表示,而这些表示不能很好地推广到各种下游任务。
在CVPR 2023上发表的 “前缀条件统一语言和标签监督”中,我们展示了一种使用分类和标题数据集来提供互补优势的预训练策略。首先,我们表明,单纯地统一数据集会导致下游零样本识别任务的性能不佳,因为模型会受到数据集偏差的影响:每个数据集中图像域和词汇的覆盖范围是不同的。我们在训练期间通过前缀条件解决了这个问题,这是一种新颖的简单有效的方法,它使用前缀标记将数据集偏差与视觉概念区分开来。这种方法使语言编码器可以从两个数据集中学习,同时还可以根据每个数据集定制特征提取。前缀条件是一种通用方法,可以轻松集成到现有的 VL 预训练目标中,例如对比语言-图像预训练(CLIP) 或统一对比学习(UniCL)。
高层理念
我们注意到,分类数据集至少在两个方面存在偏差:(1) 图像大多包含来自受限域的单个对象,(2) 词汇量有限,缺乏零样本学习所需的语言灵活性。例如,针对 ImageNet 优化的“一张狗的照片”类嵌入通常会导致从 ImageNet 数据集中提取的图像中心出现一只狗的照片,这不能很好地推广到包含不同空间位置的多只狗的图像或一只狗与其他主题的图像的其他数据集。
相比之下,字幕数据集包含更广泛的场景类型和词汇。如下所示,如果模型只是从两个数据集中学习,语言嵌入可能会将图像分类和字幕数据集的偏差混杂在一起,从而降低零样本分类的泛化能力。如果我们能够解开两个数据集的偏差,我们就可以使用针对字幕数据集量身定制的语言嵌入来提高泛化能力。
顶部:语言嵌入纠缠了图像分类和标题数据集中的偏差。底部:语言嵌入解开了两个数据集中的偏差。
前缀条件作用
前缀条件作用部分地受到了即时调优的启发,即时调优将可学习的标记添加到输入标记序列的前面,以指示预训练的模型主干学习可用于解决下游任务的特定于任务的知识。前缀条件作用方法与即时调优有两点不同:(1)它旨在通过解开数据集偏差来统一图像标题和分类数据集;(2)它应用于 VL 预训练,而标准即时调优用于微调模型。前缀条件作用是一种根据用户提供的数据集类型专门控制模型主干行为的明确方法。当提前知道不同类型的数据集的数量时,这在生产中尤其有用。
在训练过程中,前缀条件作用会学习每种数据集类型的文本标记(前缀标记),从而吸收数据集的偏差,并允许剩余的文本标记专注于学习视觉概念。具体来说,它会将每种数据集类型的前缀标记添加到输入标记之前,从而告知语言和视觉编码器输入数据类型(例如,分类与标题)。前缀标记经过训练可以学习特定于数据集类型的偏差,这使我们能够在语言表示中解开这种偏差,并在测试期间利用在图像标题数据集上学习到的嵌入,即使没有输入标题。
我们利用语言和视觉编码器对 CLIP 进行前缀调节。在测试期间,我们使用用于图像标题数据集的前缀,因为该数据集应该涵盖更广泛的场景类型和词汇,从而提高零样本识别的性能。
前缀条件作用的说明。
实验结果
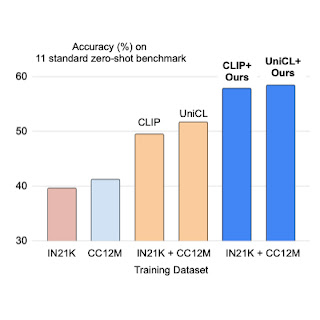
我们对两种对比损失( CLIP和UniCL) 应用前缀条件,并与使用ImageNet21K (IN21K) 和Conceptual 12M (CC12M)训练的模型相比,评估它们在零样本识别任务上的表现。使用前缀条件用两个数据集训练的 CLIP 和 UniCL 模型在零样本分类准确率方面表现出了巨大的提升。
仅使用 IN21K 或 CC12M 训练的模型的零样本分类准确度,与使用前缀条件对两个数据集进行训练的 CLIP 和 UniCL 模型(“我们的”)相比。
考试时间前缀研究
下表描述了测试期间使用前缀的性能变化。我们证明,通过使用与分类数据集相同的前缀(“Prompt”),分类数据集(IN-1K)上的性能会有所提高。当使用与图像标题数据集相同的前缀(“Caption”)时,其他数据集(Zero-shot AVG)上的性能会有所提高。此分析表明,如果前缀针对图像标题数据集量身定制,则可以更好地泛化场景类型和词汇。
分析测试时使用的前缀。
图像分布偏移鲁棒性研究
我们使用 ImageNet 变体研究了图像分布的变化。我们发现“Caption”前缀在ImageNet-R (IN-R) 和ImageNet-Sketch (IN-S) 中的表现优于“Prompt”,但在ImageNet-V2 (IN-V2)中表现不佳。这表明“Caption”前缀在远离分类数据集的域上实现了泛化。因此,最佳前缀可能因测试域与分类数据集的距离而异。
对图像级分布偏移的鲁棒性分析。IN:ImageNet,IN-V2:ImageNet-V2,IN-R:艺术、卡通风格 ImageNet,IN-S:ImageNet Sketch。
结论和未来工作
我们引入了前缀条件,这是一种统一图像标题和分类数据集以实现更好的零样本分类的技术。我们表明,这种方法可以提高零样本分类准确率,并且前缀可以控制语言嵌入中的偏差。一个限制是,在标题数据集上学习到的前缀不一定是零样本分类的最佳前缀。确定每个测试数据集的最佳前缀是未来工作的一个有趣方向。
致谢
这项研究由 Kuniaki Saito、Kihyuk Sohn、Xiang Zhang、Chun-Liang Li、Chen-Yu Lee、Kate Saenko 和 Tomas Pfister 进行。感谢 Zizhao Zhang 和 Sergey Ioffe 提供的宝贵反馈。
评论