Google 的AI for Social Good团队由研究人员、工程师、志愿者和其他人员组成,他们共同关注积极的社会影响。我们的使命是通过实现现实世界的价值来展示 AI 的社会效益,项目涉及公共卫生、无障碍、危机应对、气候和能源以及自然和社会等领域。我们认为,推动服务不足社区发生积极变化的最佳方式是与变革者及其所服务的组织合作。
在这篇博文中,我们讨论了AI for Social Good团队Project Euphonia所做的工作,该团队旨在提高针对言语障碍人士的自动语音识别(ASR) 能力。对于具有正常言语能力的人,ASR 模型的词错误率 (WER) 可以低于 10%。但对于言语障碍人士,例如口吃、构音障碍和失用症,WER 可能达到 50% 甚至 90%,具体取决于病因和严重程度。为了帮助解决这个问题,我们与 1,000 多名参与者合作,收集了 1,000 多个小时的言语障碍样本,并使用这些数据表明 ASR个性化是弥合言语障碍用户表现差距的可行途径。我们已经证明, 使用层冻结技术,只需3-4 分钟的训练语音即可成功实现个性化。
这项工作促成了Project Relate的开发 ,该项目旨在为所有言语异常、可从个性化语音模型中受益的人提供帮助。Project Relate 与Google 语音团队合作开发,可帮助那些难以被他人和技术理解的人训练自己的模型。人们可以使用这些个性化模型更有效地沟通并获得更大的独立性。为了使 ASR 更易于访问和使用,我们描述了如何微调 Google 的通用语音模型(USM),使其能够更好地理解开箱即用的混乱语音,无需个性化,即可与数字助理技术、听写应用和对话配合使用。
应对挑战
通过与 Project Relate 用户的密切合作,我们发现个性化模型非常有用,但对于许多用户来说,记录数十或数百个示例可能具有挑战性。此外,个性化模型在自由形式的对话中并不总是表现良好。
为了应对这些挑战,Euphonia 的研究工作一直专注于独立于说话人的ASR(SI-ASR),以使模型能够为言语障碍人士提供更好的开箱即用服务,而无需进行额外的训练。
SI-ASR 的提示语音数据集
构建强大的 SI-ASR 模型的第一步是创建具有代表性的数据集分割。我们将Euphonia 语料库分割为训练、验证和测试部分,从而创建了 Prompted Speech 数据集,同时确保每个分割涵盖一系列言语障碍严重程度和潜在病因,并且不会有说话者或短语出现在多个分割中。训练部分包含来自 1,000 多名言语障碍说话者的 950,000 多条言语。测试集包含来自 350 多名说话者的约 5,700 条言语。语言病理学家手动审查了测试集中的所有言语,以确保转录准确性和音频质量。
真实对话测试集
无提示或对话式的语音与提示式的语音在多个方面有所不同。在对话中,人们说话更快,发音更少。他们会重复单词、纠正说错的单词,并使用更广泛的词汇,这些词汇是他们自己和他们所在社区特有的。为了改进此用例的模型,我们创建了真实对话测试集来对性能进行基准测试。
真实对话测试集是在值得信赖的测试人员的帮助下创建的,这些测试人员录制了自己在对话过程中的讲话。审查了音频,删除了任何个人身份信息 (PII),然后语言病理学家将这些数据转录成文字。真实对话测试集包含 29 位说话者的 1,500 多条话语。
使 USM 适应语音混乱
然后,我们在 Euphonia Prompted Speech 集的训练分割上调整了 USM,以提高其在无序语音上的表现。我们的调整不是对整个模型进行微调,而是基于残差适配器,这是一种参数高效的调整方法,它在变压器层之间添加可调瓶颈层作为残差。只有这些层经过调整,而其余模型权重保持不变。我们之前已经证明,这种方法非常适用于使 ASR 模型适应无序语音。残差适配器仅添加到编码器层,瓶颈维度设置为 64。
结果
为了评估改进后的 USM,我们使用上述两个测试集将其与旧版 ASR 模型进行了比较。对于每项测试,我们将改进后的 USM 与最适合该任务的 USM 之前的模型进行比较:(1) 对于简短的提示语音,我们将其与针对简短 ASR 优化的 Google 生产 ASR 模型进行比较;(2) 对于较长的真实对话语音,我们将其与针对长篇 ASR 训练的模型进行比较。USM 相对于 USM 之前的模型的改进可以通过 USM 的相对大小增加、120M 到 2B 的参数以及USM 博客文章中讨论的其他改进来解释。
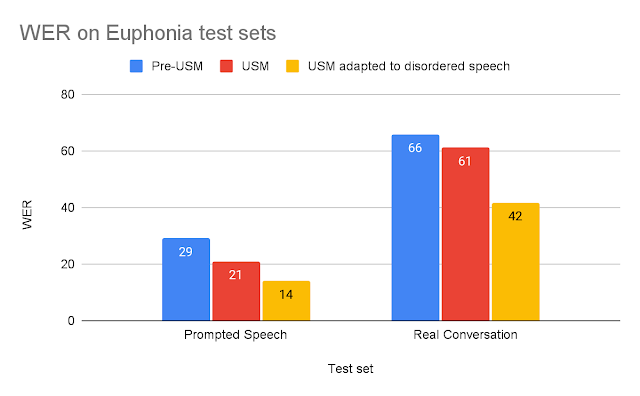
为每个测试集建模词错误率(WER)(越低越好)。
我们发现,针对无序语音进行调整的 USM 的表现明显优于其他模型。调整后的 USM 在真实对话中的 WER 比 USM 之前的模型高出 37%,而在提示语音测试集上,调整后的 USM 的表现高出 53%。
这些发现表明,经过调整的 USM 对患有语言障碍的最终用户来说更加实用。我们可以通过查看 Euphonia 和 Project Relate 的可靠测试人员的真实对话测试集录音记录来证明这一改进(见下文)。
音频1
地面实况 USM 之前的 ASR 改良型 USM
我的腿上现在有一个 Xbox 自适应控制器。 我现在有很多事情要做,而且那个顾问对我的嘴 我的灯上现在有一个 xbox适配器控制器。
我已经说了好一会儿了。让我们看看。 已经有一段时间了 我已经讲了好一会儿了。
来自真实对话测试集的可信测试人员的语音的示例音频和转录。
对 USM 预科成绩单和改编后的 USM 成绩单进行比较,可以发现一些主要优势:
第一个例子表明,Adapted USM 在识别混乱的语音模式方面表现更好。基线遗漏了“XBox”和“控制器”等关键词,而这些关键词对于听众理解他们想要表达的意思至关重要。
第二个例子很好地说明了缺失是未使用混乱语音进行训练的 ASR 模型的主要问题。虽然基线模型确实正确地转录了一部分,但大部分话语都没有转录,从而丢失了说话者的本意。
结论
我们相信这项工作是让患有语言障碍的人更容易获得语音识别的重要一步。我们将继续努力提高模型的性能。随着 ASR 的快速发展,我们的目标是确保患有语言障碍的人也能从中受益。
致谢
该项目的主要贡献者包括 Fadi Biadsy、Michael Brenner、Julie Cattiau、Richard Cave、Amy Chung-Yu Chou、Dotan Emanuel、Jordan Green、Rus Heywood、Pan-Pan Jiang、Anton Kast、Marilyn Ladewig、Bob MacDonald、Philip Nelson、Katie Seaver、Joel Shor、Jimmy Tobin、Katrin Tomanek 和 Subhashini Venugopalan。我们非常感谢 USM 研究团队成员对 Euphonia 项目的支持,包括 Yu Zhang、Wei Han、Nanxin Chen 等。最重要的是,我们要向录制语音样本的 2,200 多名参与者以及帮助我们与这些参与者建立联系的众多倡导团体表示衷心的感谢。
评论