在过去的几年中,文本到图像生成研究取得了大量突破(尤其是Imagen、Parti、DALL-E 2等),这些突破自然而然地渗透到了相关主题中。具体来说,文本引导的图像编辑 (TGIE) 是一项实用的任务,它涉及编辑生成和拍摄的视觉效果,而不是完全重做它们。当重新创建视觉效果耗时或不可行时(例如,调整度假照片中的物体或完善从头开始生成的可爱小狗的细粒度细节),快速、自动化且可控的编辑是一种方便的解决方案。此外,TGIE 为改进基础模型本身的训练提供了巨大机会。多模态模型需要多样化的数据才能正确训练,而 TGIE 编辑可以生成和重新组合高质量、可扩展的合成数据,或许最重要的是,它可以提供优化训练数据沿任何给定轴分布的方法。
在CVPR 2023上展示的 “ Imagen Editor 和 EditBench:文本引导的图像修复技术的推进和评估”中,我们介绍了Imagen Editor ,这是用于蒙版修复任务的最先进的解决方案— — 即,当用户在覆盖层或“蒙版”(通常在绘图类型界面内生成)旁边提供文本指令,指示他们想要修改的图像区域。我们还介绍了EditBench,一种衡量图像编辑模型质量的方法。EditBench 超越了常用的粗粒度“此图像是否与此文本匹配”方法,并深入到各种类型的属性、对象和场景,以更细粒度地了解模型性能。特别是,它非常强调图像与文本对齐的忠实度,同时又不忽视图像质量。
给定一张图片、用户定义的蒙版和文本提示,Imagen Editor 会对指定区域进行局部编辑。该模型有意义地融入了用户的意图并执行逼真的编辑。
图像编辑器
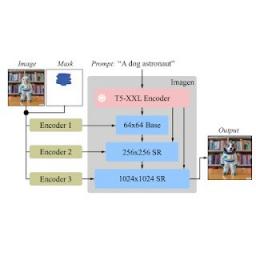
Imagen Editor 是一个基于扩散的模型,在Imagen上进行了微调,用于编辑。它的目标是改进语言输入的表示、细粒度控制和高保真输出。Imagen Editor 从用户那里获取三个输入:1) 要编辑的图像、2) 用于指定编辑区域的二进制掩码和 3) 文本提示 — 所有三个输入都会指导输出样本。
Imagen Editor 依赖于三种核心技术来实现高质量的文本引导图像修复。首先,与之前应用随机框和笔划蒙版的修复模型(例如Palette、Context Attention、Gated Convolution )不同,Imagen Editor 采用对象检测器蒙版策略,其中的对象检测器模块在训练期间生成对象蒙版。对象蒙版基于检测到的对象而不是随机斑块,并允许编辑文本提示和蒙版区域之间进行更有原则的对齐。从经验上讲,该方法有助于模型避免当蒙版区域较小或仅部分覆盖对象(例如CogView2 )时文本提示被忽略的普遍问题。
随机蒙版(左)经常捕捉背景或与物体边界相交的区域,定义仅从图像上下文中就可以合理修复的区域。仅从图像上下文中修复物体蒙版(右)更困难,这促使模型在训练期间更多地依赖文本输入。
接下来,在训练和推理过程中,Imagen Editor 通过以全分辨率(本研究中为 1024×1024)为条件、按通道连接输入图像和蒙版(类似于SR3、Palette和GLIDE)来增强高分辨率编辑。对于基本扩散 64×64 模型和 64×64→256×256 超分辨率模型,我们应用参数化下采样卷积(例如,带步长的卷积),我们根据经验发现这对于高保真度至关重要。
Imagen 针对图像编辑进行了微调。所有扩散模型(即基础模型和超分辨率 (SR) 模型)均以高分辨率 1024×1024 图像和掩码输入为条件。为此,引入了新的卷积图像编码器。
最后,在推理时,我们应用无分类器指导(CFG) 将样本偏向特定条件,在本例中为文本提示。CFG 在文本条件和非条件模型预测之间进行插值,以确保生成的图像与输入文本提示之间在文本引导的图像修复中具有很强的对齐性。我们遵循Imagen Video并使用具有指导振荡(在指导权重的值范围内振荡的指导计划)的高指导权重。在基础模型(阶段 1 64x 扩散)中,确保与文本的强对齐最为关键,我们使用在 1 到 30 之间振荡的指导权重计划。我们观察到,高指导权重与振荡指导相结合可在样本保真度和文本-图像对齐之间实现最佳权衡。
編輯工作台
EditBench 文本引导图像修复评估数据集包含 240 幅图像,其中 120 幅为生成图像,120 幅为自然图像。生成的图像由Parti合成,自然图像则来自Visual Genome和Open Images数据集。EditBench 可捕获各种语言、图像类型和文本提示特异性级别(即简单、丰富和完整字幕)。每个示例均包含 (1) 一张蒙版输入图像、(2) 一个输入文本提示和 (3) 一张用作自动指标参考的高质量输出图像。为了深入了解不同模型的相对优势和劣势,EditBench 提示旨在测试三个类别的细粒度细节:(1) 属性(例如材质、颜色、形状、大小、数量);(2) 对象类型(例如常见、罕见、文本渲染);和 (3) 场景(例如室内、室外、逼真或绘画)。为了了解不同规范的提示如何影响模型性能,我们提供了三种文本提示类型:单属性(Mask Simple)或蒙版对象的多属性描述(Mask Rich)——或整个图像描述(Full Image)。特别是 Mask Rich,可以探测模型处理复杂属性绑定和包含的能力。
完整图像可作为成功修复的参考。蒙版以自由形式、无提示形状覆盖目标对象。我们评估了 Mask Simple、Mask Rich 和 Full Image 提示,与传统的文本转图像模型一致。
由于现有的 TGIE 自动评估指标(CLIPScore和CLIP-R-Precision)存在内在缺陷,我们将人工评估作为 EditBench 的黄金标准。在以下部分中,我们将演示如何将 EditBench 应用于模型评估。
评估
我们对带有对象掩蔽 (IM) 和随机掩蔽 (IM-RM) 的 Imagen Editor 模型与同类模型Stable Diffusion (SD) 和DALL-E 2 (DL2) 进行了评估。Imagen Editor 在所有 EditBench 评估类别中的表现均远超这些模型。
对于完整图像提示,单幅图像人工评估提供二元答案以确认图像是否与标题匹配。对于 Mask Simple 提示,单幅图像人工评估确认对象和属性是否正确呈现并正确绑定(例如,对于红猫,红桌子上的白猫将是错误的绑定)。并排人工评估仅使用 Mask Rich 提示在 IM 与其他三个模型(IM-RM、DL2 和 SD)之间进行并排比较,并指出哪幅图像与标题更匹配以进行文本图像对齐,以及哪幅图像最逼真。
人工评估。全图提示引出了注释者对文本-图像对齐的整体印象;Mask Simple 和 Mask Rich 检查特定属性、对象和属性绑定是否正确包含。
对于单幅图像的人工评估,IM 获得了全场最高评分(比排名第二的模型高出 10-13%)。对于其余模型,性能顺序为 IM-RM > DL2 > SD(相差 3-6%),但 Mask Simple 除外,IM-RM 落后 4-8%。由于 Full 和 Mask Rich 涉及的语义内容相对较多,我们推测 IM-RM 和 IM 受益于性能更高的T5 XXL文本编码器。
按提示类型对 EditBench 上的文本引导图像修复进行单图像人工评估。对于 Mask Simple 和 Mask Rich 提示,如果编辑的图像准确包含提示中指定的每个属性和对象(包括正确的属性绑定),则文本图像对齐是正确的。请注意,由于评估设计不同(完整提示与仅 Mask 提示),结果不太直接可比。
EditBench 专注于细粒度注释,因此我们评估了对象和属性类型的模型。对于对象类型,IM 在所有类别中均处于领先地位,在常见、罕见和文本渲染方面的表现比排名第二的模型高出 10-11%。
EditBench Mask Simple 上按对象类型进行的单幅图像人工评估。作为一个群体,模型在对象渲染方面比文本渲染方面表现更好。
对于属性类型,IM 的评级比表现第二好的模型高得多(13-16%),但计数除外,其中 DL2 仅落后 1%。
EditBench Mask Simple 上的单幅图像人工评估按属性类型进行。对象掩码可全面提高对提示属性的遵守程度(IM 与 IM-RM)。
与其他模型进行一对一比较时,IM 在文本对齐方面领先优势明显,与 SD、DL2 和 IM-RM 相比,更受注释者的青睐。
在 EditBench Mask Rich 提示上对图像真实度和文本图像对齐进行并排人工评估。对于文本图像对齐,Imagen Editor 在所有比较中都更受欢迎。
最后,我们展示了所有模型的代表性并排比较。请参阅论文以获取更多示例。
Mask Simple 与 Mask Rich 提示的示例模型输出。与使用随机掩码训练的相同模型相比,对象掩码提高了 Imagen Editor 对提示的细粒度遵守。
结论
我们推出了 Imagen Editor 和 EditBench,在文本引导图像修复及其评估方面取得了重大进展。Imagen Editor 是一款基于 Imagen 进行微调的文本引导图像修复。EditBench 是一款全面的系统性文本引导图像修复基准,可评估多个维度的性能:属性、对象和场景。请注意,出于对负责任的 AI 的担忧,我们不会向公众发布 Imagen Editor。另一方面,EditBench 已完整发布,以造福研究界。
致谢
感谢 Gunjan Baid、Nicole Brichtova、Sara Mahdavi、Kathy Meier-Hellstern、Zarana Parekh、Anusha Ramesh、Tris Warkentin、Austin Waters 和 Vijay Vasudevan 的慷慨支持。我们感谢 Igor Karpov、Isabel Kraus-Liang、Raghava Ram Pamidigantam、Mahesh Maddinala 以及所有匿名人工注释者协调完成人工评估任务。我们感谢 Huiwen Chang、Austin Tarango 和 Douglas Eck 提供论文反馈。感谢 Erica Moreira 和 Victor Gomes 在资源协调方面的帮助。最后,感谢 DALL-E 2 的作者允许我们将他们的模型输出用于研究目的。
评论