过去几年,视频理解领域取得了巨大进步。例如,监督学习和强大的 深度 学习 模型可用于对视频中可能出现的多种动作进行分类,用一个标签总结整个视频片段。然而,在许多情况下,我们需要的不仅仅是整个视频片段的一个标签。例如,如果机器人正在往杯子里倒水,仅仅识别“倒液体”的动作不足以预测水何时会溢出。为此,需要逐帧跟踪杯子中倒水的量。同样,比较投手姿势的棒球教练可能希望从球离开投手手中的精确时刻检索视频帧。这样的应用需要模型来理解视频的每一帧
。 然而,应用监督学习来理解视频中的每一帧是昂贵的,因为需要视频中感兴趣的动作的每帧标签。这要求注释者通过手动为每个视频的每一帧添加明确的标签来为视频应用细粒度标签。只有这样,模型才能被训练,而且只能针对单个动作进行训练。对新动作的训练需要重复该过程。随着对细粒度标记的需求不断增加(从机器人技术到体育分析等各种应用都需要细粒度标记),这使得对可扩展学习算法的需求变得越来越迫切,这种算法可以在没有繁琐的标记过程的情况下理解视频。
我们提出了一种使用自监督学习方法的潜在解决方案,称为时间周期一致性学习(TCC)。这种新方法使用类似顺序过程的示例之间的对应关系来学习特别适合对视频进行细粒度时间理解的表示。我们还发布了我们的 TCC代码库,以使最终用户能够将我们的自监督学习算法应用于新的和新颖的应用程序。使用 TCC 进行表示学习
植物从幼苗长成大树;起床、上班和回家的日常活动;或者一个人给自己倒一杯水,都是按特定顺序发生的事件的例子。捕捉这些过程的视频提供了同一过程的多个实例之间的时间对应关系。例如,倒饮料时,人们可能伸手去拿茶壶、一瓶酒或一杯水来倒水。关键时刻是所有倒水视频的共同点(例如,第一次接触容器或将容器从地面抬起),并且独立于许多不同因素而存在,例如视点、比例、容器样式或事件速度的视觉变化。TCC 试图通过利用循环一致性原理(已成功应用于计算机 视觉中的许多问题)来在同一动作的视频中找到这种对应关系,通过对齐视频来学习有用的视觉表示。
该训练算法的目标是学习帧编码器,使用任何处理图像的网络架构,例如ResNet。为此,我们将要对齐的视频的所有帧都传递给编码器,以生成它们相应的嵌入。然后,我们选择两个视频进行 TCC 学习,比如视频 1(参考视频)和视频 2。从视频 1中选择一个参考帧,并在嵌入空间(而不是像素空间)中找到来自视频 2的最近邻帧(NN 2 )。然后,我们通过在视频 1中找到NN 2的最近邻来循环回来,我们将其称为NN 1。如果表示是循环一致的,则视频 1中的最近邻帧(NN 1)应该参考回起始参考帧。
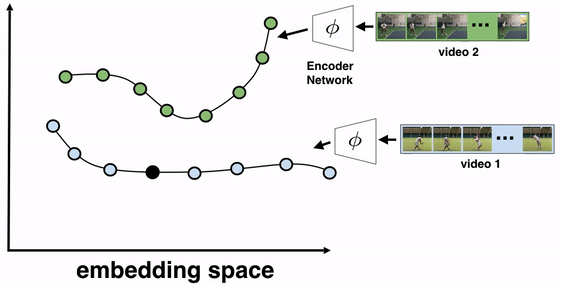
我们使用起始参考帧和NN 1之间的距离作为训练信号来训练嵌入器。随着训练的进行,嵌入通过在正在执行的操作的上下文中发展对每个视频帧的语义理解来改善并减少循环一致性损失。

使用 TCC,我们通过对齐相关视频来学习具有对动作的时间细粒度理解的嵌入。
TCC 学到了什么?
下图中,我们展示了使用 TCC 训练的模型,该模型使用来自 Penn Action Dataset的人们进行深蹲练习的视频。左侧的每个点对应于帧嵌入,突出显示的点跟踪当前视频帧的嵌入。请注意,尽管姿势、光线、身体和物体类型存在许多差异,但嵌入如何集体移动。TCC 嵌入对深蹲的不同阶段进行编码,而无需提供明确的标签。
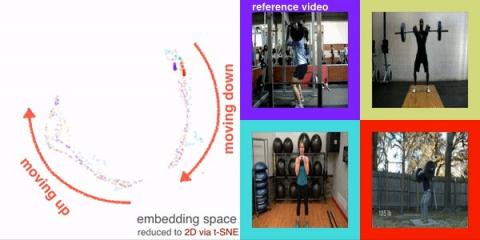
右图:输入人们进行深蹲练习的视频。左上角的视频是参考。其他视频显示来自其他人们进行深蹲的视频的最近邻帧(在 TCC 嵌入空间中)。左图:相应的帧嵌入随着动作的执行而移动。
TCC 的应用
学习到的每帧嵌入可以实现一系列有趣的应用:
少量动作阶段分类
当只有少量标记视频可用于训练时,在少量场景中,TCC 表现非常出色。事实上,TCC 只需一个标记视频就可以对不同动作的阶段进行分类。在下图中,我们将少量设置中的其他监督和自监督 学习方法进行比较。我们发现,监督学习需要大约 50 个每帧都标记的视频才能达到自监督方法仅使用一个完全标记的视频即可达到的精度。
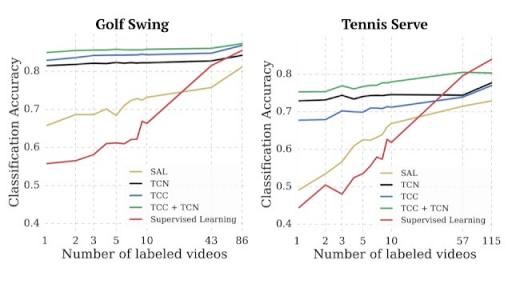
对少量动作阶段分类的自监督学习和监督学习进行比较。
无监督视频对齐
随着视频数量的增加,手动对齐或同步视频变得非常困难。使用 TCC,可以通过选择参考视频中每帧的最近邻居来对齐许多视频,而无需额外的标签,如下图所示。

使用 TCC 空间中的帧间距离对投球棒球视频进行无监督视频对齐的结果。用于对齐的参考视频显示在左上面板中。
逐帧检索
使用 TCC,视频中的每个帧都可以用作查询,通过在学习到的嵌入空间中查找最近的邻居来检索相似的帧。嵌入非常强大,可以区分看起来非常相似的帧,例如保龄球投出之前或之后的帧。

我们可以逐帧地对视频进行检索,也就是说,任何一帧都可以用来在大量视频中查找相似的帧。检索到的最近邻居表明该模型能够捕捉场景中的细粒度差异。
发布
我们正在发布我们的代码库,其中包括许多最先进的自监督学习方法的实现,包括 TCC。该代码库将对从事视频理解的研究人员以及希望使用机器学习来对齐视频以创建同步移动的人、动物和物体的马赛克的艺术家有用。
致谢
这是与 Yusuf Aytar、Jonathan Tompson、Pierre Sermanet 和 Andrew Zisserman 的合作作品。作者要感谢 Alexandre Passos、Allen Lavoie、Anelia Angelova、Bryan Seybold、Priya Gupta、Relja Arandjelović、Sergio Guadarrama、Sourish Chaudhuri 和 Vincent Vanhoucke 对这个项目的帮助。该项目中使用的视频来自PennAction数据集。我们感谢 PennAction 的创建者策划了如此有趣的数据集。
评论