技术的实用性取决于其可访问性。可访问性的一个关键组成部分是自动语音识别 (ASR),它可以极大地提高有言语障碍的人与日常智能设备交互的能力。然而,ASR 系统通常是从“典型”语音中训练出来的,这意味着代表性不足的群体(例如有言语障碍或口音很重的人)不会体验到相同程度的实用性。例如,肌萎缩侧索硬化症 (ALS) 是一种会对人的言语产生不利影响的疾病——大约 25% 的 ALS 患者会以言语不清作为其首发症状。此外,大多数 ALS 患者最终会失去行走能力,因此能够远距离与自动设备交互非常重要。然而,目前最先进的 ASR 模型可能会为仅有中度言语障碍的 ALS 患者产生较高的词错误率(WER),从而有效地阻止了依赖 ASR 的技术的使用。在即将于2019 年 Interspeech上展示的
“使用有限数据对构音障碍和带口音的语音进行个性化 ASR ”中,我们介绍了Euphonia 项目背后的一些研究,Euphonia 项目是一个执行语音到文本转录的 ASR 平台。这项工作提出了一种改善 ALS 患者 ASR 的方法,该方法也可能适用于许多其他类型的非标准语音。使用两步训练方法,首先使用基线“标准”语料库,然后使用个性化语音数据集对训练进行微调,我们已经证明,与当前最先进的模型相比,该方法对非典型语音的说话者有显著的改进。 两阶段训练方法 为了创建适用于非标准语音的 ASR 模型,需要克服两个挑战。第一个挑战是,在某一类非典型语音中,例如地区口音或言语障碍,个人可能会表现出非常不同的说话方式。我们的方法通过分两个阶段训练 ASR 模型来处理这种子群体的异质性。我们首先使用经过数千小时标准语音训练的高质量 ASR 模型,然后针对非标准语音的个人对模型的各个部分进行微调。这种方法与Parrotron的方法类似:两种系统都使用端到端神经网络来帮助改善沟通和可访问性,但 Parrotron 专注于语音到语音,即将人的语音直接转换为合成语音,而不是文本。
第二个挑战来自于难以收集足够的数据来训练最先进的个人识别器。典型的语音识别器需要用来自许多不同说话者的数千小时的语音进行训练。从单个说话者那里获取这么多数据几乎是不可能的,尤其是当说话者可能因身体状况而感到疲惫时。我们的方法克服了这个问题,首先在大量典型语音语料库上训练一个基础模型,然后使用具有目标非标准语音特征的较小数据集训练个性化模型。
神经网络架构
在开发用于训练非典型语音数据的模型时,我们探索了两种不同的神经架构。第一个是RNN-Transducer (RNN-T),这是一种由编码器和解码器网络组成的神经网络架构,在许多 ASR 任务中都表现出良好的效果。编码器是双向的(即,它一次查看整个句子以提供上下文),因此它需要整个音频样本来执行语音识别。
我们探索的另一种架构是Listen, Attend, and Spell (LAS),这是一种基于注意力机制的序列到序列模型,可将声学属性序列映射到语言序列。此模型使用编码器将声学帧序列转换为内部表征序列,并使用解码器将内部表征序列转换为语言输出。该网络生成“词片”,即字素和单词之间的语言表征。
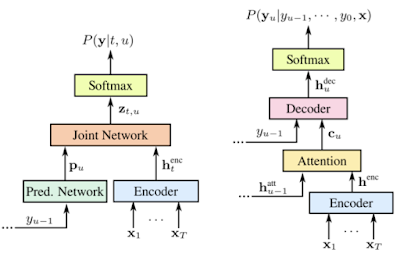
RNN-Transducer(左)和 Listen, Attend, Spell(右)架构的比较。
我们尝试在两种非标准语音上对最先进的 RNN-T 和 LAS 基础模型进行微调。我们与ALS 治疗发展研究所合作,首先收集了 67 位 ALS 患者的约 36 小时音频。参与者使用定制软件在家用电脑上录制自己阅读非常受限语言领域的句子。许多短语都是具有简单语法结构的单句(例如“今晚的篮球比赛几点开始? ”)。这与不受限制的语言领域形成对比,后者包括领域特定词汇(例如科学讲座)和复杂语言结构(例如辩论)。录音中没有包括正常语音中常见的许多填充词,例如“嗯”和“呃”。
我们还使用开源非母语L2 Arctic 数据集测试了带口音的语音,该数据集包含 20 位说话者,每位说话者大约有 1 小时的语音。每位发言者都录制了一组来自CMU Arctic 提示的 1150 条话语。
结果
语言受限测试集上的绝对单词错误率如下所示。对于非常不标准的语音(重口音和ALS 功能评分量表上低于 3 的 ALS 语音),与基线模型相比有所改进,对于与典型语音相似的 ALS 语音也有适度改进。基线模型和微调模型之间的相对差异表明,大部分改进来自微调过程,但 Arctic 数据集上的 RNN-T 除外,其中 RNN-T 基线已经很强大了。
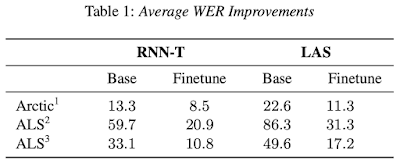
1来自 L2-Arctic 数据集的非英语母语语音。2低
FRS(ALS 功能评定量表)语音;可理解重复(FRS 2);语音与非声音交流相结合(FRS 1)。3 FRS
3;可检测到的语音障碍。
RNN-T 模型仅通过微调两层就实现了 91% 的改进,其中大部分层都接近输入。在带重音的数据集上,与微调整个网络相比,微调相同的两层实现了 86% 的相对改进。这与之前的 语音 工作一致。
大部分性能提升是在训练早期实现的。我们训练的模型是在相对有限的词汇和语言复杂度领域进行测试的,因此性能数字不一定与模型在更一般的任务上的表现有关。我们希望仅对网络的一部分进行微调就可以保留来自一般语音模型的声学和语言信息,同时只需进行最少的修改即可适应单个新说话者。未来的工作将检验这一假设。
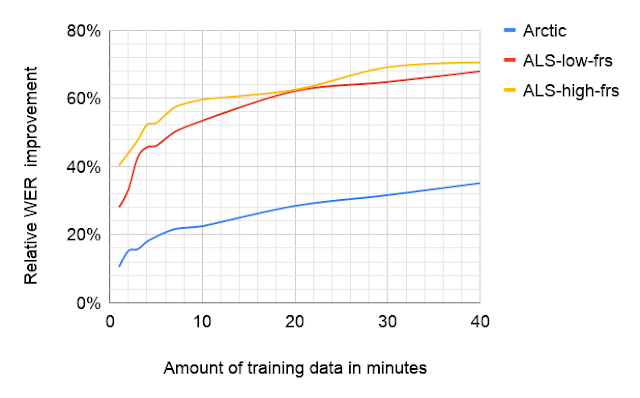
低 FRS 对应于 ALS 说话者语音清晰度较低(FRS 2, 1),而高 FRS 对应于 ALS 说话者语音影响较不严重(FRS 3)。
理解模型行为
为了更好地理解我们的模型在微调后如何改进,我们研究了音素错误的模式。我们首先比较了基础 ASR 模型在标准语音上所犯音素错误的分布和在 ALS 语音上所犯的错误。ALS数据和标准语音之间差异最大的五个SAMPA 音素是p、U、f、k和Z ,它们 占删除错误的 20%。同样,n和m音素加起来占插入/替换错误的 17%。 对我们微调模型进行的相同分析验证了未识别音素的分布与标准语音的分布更相似。
我们的分析表明,每个错误都有两个方面:系统不理解哪个音素,以及系统认为说出了哪个音素。想象一下有两个准确率相同的系统:一个系统总是认为f音素实际上是g音素,而另一个系统不知道f音素是什么,而是随机猜测。这两个系统的性能和音素错误分布相同,但错误预测音素的分布却大不相同。令人惊讶的是,经过 Euphonia 微调后,ALS 语音的 ASR 错误与常规语音错误更加相似。

微调前 ALS 语音、微调后 ALS 语音以及典型语音(Librispeech数据集)中每个SAMPA 音素的删除/替换错误。
未来工作
未来,我们打算探索在低数据条件下有用的其他技术。我们还希望使用音素错误来加权训练期间的某些示例,或者为 ALS 患者挑选包含最常见音素错误的训练句子进行记录。我们想探索从具有类似条件的多个说话者那里汇集数据。
我们希望继续研究这一领域将有助于语音界面为更多人所用,特别是那些最需要的人。这其中的一个关键要素是收集数据。任何 18 岁或以上的人都可以通过捐赠音频数据来帮助我们构建更好的个性化模型。如果您有兴趣,可以填写此表单以允许 Google 与您联系。
致谢
如果没有 ALS 治疗发展研究所和 ALS 社区的非凡努力和支持,这项工作不可能实现,尤其是 Fernando Vieira、Maeve McNally、Taylor Charbonneau、Melissa Nollstadt 以及善良耐心地自愿提供音频的 ALS 患者。这项工作以 Google 语音团队在语音识别领域取得的开创性进展为基础,特别是最近开发和部署的端到端语音识别模型。我们感谢 Google 语音团队的建议和合作,尤其是 Anshuman Tripathi 和 Hasim Sak 指导我们训练初始模型。我们还要感谢 Oran Lang、Omry Tuval、Michael Brenner、Julie Cattiau、Tara Sainath、Ding Zhao、Qiao Liang、Chung-Cheng Chiu、Dan Liebling、Ron Weiss、Anjuli Kannan、Dimitri Kanevsky、Ryan He、Gabor Simko、Benjamin Lee、Françoise Beaufays、Khe Chai Sim、Jimmy Tobin、Chet Gnegy、Jacqueline Huang、Ye Jia、Yu Zhang、Yonghui Wu、Michelle Ramanovich、Rus Heywood、Katrin Tomanek、Bob MacDonald、Pan-Pan Jiang、Ronnie Maor、Rif A. Saurous、Trevor Strohman、Dick Lyon、Avinatan Hassidim、Philip Nelson 和 Yossi Matias 的技术贡献和项目指导。
评论