感知手部形状和运动的能力是改善各种技术领域和平台上的用户体验的重要组成部分。例如,它可以作为手语理解和手势控制的基础,还可以在增强现实中将数字内容和信息叠加在物理世界之上。虽然对人们来说这是自然而然的事情,但强大的实时手部感知是一项极具挑战性的计算机视觉任务,因为手经常会遮挡自己或彼此(例如手指/手掌遮挡和握手)并且缺乏高对比度图案。
今天,我们宣布发布一种新的手部感知方法,我们在 6 月份的CVPR 2019中进行了预览,该方法在MediaPipe中实现- 一个开源跨平台框架,用于构建管道来处理不同模态(例如视频和音频)的感知数据。该方法通过使用机器学习 (ML) 从单个帧中推断出手部的 21 个 3D 关键点,从而提供高保真的手部和手指跟踪。目前最先进的方法主要依赖强大的桌面环境进行推理,而我们的方法在手机上实现了实时性能,甚至可以扩展到多只手。我们希望将这种手部感知功能提供给更广泛的研发社区,从而催生出创造性的用例,激发新的应用和新的研究途径。

通过MediaPipe在手机上实时实现 3D 手部感知。我们的解决方案使用机器学习从视频帧中计算手部的 21 个 3D 关键点。深度以灰度表示。
用于手部追踪和手势识别的 ML 管道
我们的手部追踪解决方案采用由多个协同工作的模型组成的 ML 管道:
手掌检测模型(称为 BlazePalm)对整幅图像进行操作并返回有方向的手部边界框。
手部关键点模型对手掌检测器定义的裁剪图像区域进行操作并返回高保真 3D 手部关键点。
手势识别器将先前计算的关键点配置分类为离散的手势集。
该架构与我们最近发布的面部网格 ML 管道 所采用的架构类似,其他人也将其用于姿势估计。将精确裁剪的手掌图像提供给手部标志模型可大大减少数据增强的需要(例如旋转、平移和缩放),而是允许网络将其大部分容量用于坐标预测准确性。
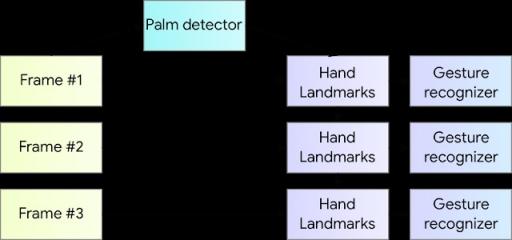
手部感知管道概述。
为了检测初始手部位置,我们采用了名为 BlazePalm 的单次检测模型,该模型针对移动实时使用进行了优化,方式类似于BlazeFace,后者也可在 MediaPipe 中使用。检测手部是一项非常复杂的任务:我们的模型必须能够处理各种大小的手部,相对于图像帧具有较大的尺度跨度(~20 倍),并且能够检测被遮挡和自遮挡的手部。虽然面部具有高对比度模式,例如在眼睛和嘴巴区域,但手部缺乏此类特征,因此仅从其视觉特征很难可靠地检测它们。相反,提供额外的背景信息(如手臂、身体或人物特征)有助于准确定位手部。
我们的解决方案使用不同的策略解决了上述挑战。首先,我们训练手掌检测器而不是手部检测器,因为估计手掌和拳头等刚性物体的边界框比检测带有关节手指的手部要简单得多。此外,由于手掌是较小的物体,非最大值抑制算法即使对于握手等双手自遮挡情况也能很好地工作。此外,可以使用方形边界框( ML 术语中的锚点)来建模手掌,忽略其他长宽比,从而将锚点数量减少 3 到 5 倍。其次,编码器-解码器特征提取器用于更大的场景上下文感知,即使对于小物体也是如此(类似于RetinaNet方法)。最后,我们在训练期间最小化焦点损失,以支持由高尺度方差导致的大量锚点。
通过上述技术,我们在手掌检测中实现了95.7% 的平均精度。使用常规交叉熵损失并且不使用解码器只能得到 86.22% 的基线。
手部标志模型
在对整个图像进行手掌检测之后,我们随后的手部标志模型通过回归(即直接坐标预测)对检测到的手部区域内的 21 个 3D 手指关节坐标执行精确的关键点定位。该模型可以学习一致的内部手势表示,即使手部部分可见和自我遮挡也具有鲁棒性。
为了获得真实数据,我们手动注释了约 30K 张真实世界图像,其中包含 21 个 3D 坐标,如下所示(如果每个对应坐标存在 Z 值,我们会从图像深度图中获取 Z 值)。为了更好地覆盖可能的手势并对手部几何性质提供额外的监督,我们还在各种背景下渲染了高质量的合成手部模型,并将其映射到相应的 3D 坐标。

顶部:对齐的手部裁剪图传递到跟踪网络,并带有地面实况注释。底部:渲染的合成手部图像,带有地面实况注释
然而,纯合成数据很难推广到自然领域。为了解决这个问题,我们采用了混合训练模式。下图显示了高级模型训练图。
手部跟踪网络的混合训练方案。裁剪的真实世界照片和渲染的合成图像被用作输入来预测 21 个 3D 关键点。

下表总结了根据训练数据性质得出的回归准确率。使用合成数据和真实数据可显著提高性能。
平均回归误差
数据集 按手掌大小标准化
仅限现实世界 16.1%
仅渲染合成 25.7%
混合现实世界 + 合成世界 13.4%
手势识别
在预测的手部骨架之上,我们应用一种简单的算法来推导手势。首先,通过累积的关节角度确定每个手指的状态(例如弯曲或伸直)。然后,我们将一组手指状态映射到一组预定义的手势。这种简单而有效的技术使我们能够以合理的质量估计基本的静态手势。现有的管道支持计数来自多种文化的手势,例如美国、欧洲和中国,以及各种手势,包括“竖起大拇指”、“握紧拳头”、“OK”、“摇滚”和“蜘蛛侠”。


通过 MediaPipe 实现
借助MediaPipe,可以将该感知管道构建为模块化组件(称为计算器)的有向图。Mediapipe 附带一组可扩展的计算器,用于解决各种设备和平台上的模型推理、媒体处理算法和数据转换等任务。裁剪、渲染和神经网络计算等单个计算器可以专门在 GPU 上执行。例如,我们在大多数现代手机上都使用TFLite GPU 推理
。 我们的 MediaPipe 手部跟踪图如下所示。该图由两个子图组成 - 一个用于手部检测,一个用于手部关键点(即标志)计算。MediaPipe 提供的一项关键优化是手掌检测器仅在必要时运行(相当不频繁),从而节省了大量的计算时间。我们通过从当前帧中计算的手部关键点推断后续视频帧中的手部位置来实现这一点,从而无需在每一帧上运行手掌检测器。为了实现稳健性,手部跟踪器模型输出一个额外的标量,以捕获手部在输入裁剪中存在并合理对齐的置信度。只有当置信度低于某个阈值时,手部检测模型才会重新应用于整个帧。
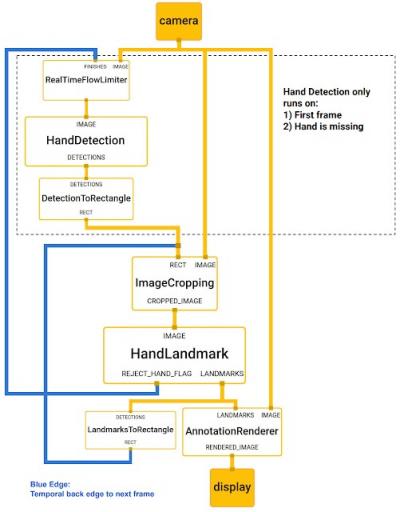
手部特征点模型的输出 (REJECT_HAND_FLAG) 控制何时触发手部检测模型。此行为由 MediaPipe 强大的同步构建块实现,从而实现高性能和最佳的 ML 管道吞吐量。
一种高效的 ML 解决方案,可以实时运行于各种不同的平台和形式因素,其复杂性远远超出上述简化描述的范围。为此,我们在这里开源了MediaPipe框架中的上述手部追踪和手势识别管道,并附带了相关的端到端使用场景和源代码。这为研究人员和开发人员提供了一个完整的堆栈,用于基于我们的模型进行新颖想法的实验和原型设计。未来方向 我们计划通过更稳健和稳定的追踪来扩展这项技术,增加我们可以可靠检测到的手势数量,并支持随时间展开的动态手势。我们相信,发布这项技术可以激发整个研究和开发者社区成员的新创意和应用。我们很高兴看到您可以用它构建什么!

致谢
特别感谢与我们一起致力于技术开发的所有团队成员:Andrey Vakunov、Andrei Tkachenka、Yury Kartynnik、Artsiom Ablavatski、Ivan Grishchenko、Kanstantsin Sokal、Buck Bourdon、Mogan Shieh、Ming Guan Yong、Anastasia Tkach、Jonathan Taylor、Sean Fanello、Sofien Bouaziz、Juhyun Lee、Chris McClanahan、Jiuqiang Tang、Esha Uboweja、Hadon Nash、Camillo Lugaresi、Michael Hays、Chuo-Ling Chang、Matsvei Zhdanovich 和 Matthias Grundmann。
评论